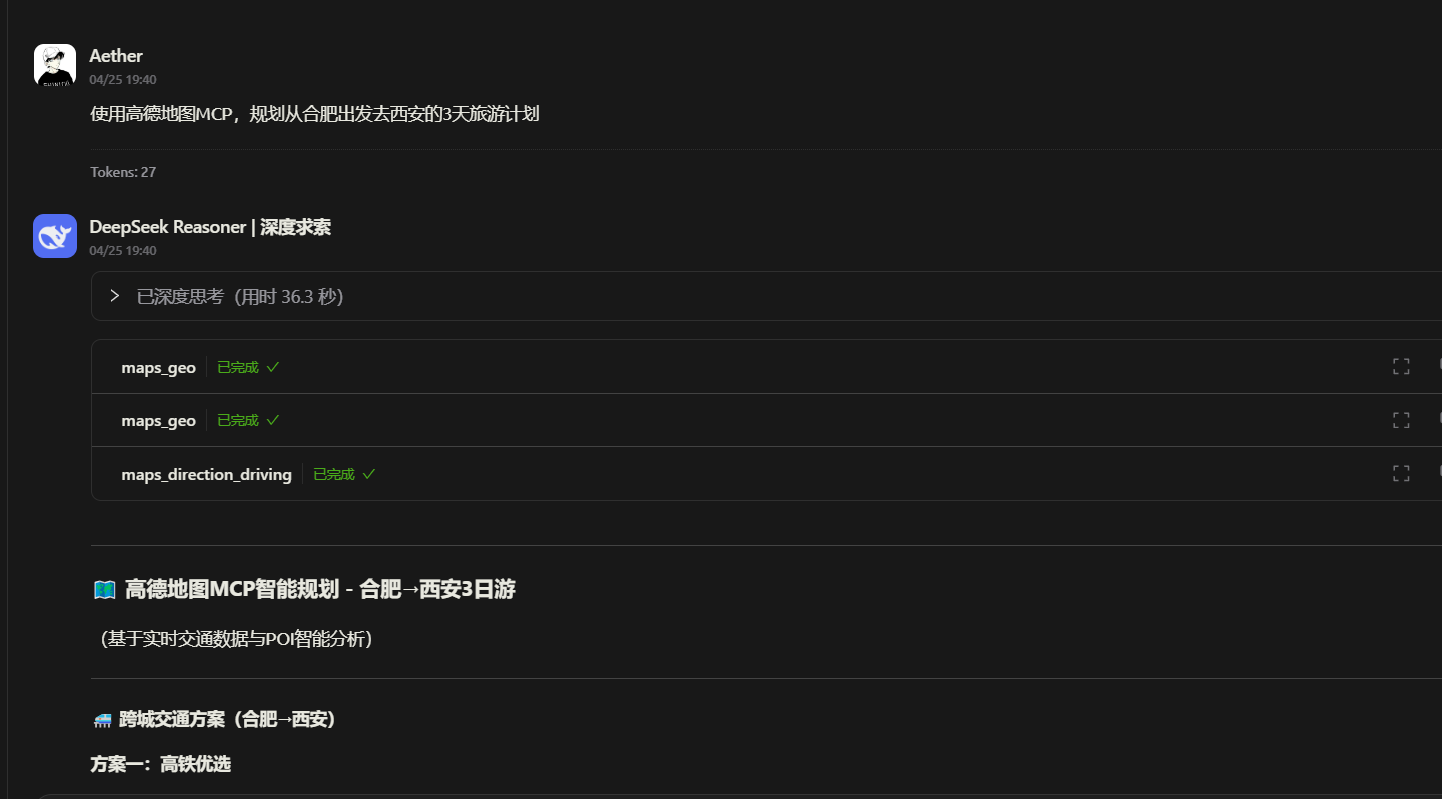
Stable Diffusion是一种深度学习模型,可以文字生图,拥有丰富的插件,具有较强的可控性,其中Web UI的界面更加直观,便于上手
秋叶整合包和部分模型:
链接: https://pan.baidu.com/s/1sDF36I4q5O7wh-eXwneXGA
提取码: i42g
lightCC:https://lightcc.cloud/
我的邀请码:96RMBN8U9380
土司:https://tusiart.com/
哩布哩布:https://www.liblib.art/
CIVITAI:https://www.civitai.com(需外网)
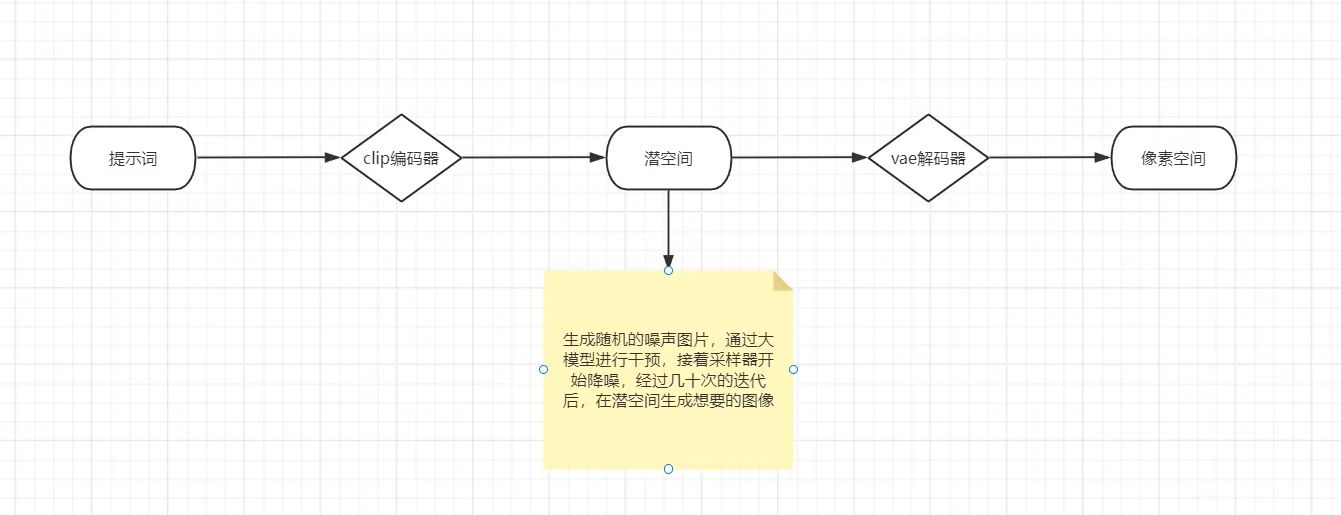
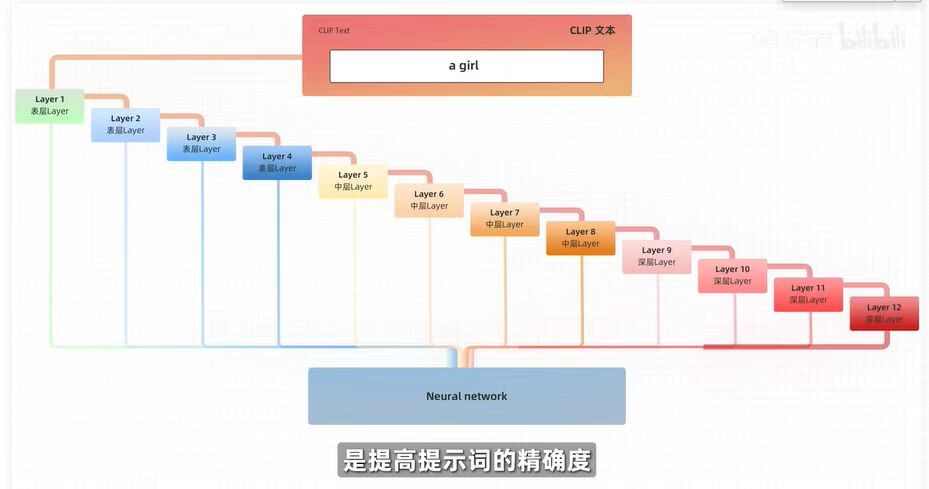
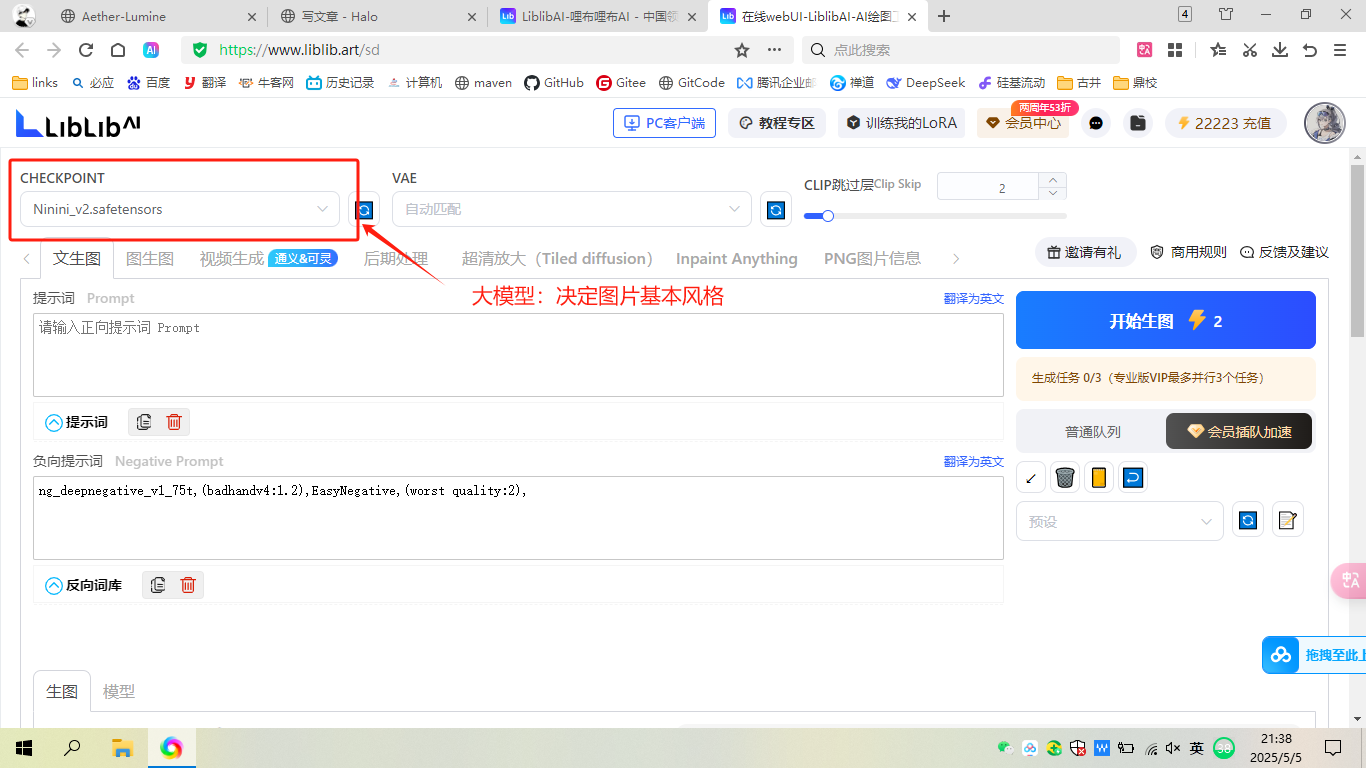
终止层越大,与提示词相关性越低,通常选择2终止层
大模型:Checkpoint
外挂vae模型:左边适合二次元,右边适合写实,可以不使用
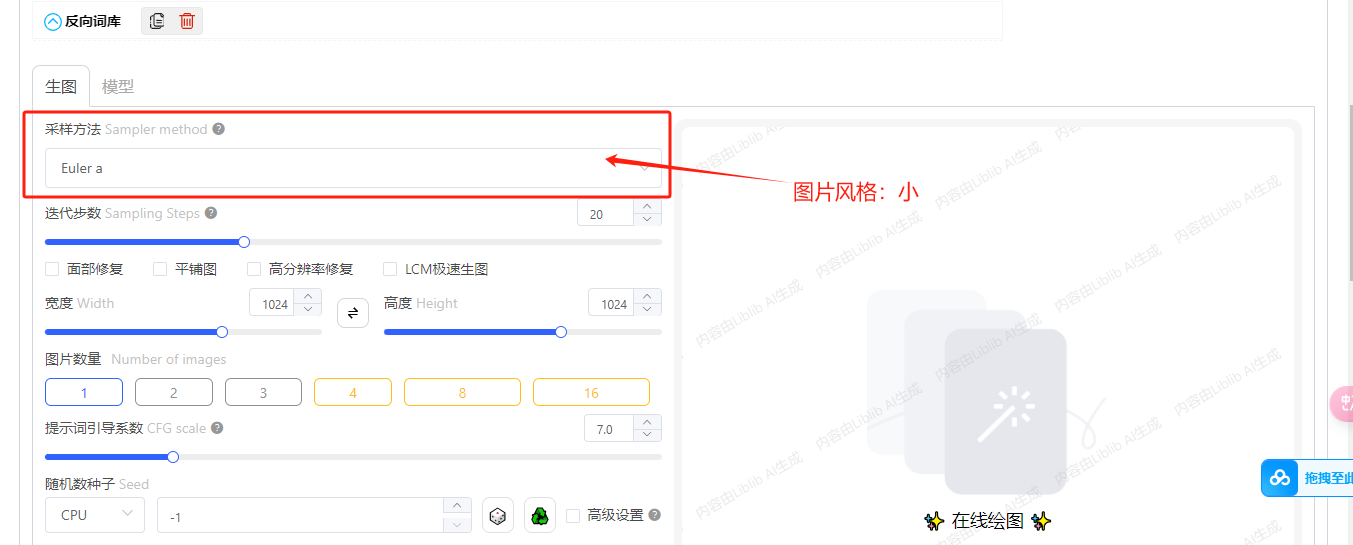
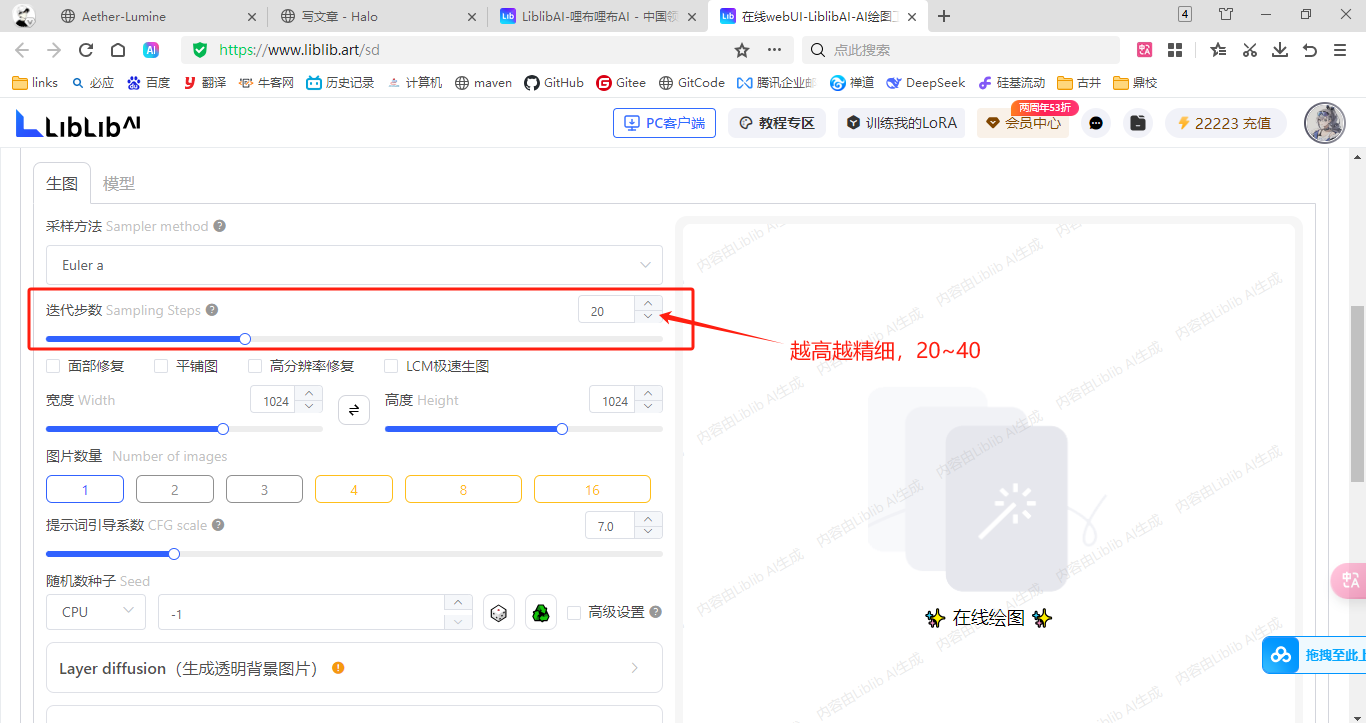
迭代步数:重复执行采样去噪的步数,超过一定步数后,质量不会明细提高
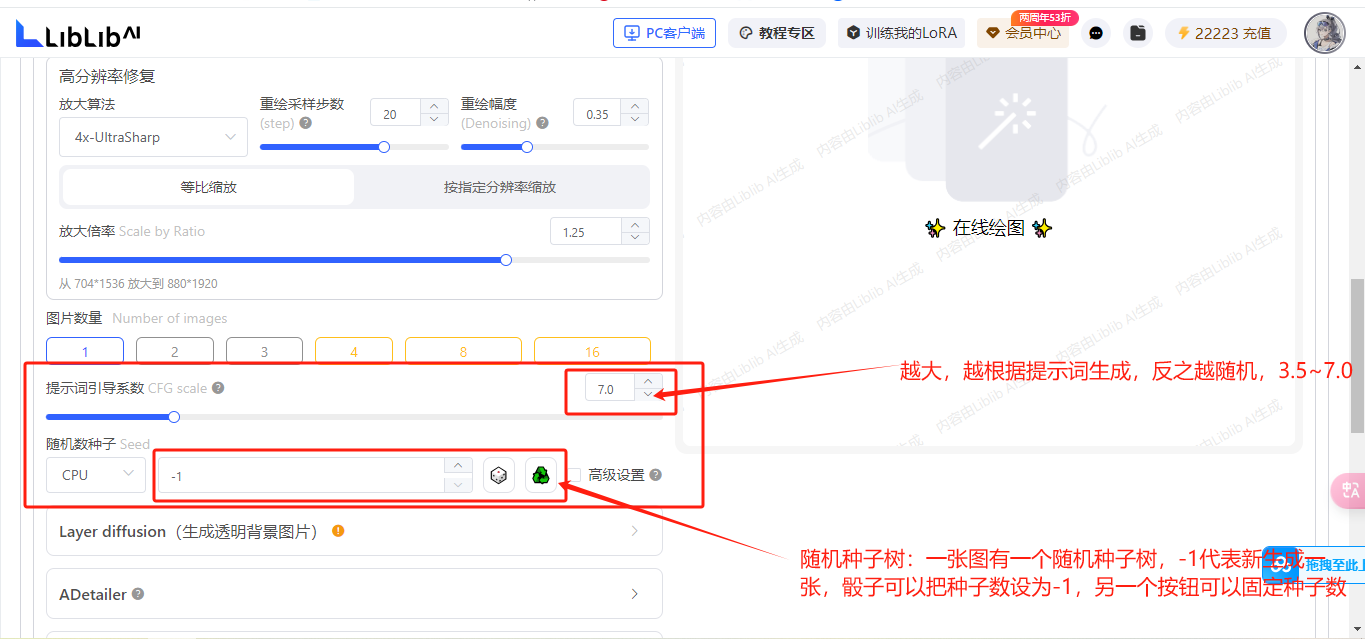
随机数种子:-1代表随机,每个图像的种子数是唯一的,可以固定种子值来对某一张图片进行调整
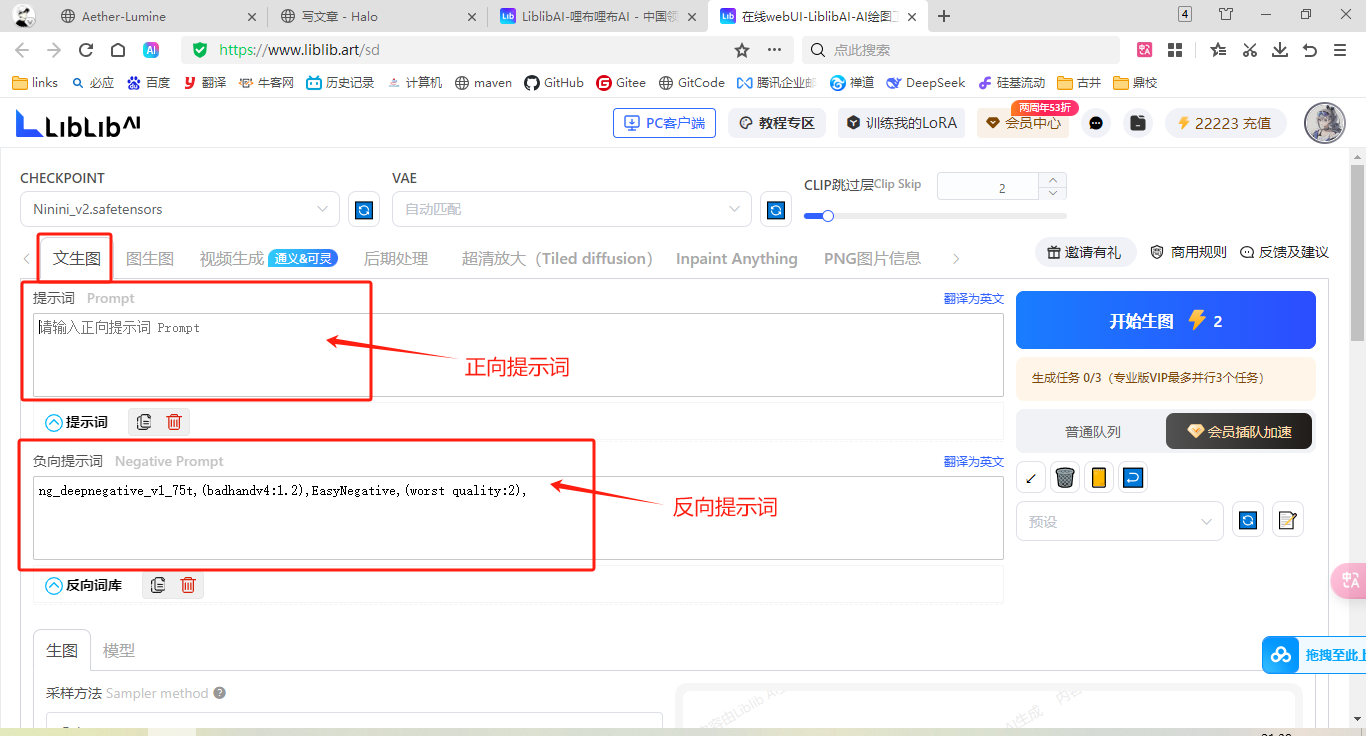
有本地和在线翻译,提示,历史记录,收藏,设置起手式等功能
会按提示词的顺序构建图片,一次只能理解75个token的词
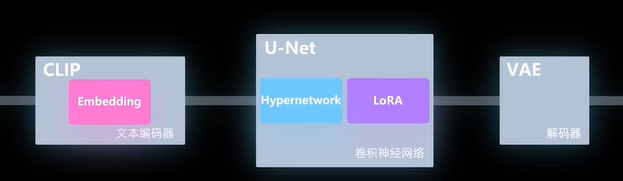
嵌入式
自带的几个反向模型:
提示词引导系数:建议4到15之间
超网络
需要触发词才能生效
低秩效应
有的需要触发词
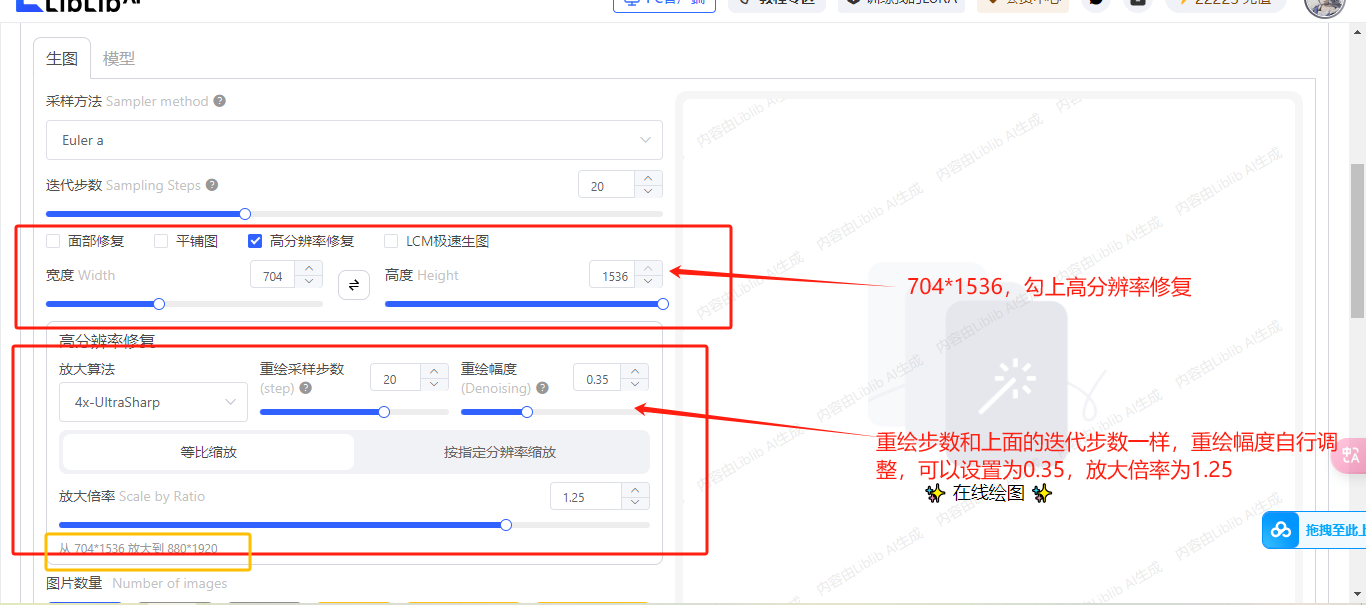
尺寸,缩放,重绘幅度(越小越依赖原图,越大越依赖提示词),反推参考图提示词插件
提高重绘幅度(依赖提示词和大模型的想象)
添加蒙版,选择合适的大模型(保证重绘部分和原图风格统一)
修改重绘幅度,重绘一次只修改一个部分的内容(多个内容会让大模型不知道改哪里而出错)
修改蒙版边缘模糊度(过大会增加模糊范围)
处理方式:原版(依原图作为参考)、填充(对蒙版进行模糊处理,再重新迭代生成)、潜空间噪声(在蒙版区域生成新的噪声),空白潜空间(在蒙版处填充纯色,重新生成图像)
重绘区域:决定哪些部分对蒙版区域的重绘产生影响,边缘预留像素对蒙版边缘以外的区域产生影响
重绘非蒙版:反转蒙版区域
柔和重绘:二次重绘,使蒙版边缘融合更好,参数:schedule bias(越大蒙版与参考图融合越强),preservation strength(越小生成内容越偏向大模型和提示词,越大越接近参考图)
有颜色选项和蒙版透明度(降低颜色蒙版的强度)
上传黑白图片作为蒙版
比如扩充图片时,可以使用ps裁剪扩充画布,蒙版图原图部分填充黑色。
上传扩充后的图片和蒙版图,选择原图的参数和大模型,删掉一些参数(比如扩充背景时,删除掉人物提示词),调整重绘幅度(到一个合适的数值才会生成新的内容,过大则和原图关联变小)
接缝问题(修改重绘区域,边缘模糊度,柔和重绘)
重绘部分可以用白色或简单手绘(PS)一下
PNG图片信息,参考图片的文件名和修改图片的文件名要一致
多张参考图需要裁剪成相同尺寸,PNG图片数量和文件名要与参考图一致
开启高分辨率,设置放大倍数,非常占用显存,设置2倍以上就可能出现显存不足的现象。所以可以使用图生图里的tiled diffusion插件,原理是将原图分割成小块分别扩充
参数设置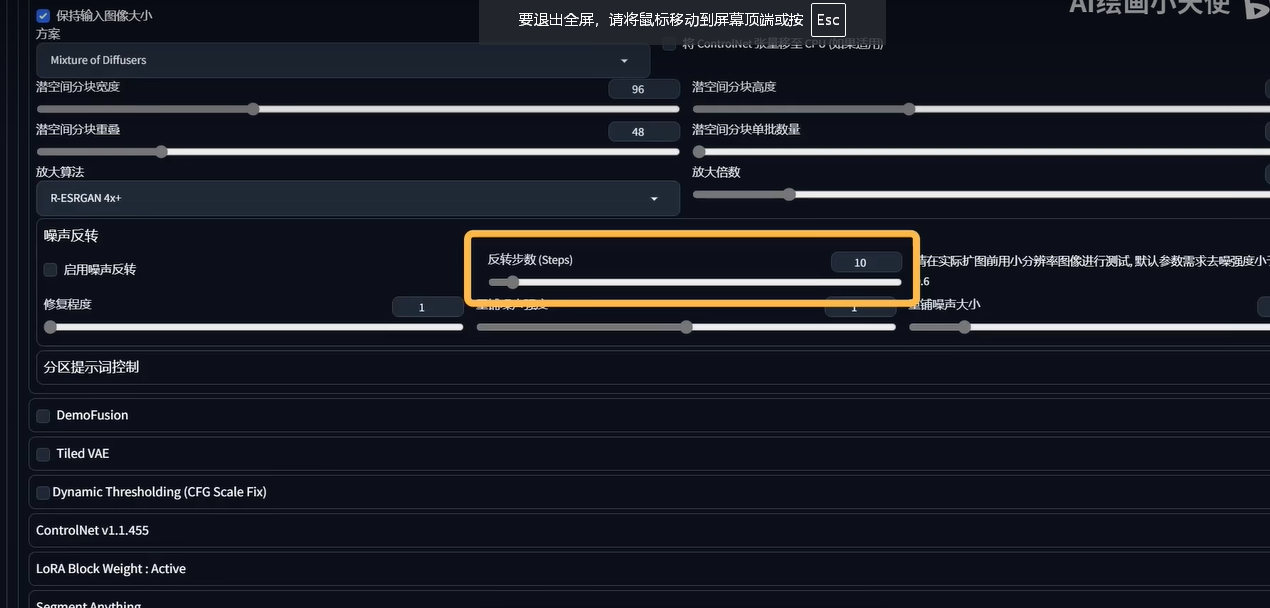
脚本放大
占用更小的显存,速度更快,效果较差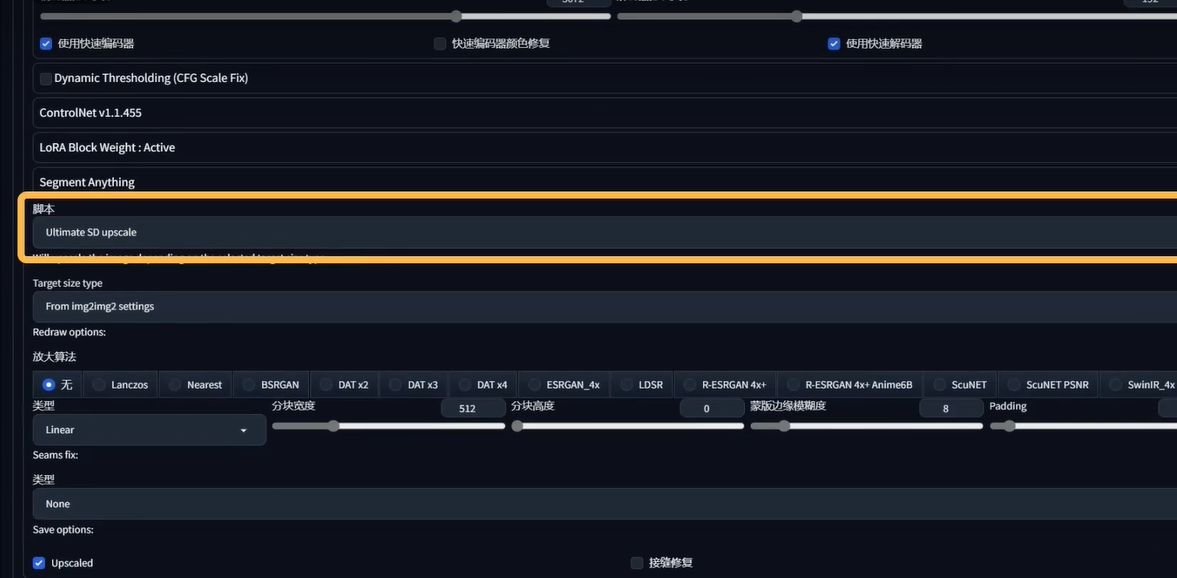
融合后的模型也会保存在文件夹中


快速查看之前生成的图片
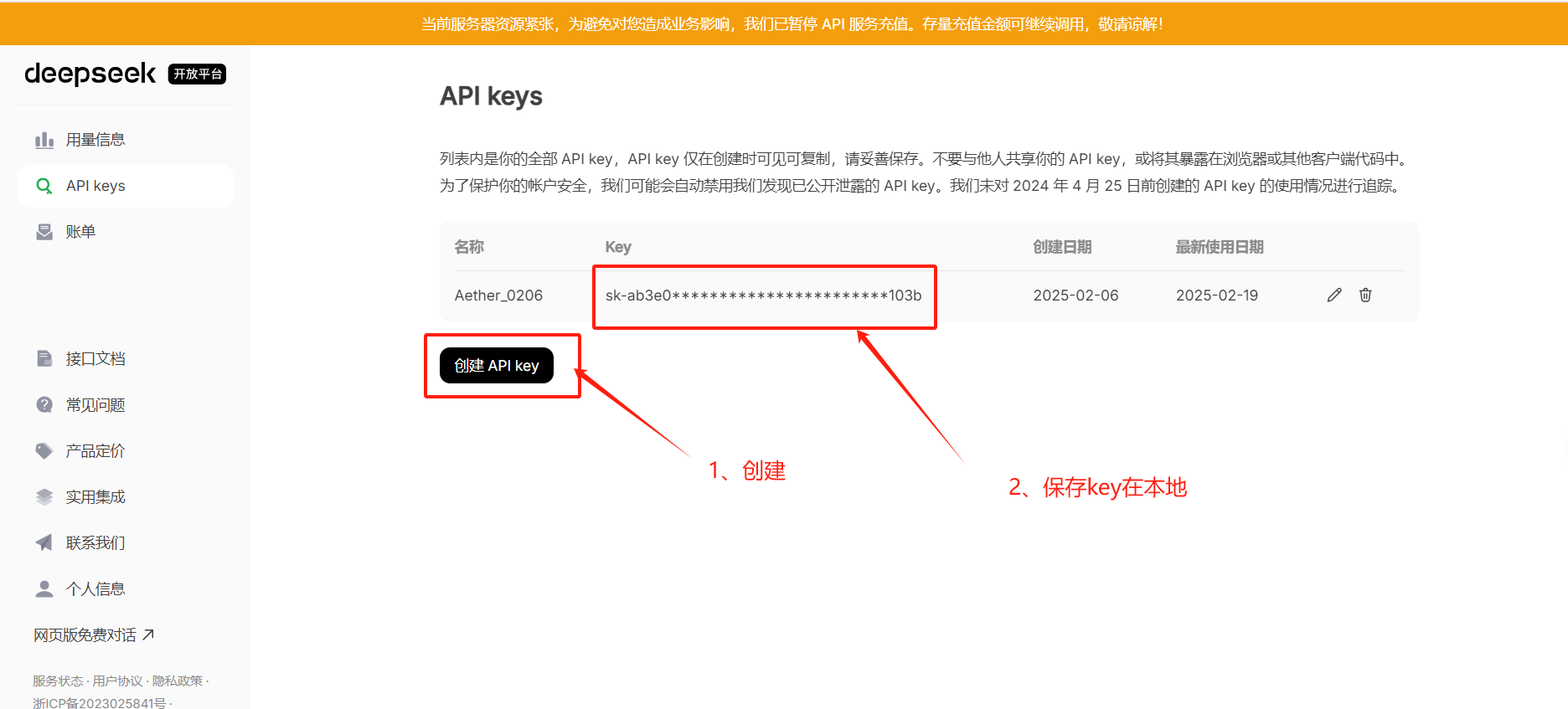
点击开放平台并注册账号

注册之后会免费赠送10元额度,有使用时间限制
点击创建API keys,创建一个API key,名称随便写,复制key的值并保存在本地文件(建议按WIN + V键开启历史剪贴板,方便查看历史剪贴内容)
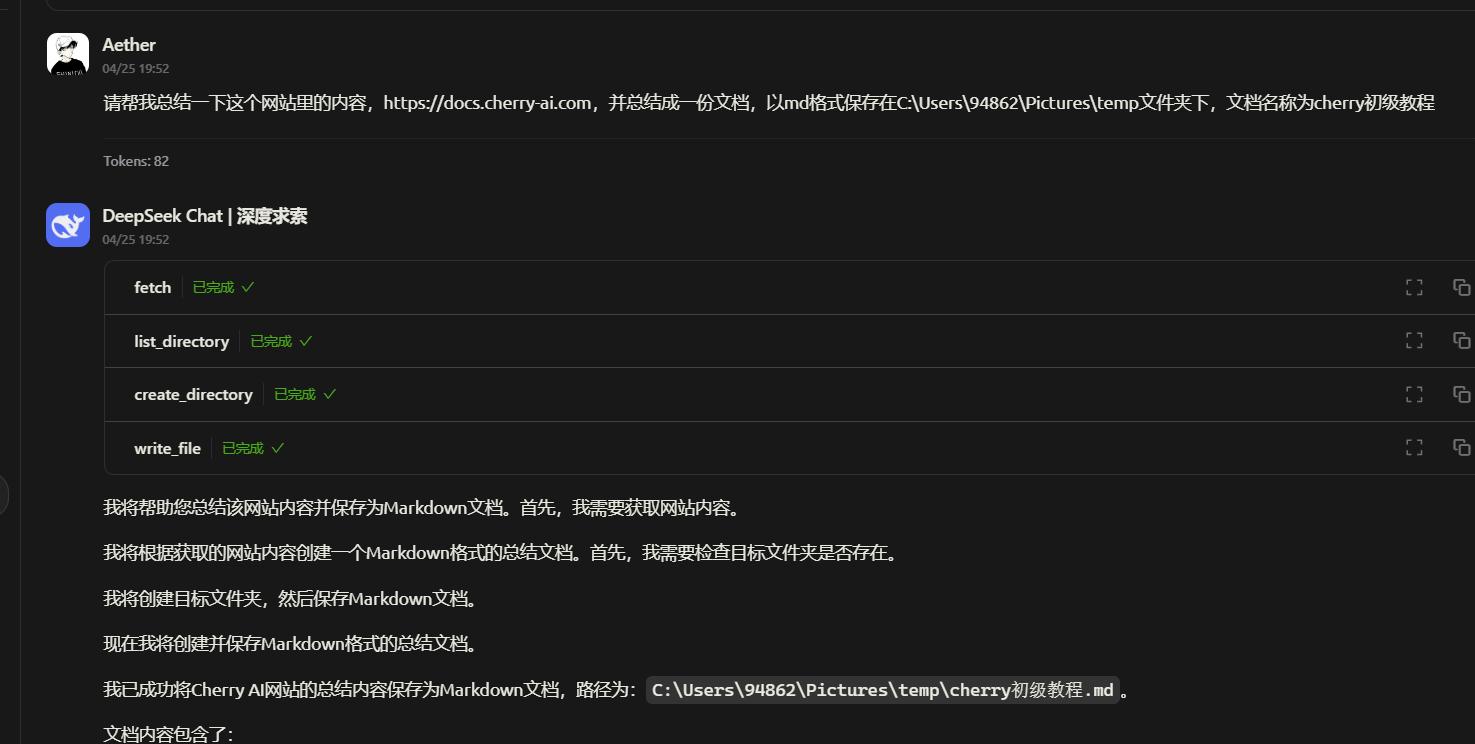
下载一个和AI对话的客户端,这里使用的是Cherry Studio,也可以选择其他相似功能的软件
下载地址:https://cherry-ai.com/download
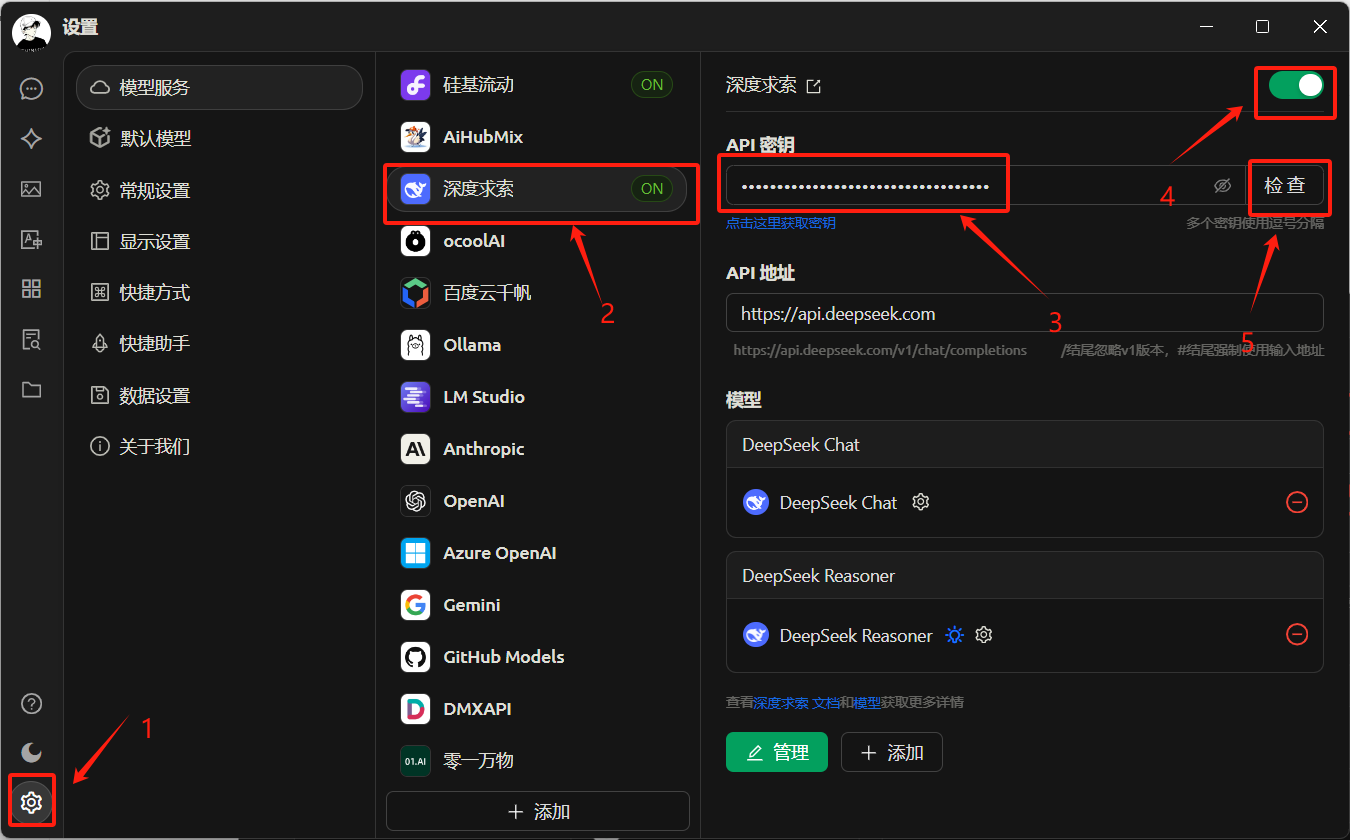
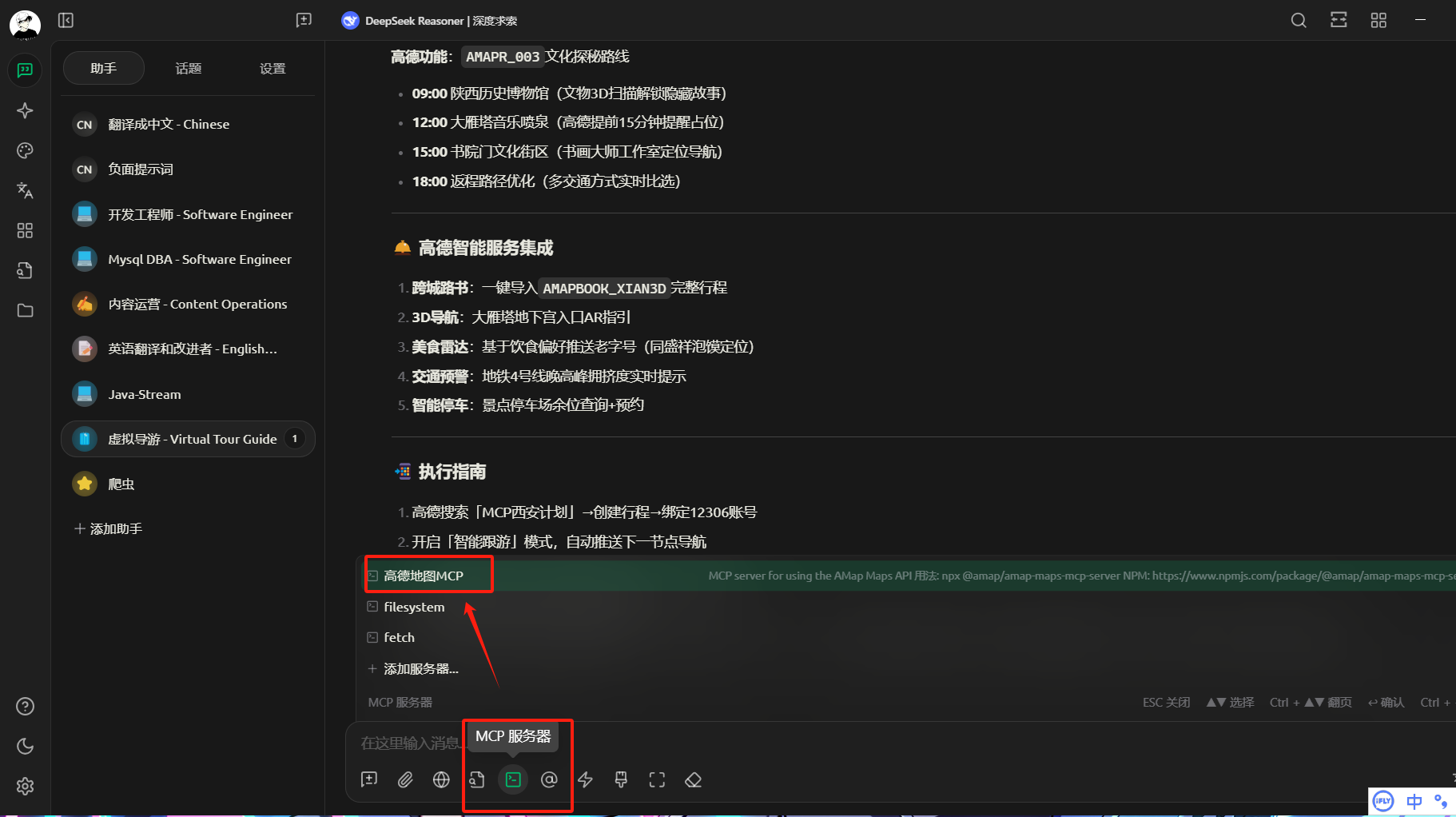
安装之后点设置,选择深度求索,将之前注册的API key粘贴进去,点击右上角开启按钮,(可以点击检查看看是否连接成功)
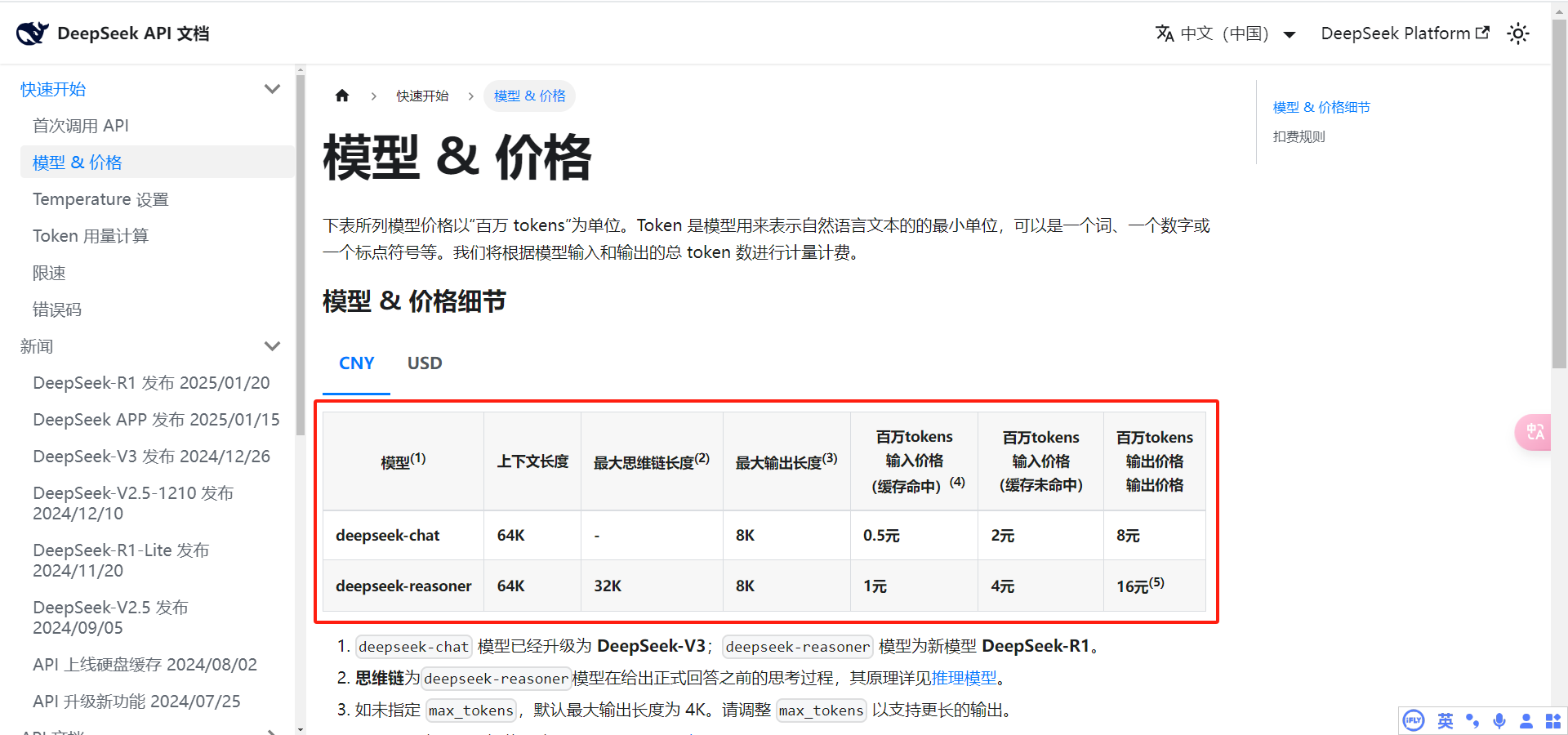
点击聊天按钮即可开始对话,上方可以选择模型,deepseek可以选择两种模型,价格可见官方文档:https://api-docs.deepseek.com/zh-cn/quick_start/pricing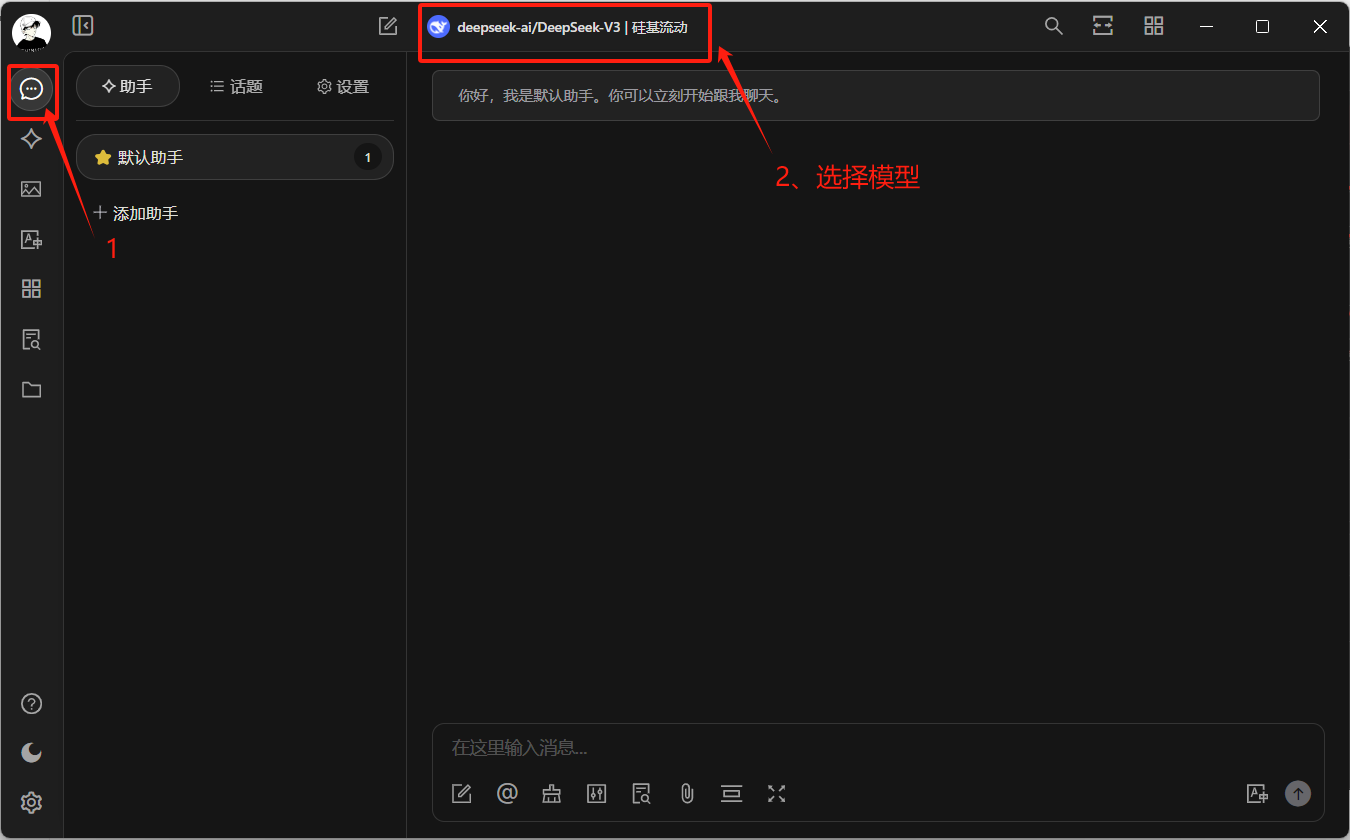
deepseek-chat是基础对话模型
deepseek-reasoner模型,即R1模型,是推理模型,进行了深度思考,并会给出思考过程
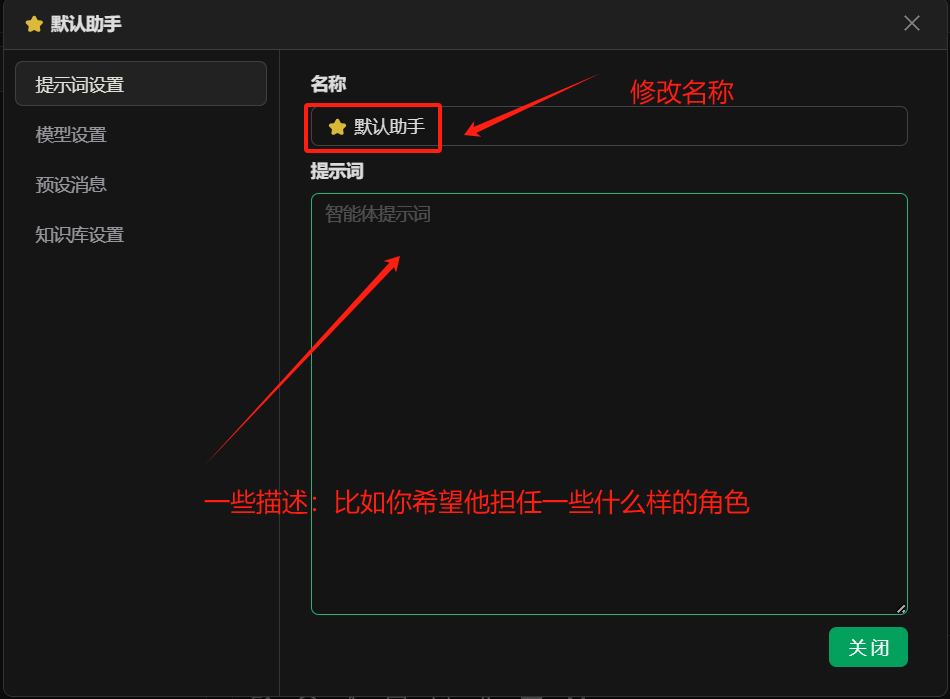
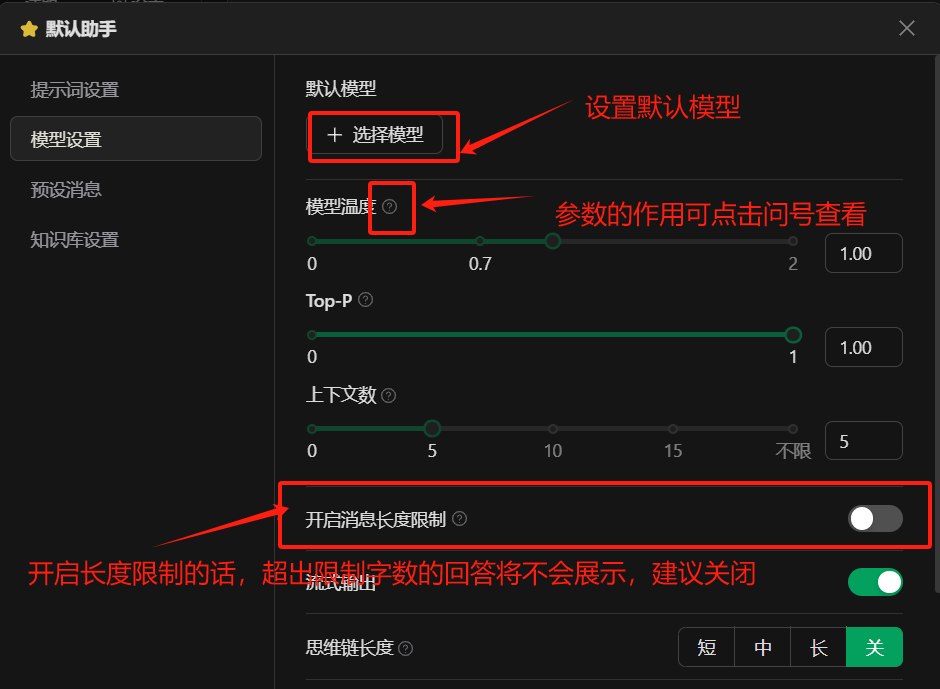
点击如图位置可以设置聊天助手的参数
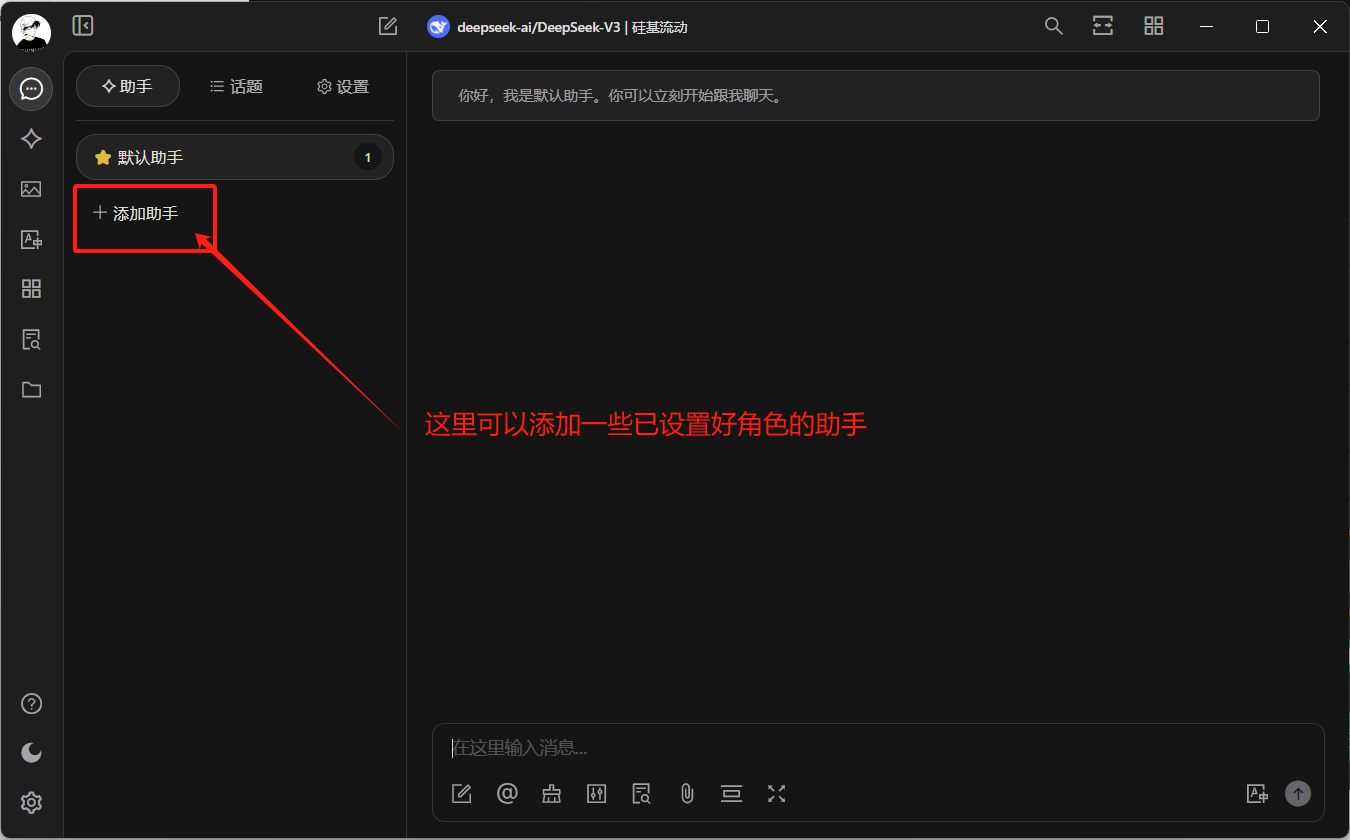
硅基流动提供了一些其他的模型,其中一部分是免费的,如下图点击进入官网
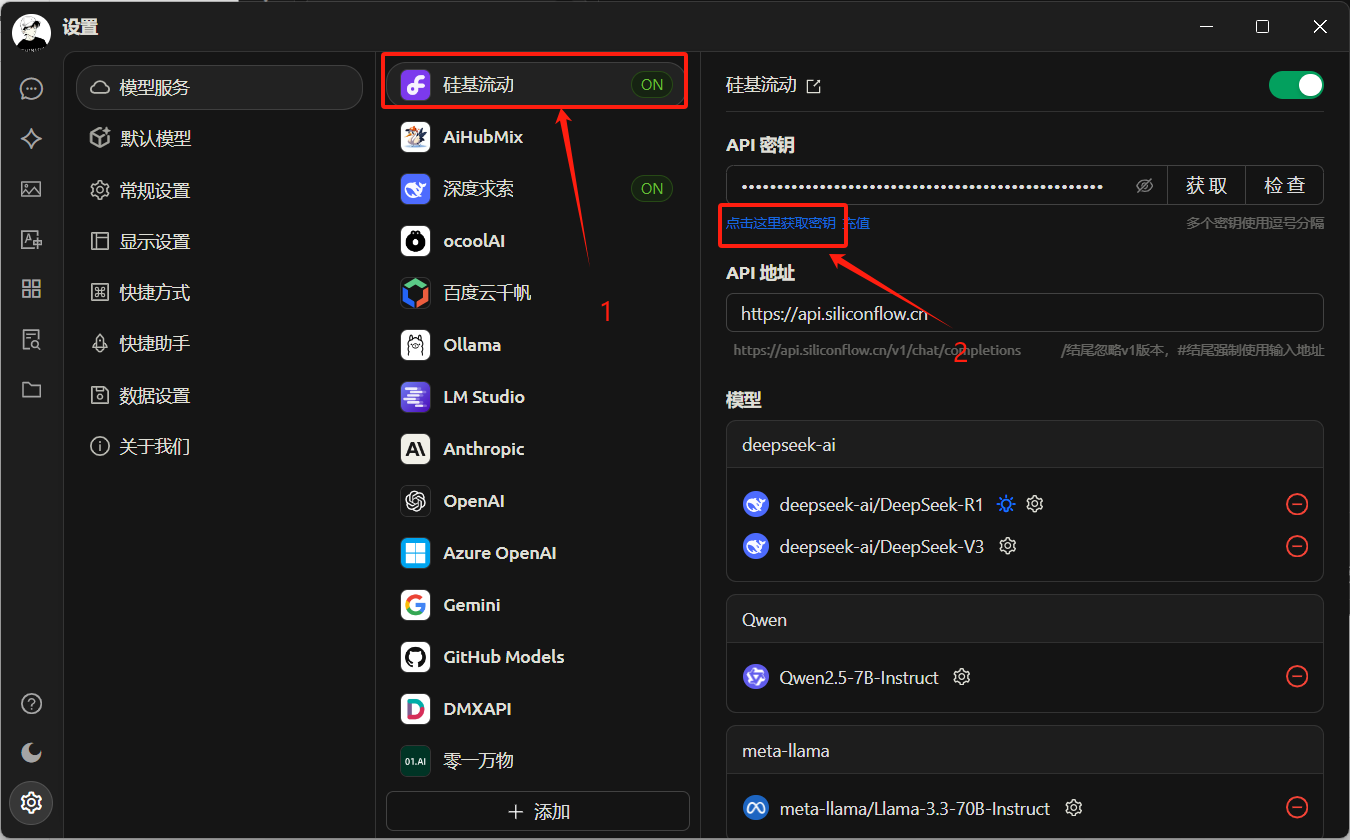
注册账号(邀请码填我的,可以给我加点余额:e5dPnLLl),注册后会赠送15元额度,在使用硅基流动的一些收费模型时使用,点击生成API密钥,复制粘贴到上图API密钥的位置,并点开右上角启动按钮
点击模型广场,选择想要的模型:
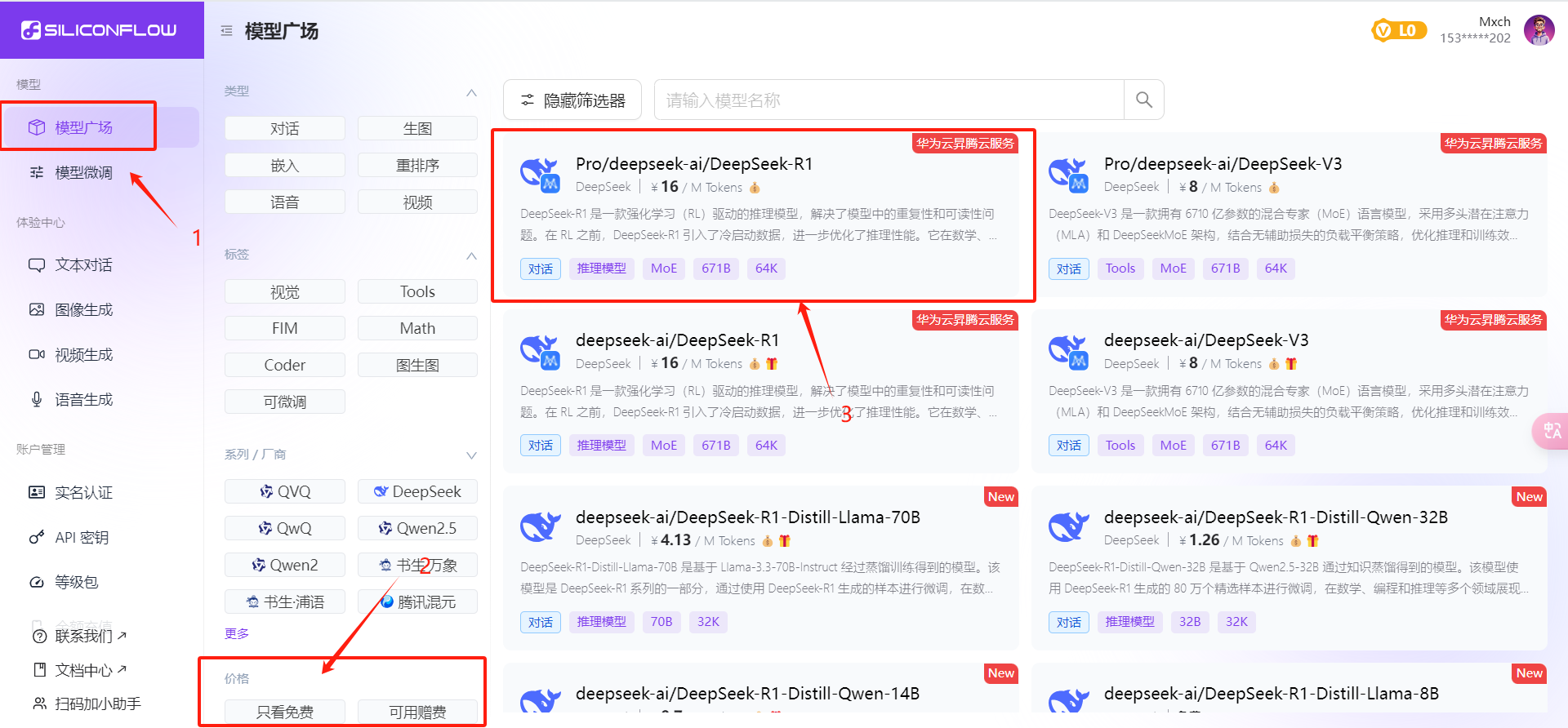
点开模型可查看收费标准,也可以进行筛选使用一些免费模型
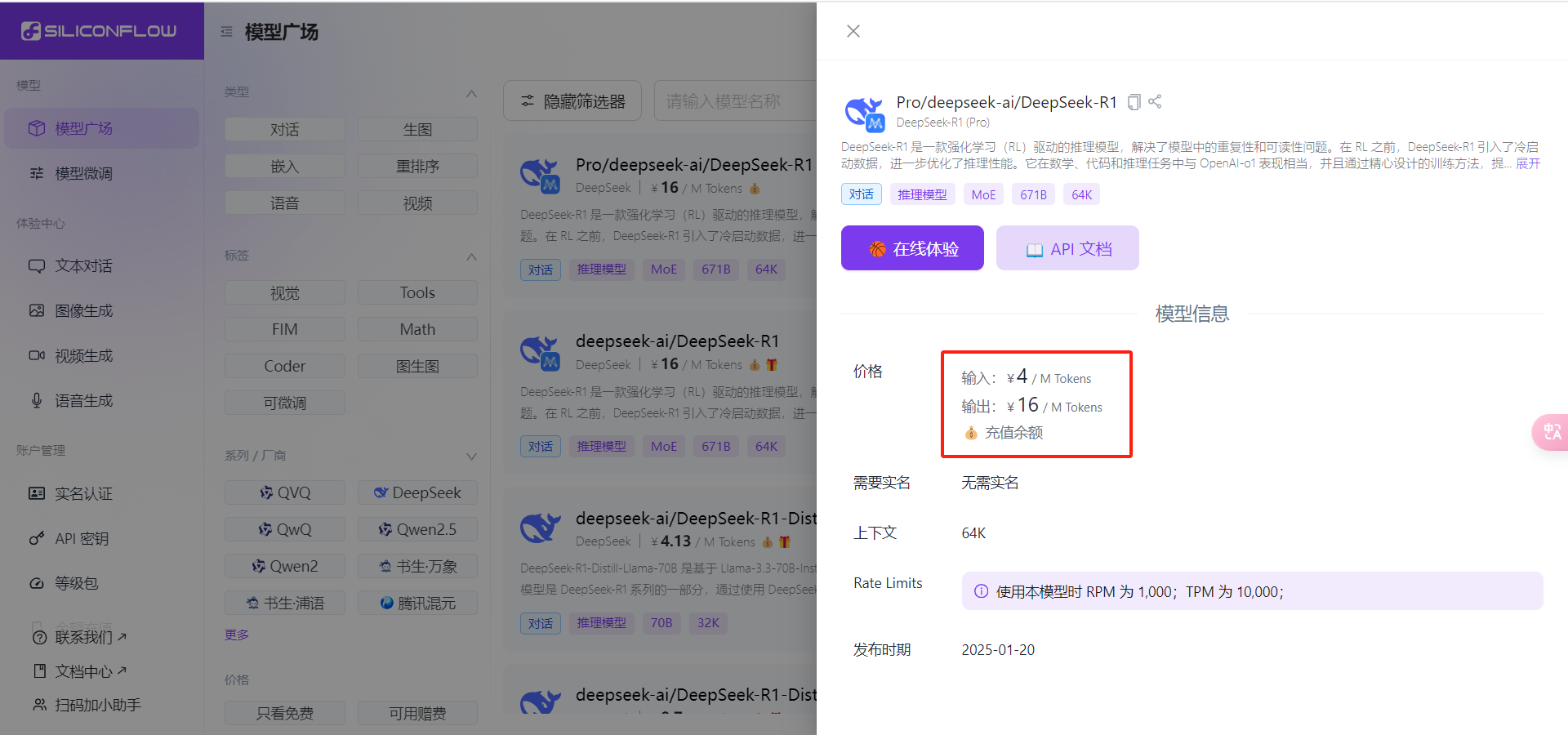
选择想要的模型之后,点击复制,把名称复制下来
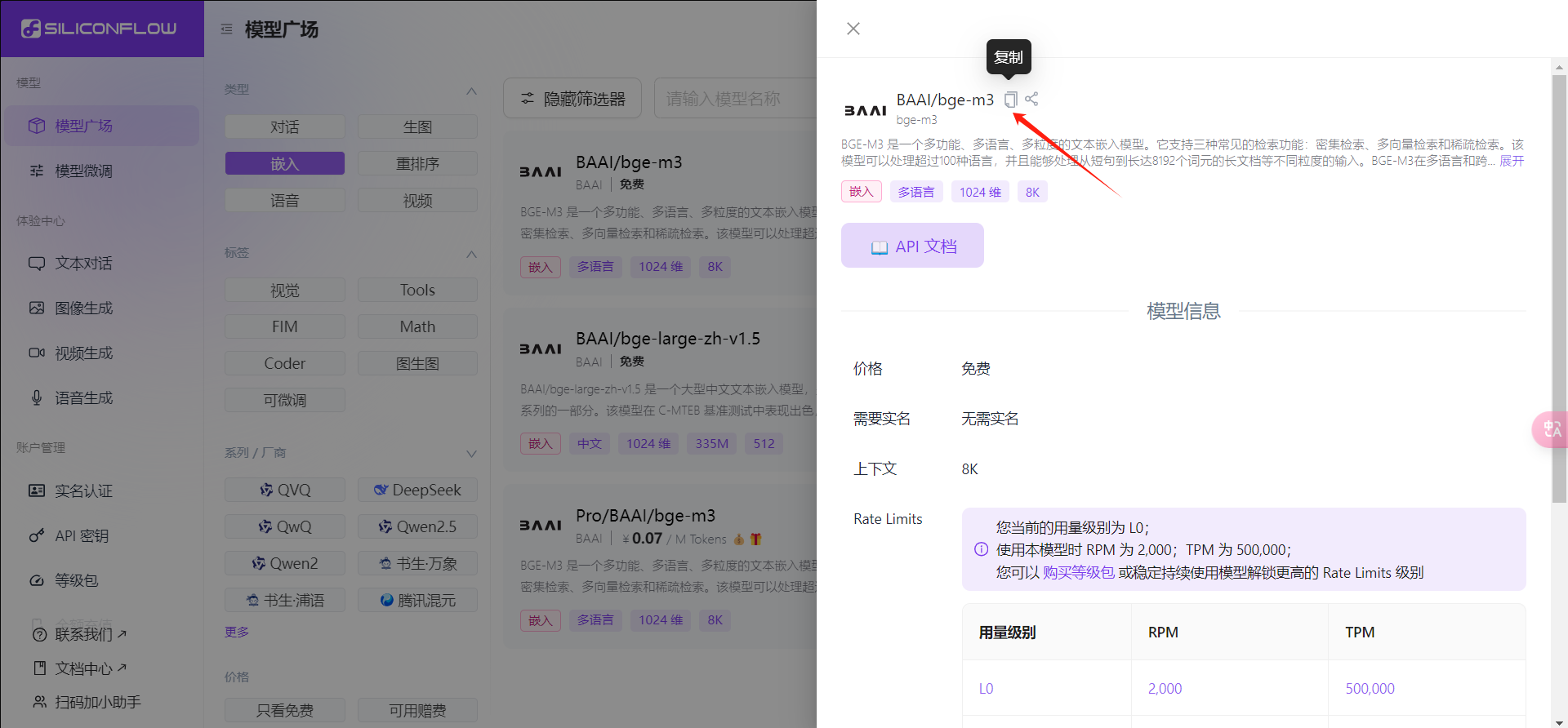
然后回到cherry studio,添加模型
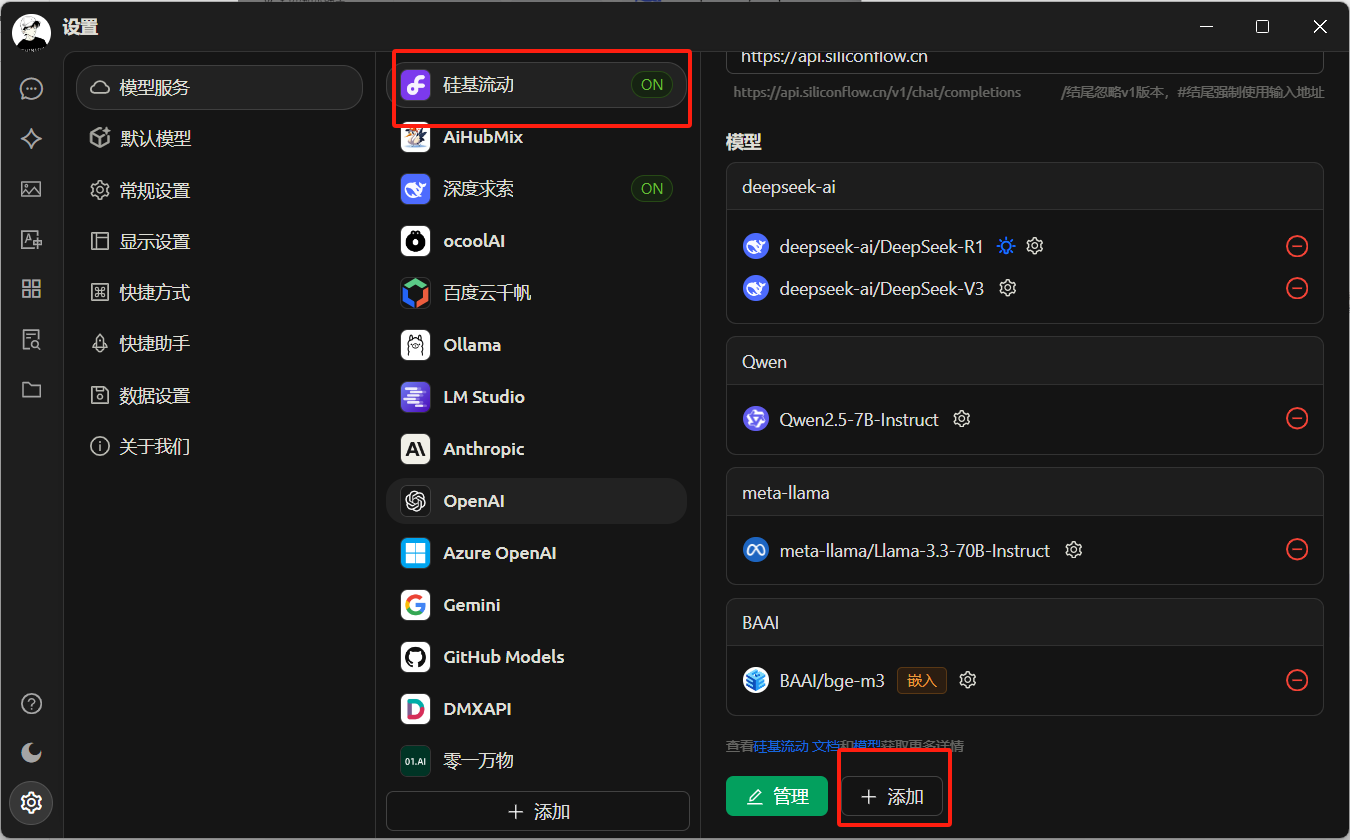
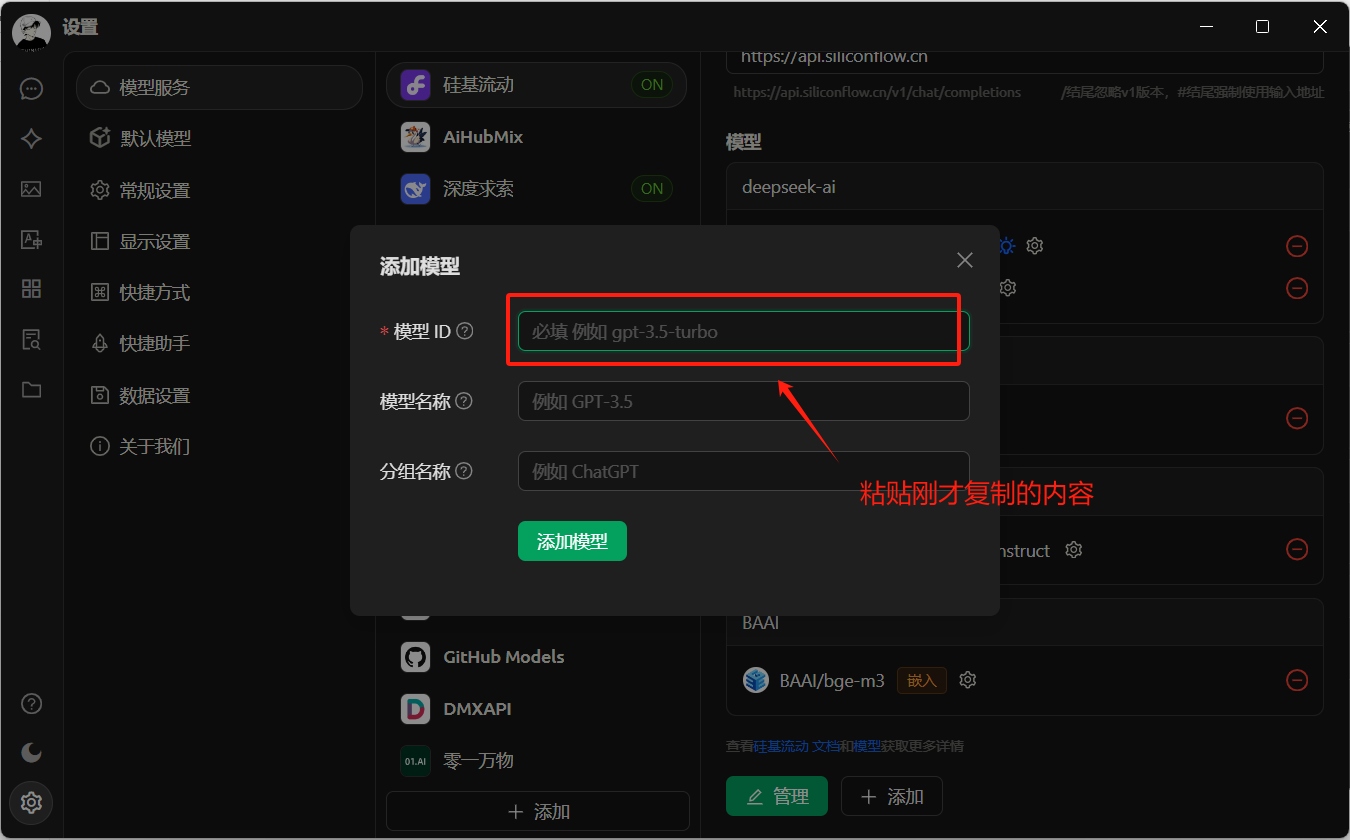
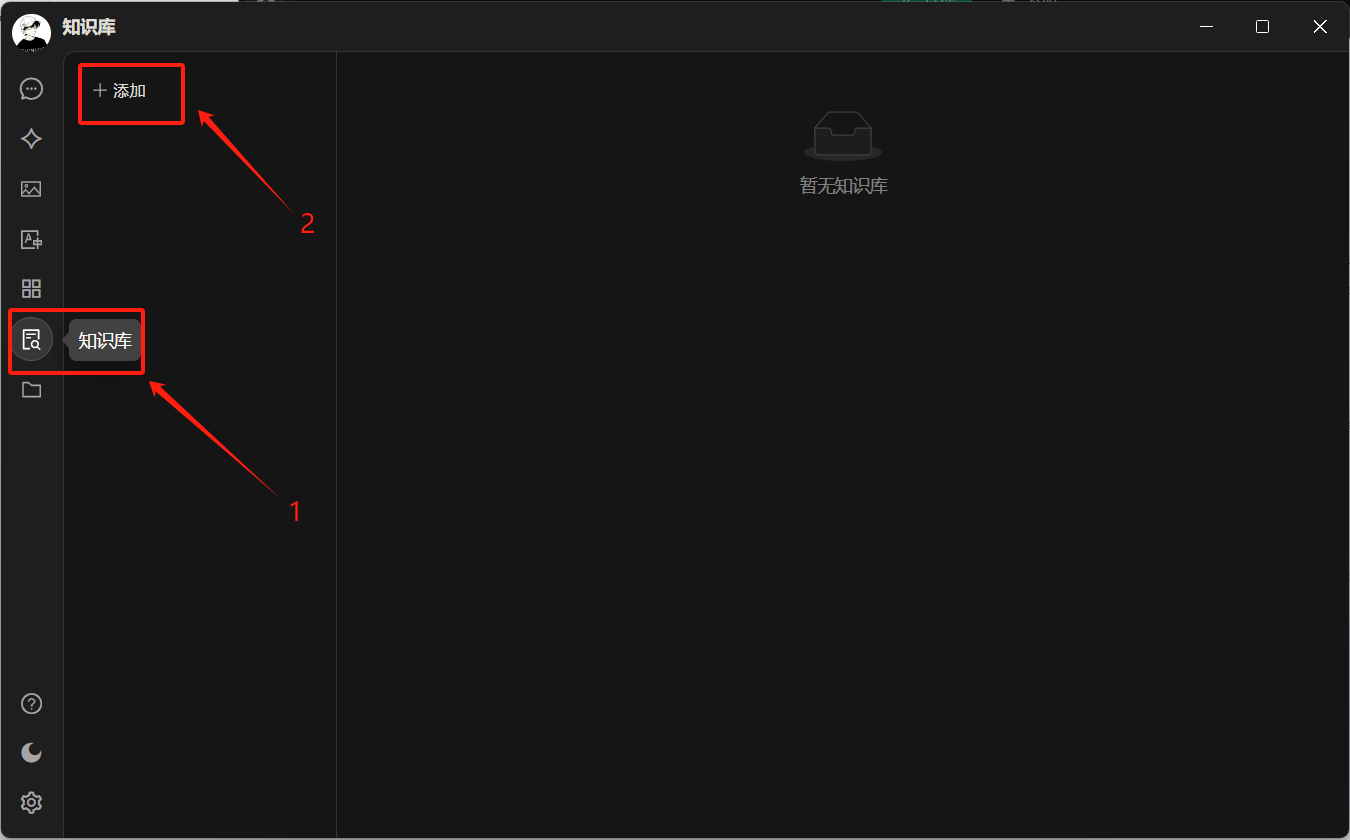
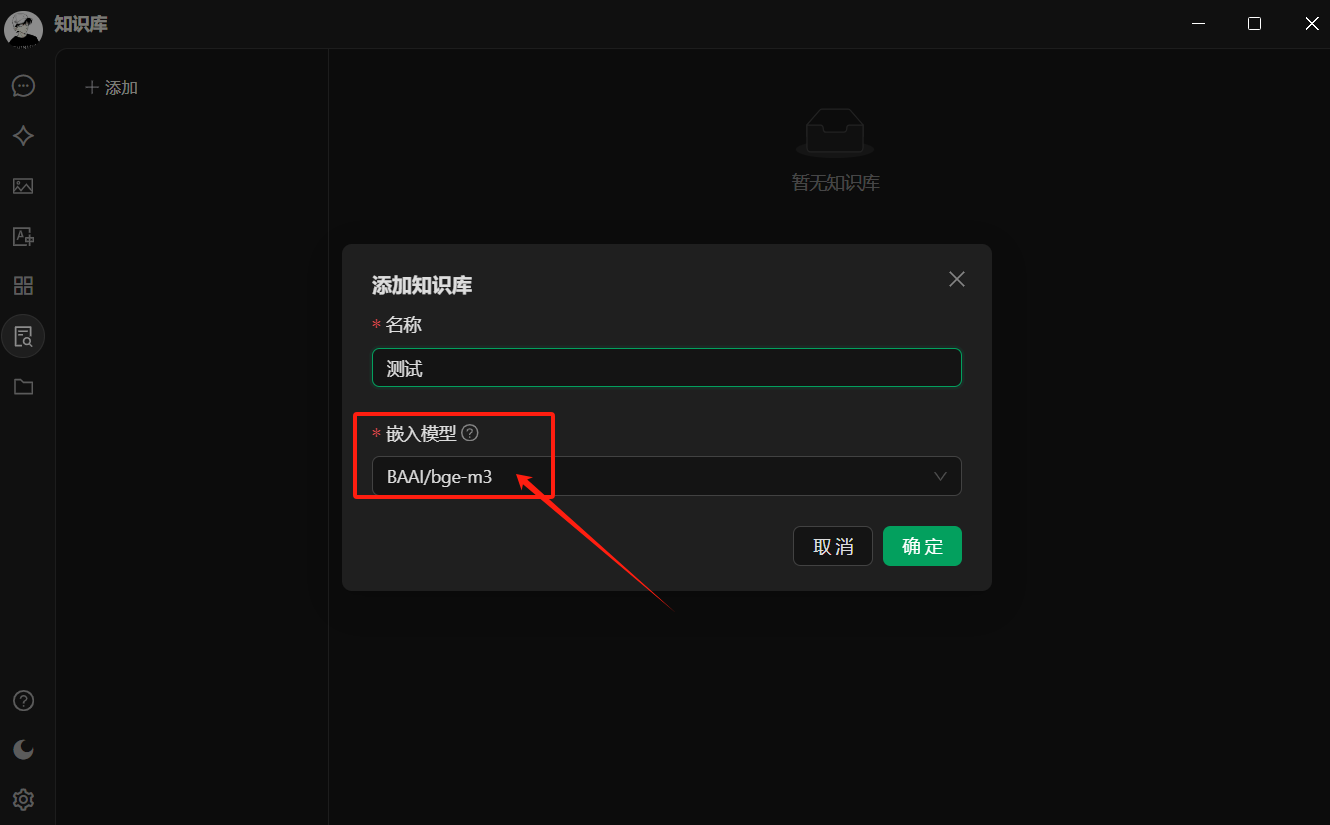
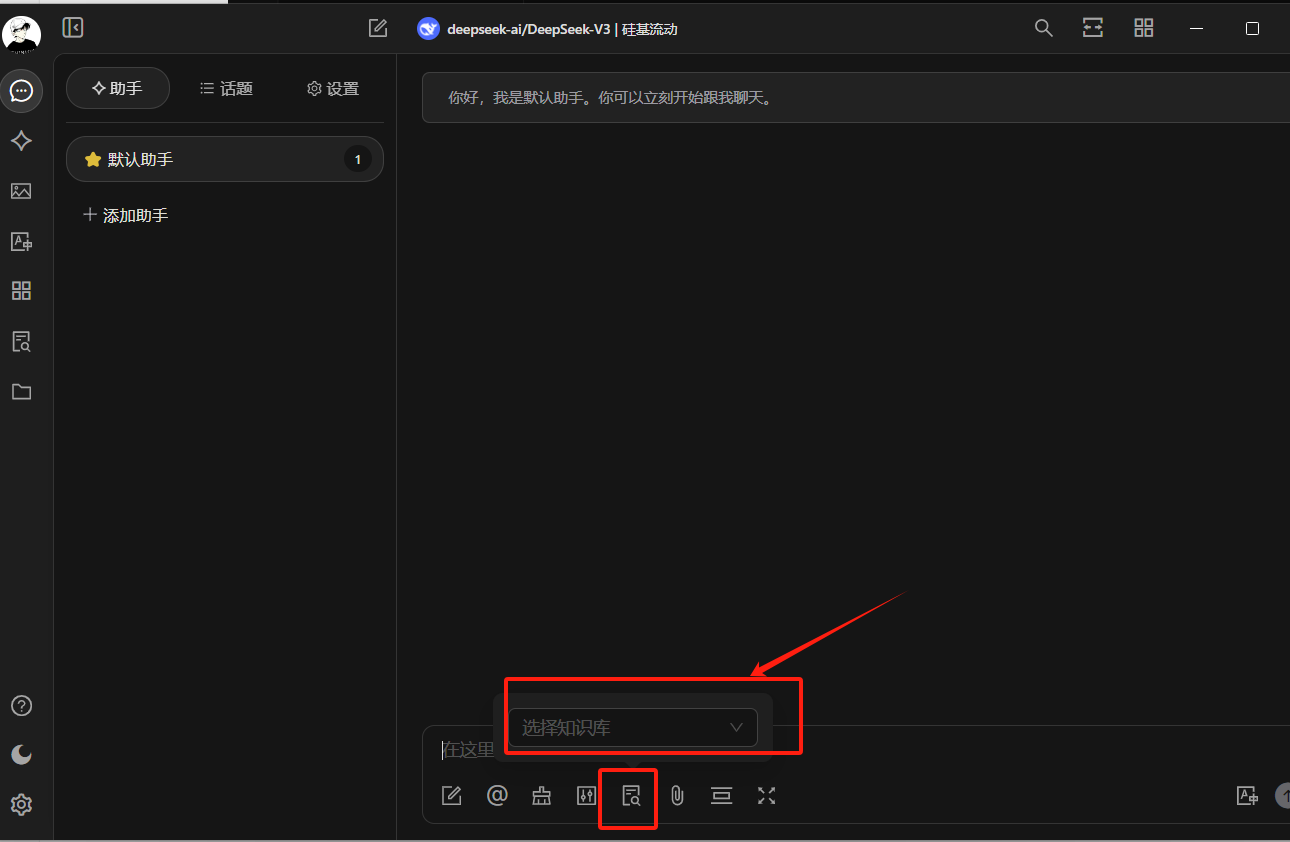
有时候我们需要一些自己知识库,这时候需要使用嵌入模型,可以在模型广场筛选,添加方式与上面一样
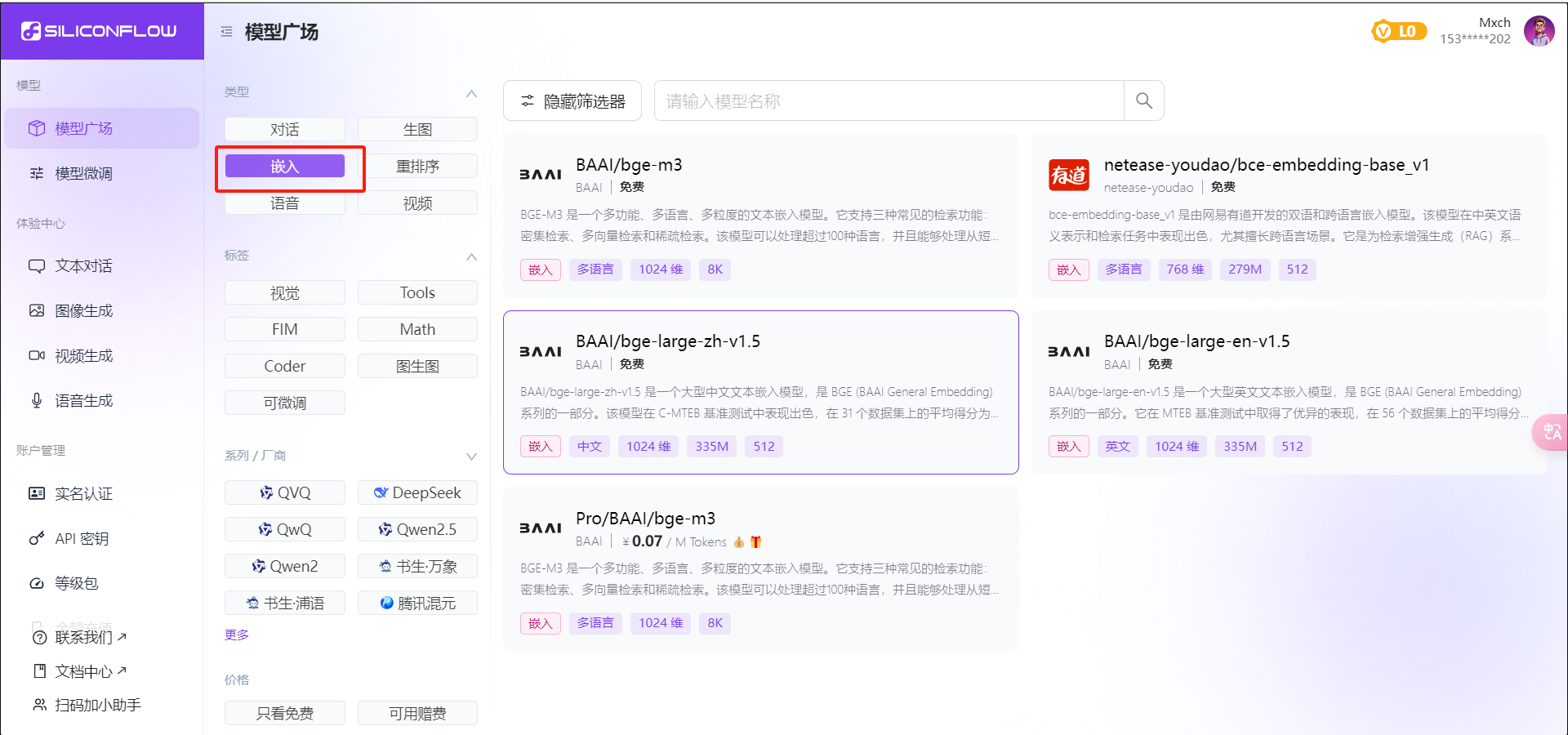
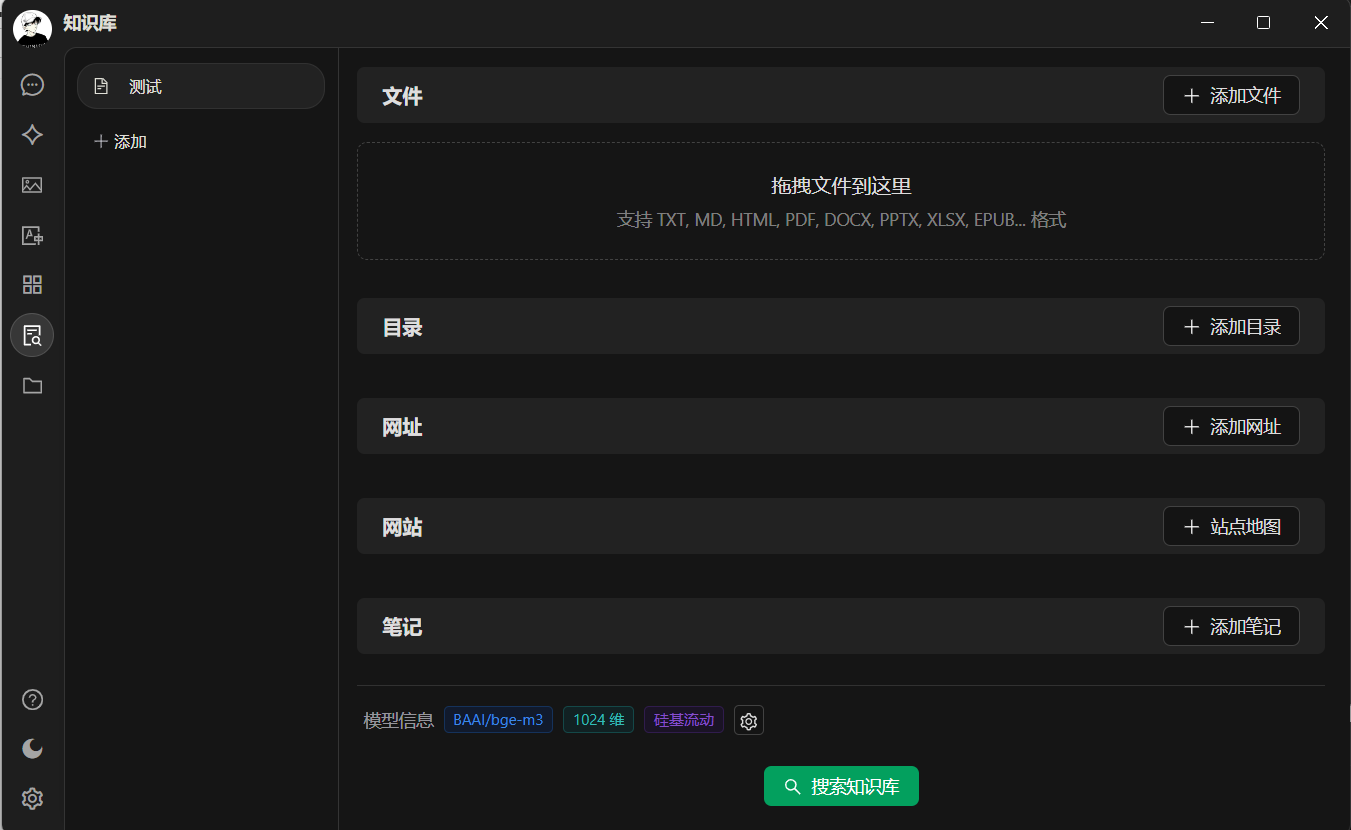
之后点击添加知识库,选择刚才的嵌入式模型,即可以添加一些本地文件,或者网站之类的。对话时应用上添加的知识库即可
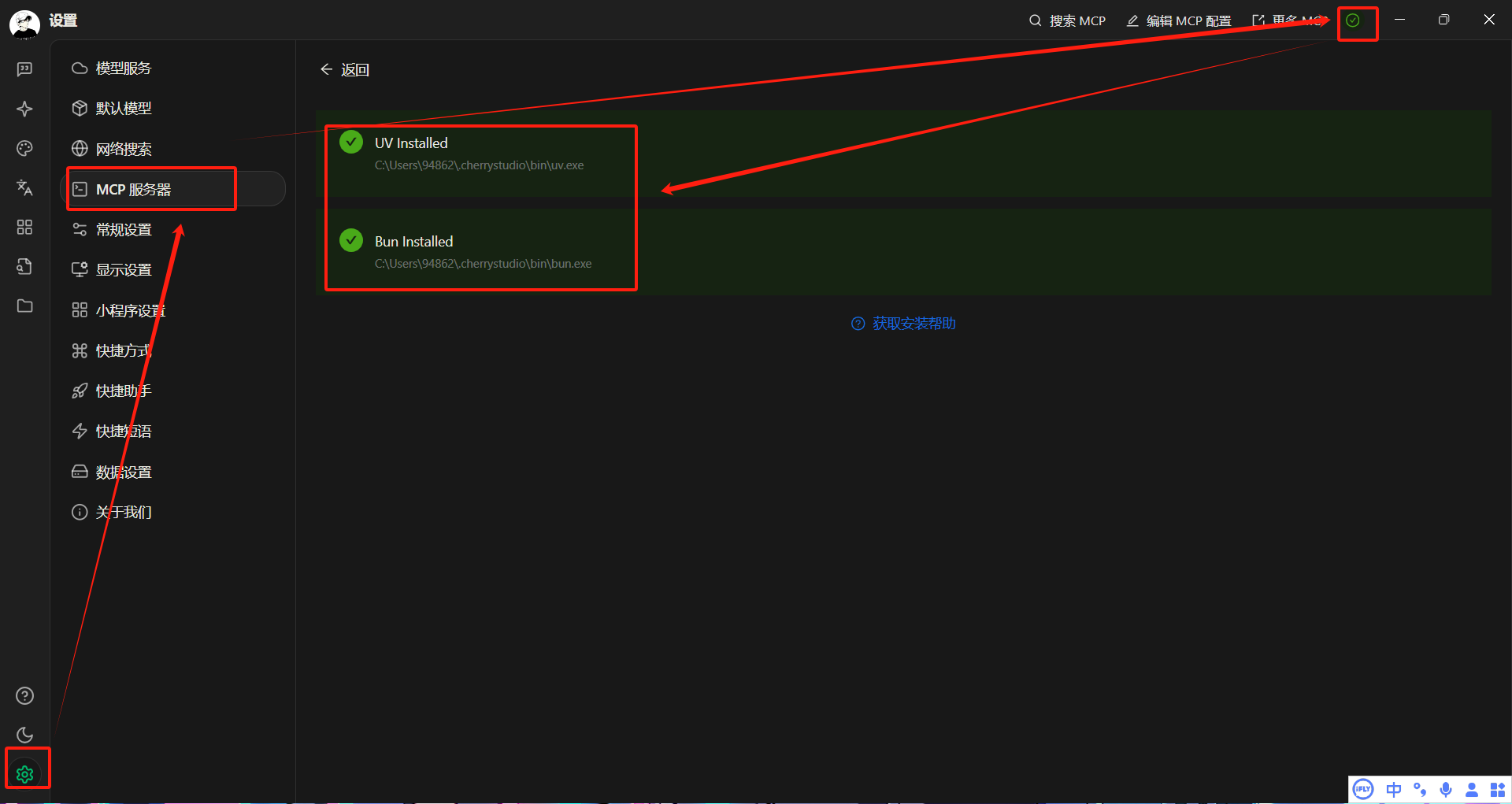
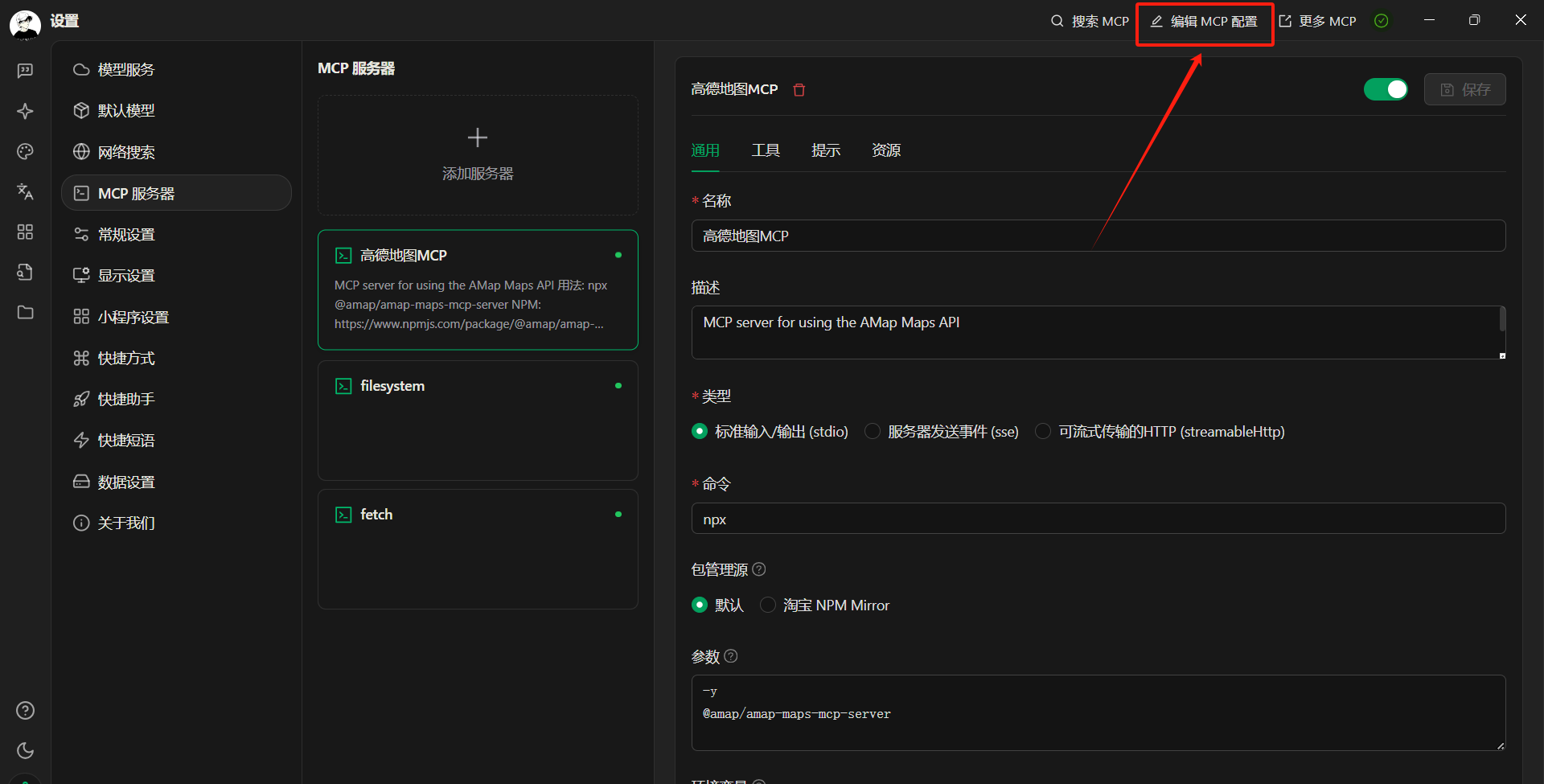
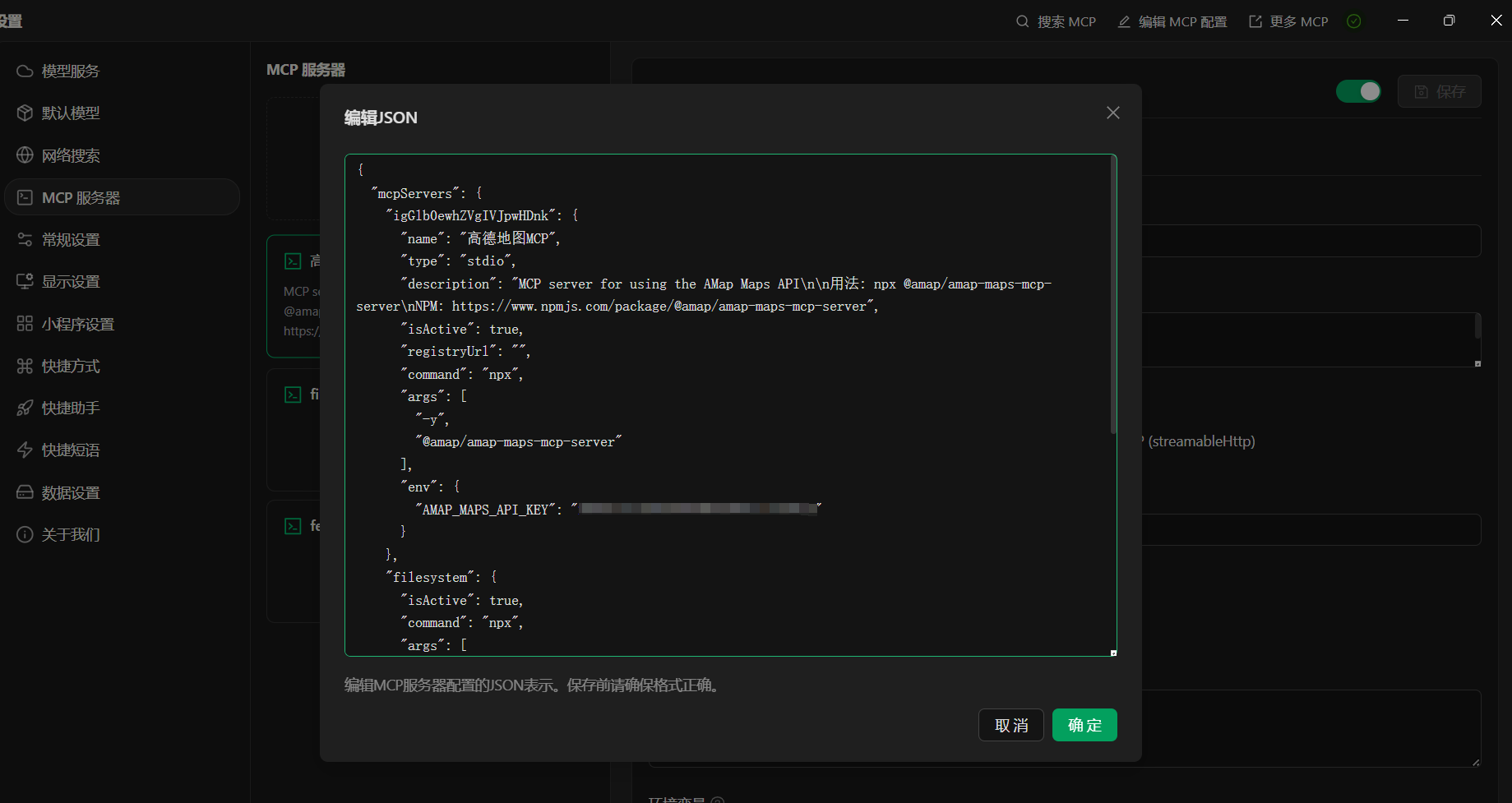
默认是C:\Program Files\nodejs,也可能在其他盘,主要取决于安装时的选择。
默认在C:\User\自己电脑用户名
C:\Program Files (x86)\Nodejs
C:\Program Files\Nodejs
C:\Users\自己电脑用户名\AppData\Roaming\npm
C:\Users\自己电脑用户名\AppData\Roaming\npm-cache
win + R ,cmd ,回车,输入node -v,回车,显示:node不是内部或外部命令,也不是可运行的程序或批处理文件。
下载地址:https://github.com/coreybutler/nvm-windows/releases
一直点NEXT,需要注意的地方是:
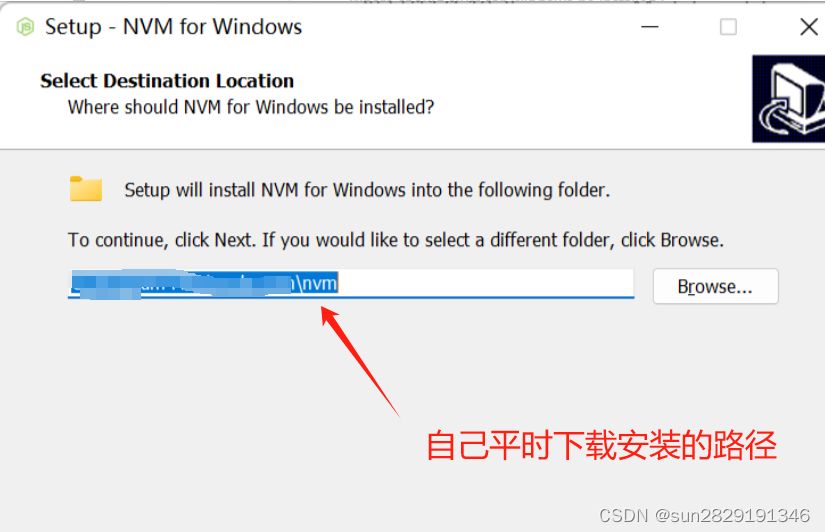
选择nodejs的快捷方式路径(这里一定得是空文件夹或者不创建这个文件夹,因为nvm会自动创建这个文件夹为快捷方式):
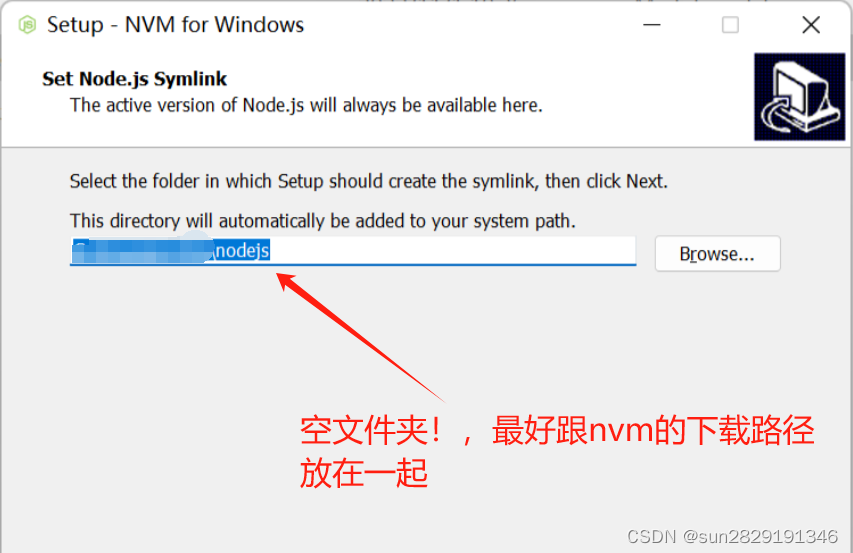
环境变量:检查是否有nvm环境变量,没有的话,加上;
NVM_HOME(nvm安装路径)
NVM_SYMLINK(nvm自动创建的nodejs文件夹的快捷方式路径)
检查Path是否添加nvm环境变量
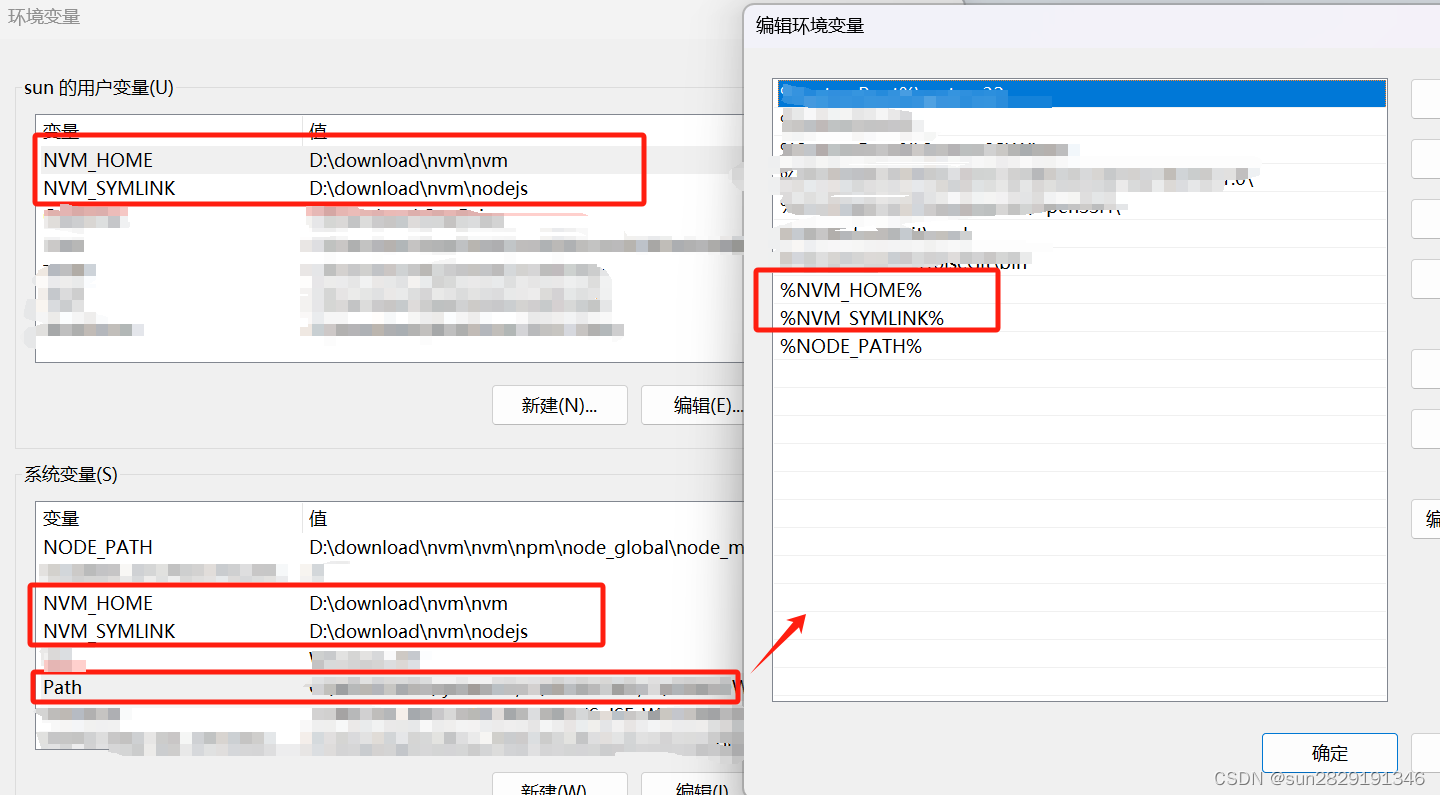
nvm -v,出现安装的nvm版本说明安装成功
以管理员身份打开命令行窗口
可以用命令:
nvm node_mirror https://npmmirror.com/mirrors/node/nvm npm_mirror https://npmmirror.com/mirrors/npm/也可以直接在配置文件(在nvm安装路径下的settings.txt)中添加:
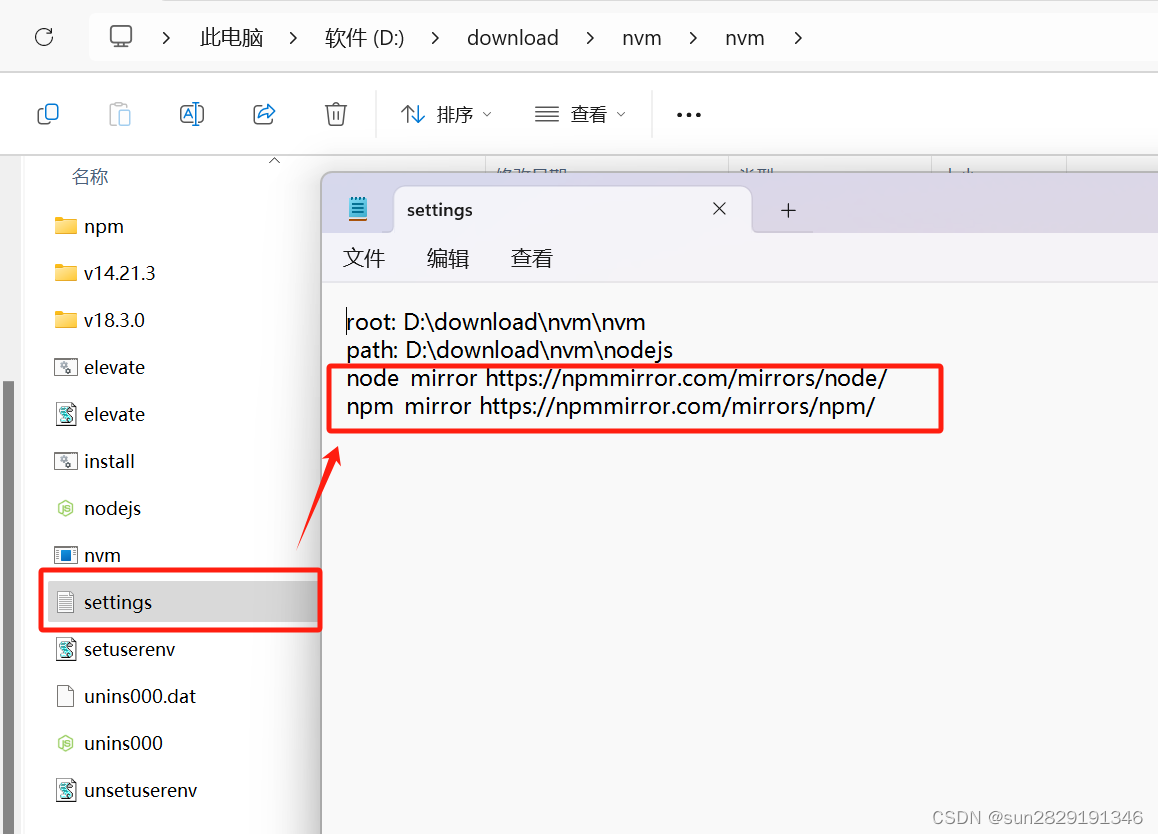
以管理员身份打开命令行窗口
nvm off // 禁用node.js版本管理(不卸载任何东西)nvm on // 启用node.js版本管理nvm install <version> // 安装node.js的命名 version是版本号 例如:nvm install 8.12.0nvm uninstall <version> // 卸载node.js是的命令,卸载指定版本的nodejs,当安装失败时卸载使用nvm ls // 显示所有安装的node.js版本nvm list available // 显示可以安装的所有node.js的版本nvm use <version> // 切换到使用指定的nodejs版本nvm v // 显示nvm版本nvm install stable // 安装最新稳定版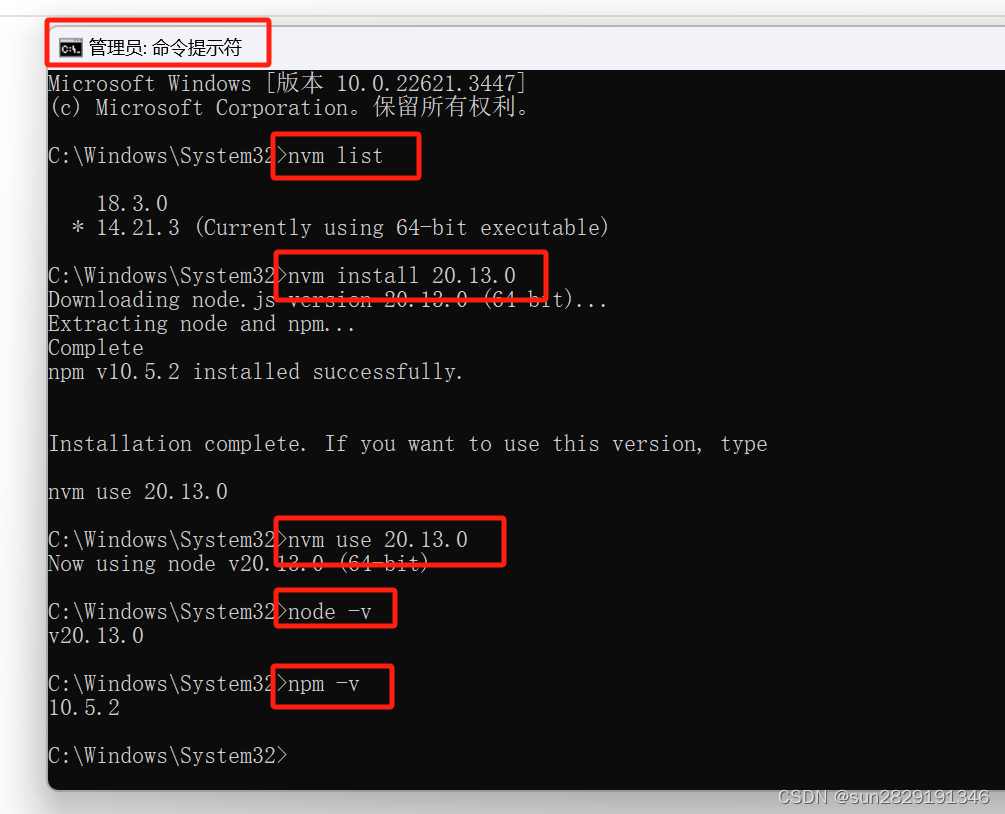
node_cache和node_global,我放到了nvm安装目录下的一个npm文件夹中。
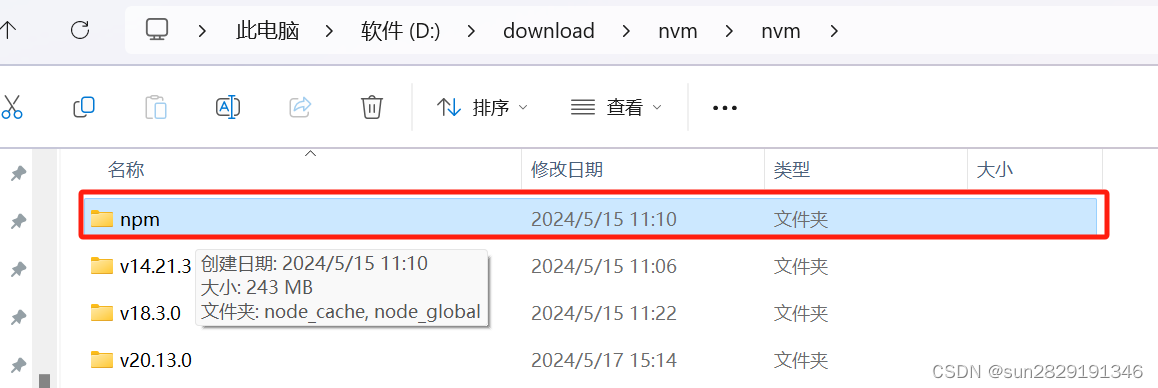
npm config set prefix 自己路径\node_globalnpm config set cache 自己路径\node_cache变量名:NODE_PATH
变量值:自己路径\node_global\node_modules
例:
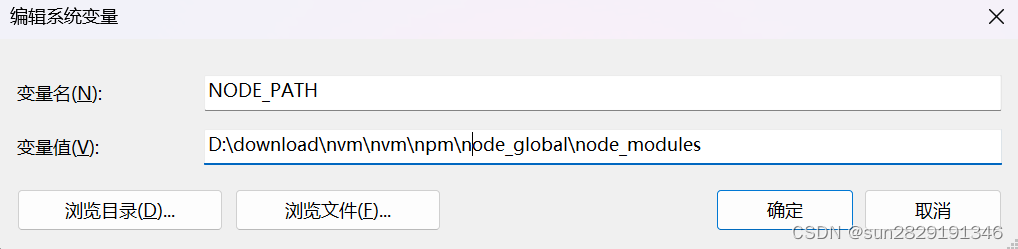
是否添加NODE_PATH
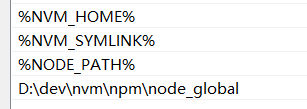
到此NVM的相关配置就完成了,可以切换不同版本的nodejs去匹配不同的项目启动。
如果想要卸载已经安装的nodejs版本:
nvm uninstall nodejs版本Process:指令和数据的有序结合,本身没有运行的含义,是一个静态的概念
Thread:程序的一次执行过程,是动态的概念,是系统分配资源的单位
通常一个进程中可以包含多个线程(至少包含一个),线程是CPU调度和执行的单位
很多多线程是模拟出来的,真正的多线程是指有多个CPU,即多核,如服务器。如果是模拟多线程,即在一个CPU的情况下,同一个时间点,CPU只能执行一个代码,因为切换的很快,就有同时执行的错觉
线程:是独立的执行路径
在程序运行时,即使没有自己创建线程,后台也会有多个线程,如主线程,gc线程
main()称之为主线程,是系统的入口,用于执行整个程序
在一个进程中如果开辟了多个线程,线程的运行由调度器安排调度,调度器是与操作系统紧密相关的,先后顺序不能人为干预
每个线程在自己的工作内存交互,内存控制不当会导致数据不一致
进程
程序由指令和数据组成,但这些指令要运行,数据要读写,就必须将指令加载至 CPU,数据加载至内存。在指令运行过程中还需要用到磁盘、网络等设备。进程就是用来加载指令、管理内存、管理 IO 的
当一个程序被运行,从磁盘加载这个程序的代码至内存,这时就开启了一个进程。
进程就可以视为程序的一个实例。大部分程序可以同时运行多个实例进程(例如记事本、画图、浏览器等),也有的程序只能启动一个实例进程(例如网易云音乐、360 安全卫士等)
线程
一个进程之内可以分为一到多个线程。
一个线程就是一个指令流,将指令流中的一条条指令以一定的顺序交给 CPU 执行
Java 中,线程作为最小调度单位,进程作为资源分配的最小单位。 在 windows 中进程是不活动的,只是作为线程的容器
二者对比
进程基本上相互独立的,而线程存在于进程内,是进程的一个子集
进程拥有共享的资源,如内存空间等,供其内部的线程共享
进程间通信较为复杂
同一台计算机的进程通信称为 IPC(Inter-process communication)
不同计算机之间的进程通信,需要通过网络,并遵守共同的协议,例如 HTTP
线程通信相对简单,因为它们共享进程内的内存,一个例子是多个线程可以访问同一个共享变量
线程更轻量,线程上下文切换成本一般上要比进程上下文切换低
继承Thread类,重写run()方法,编写线程执行体,创建线程对象,调用start()方法启动线程
Thread类继承了Runnable接口
package com.it.thread;//继承Thread类public class TestThread extends Thread{ public static void main(String[] args) { //创建线程对象 TestThread testThread = new TestThread(); //调用start()方法 testThread.start(); for (int i = 0; i < 2000; i++) { System.out.println("study thread" + i); } } //重写run()方法 @Override public void run() { for (int i = 0; i < 2000; i++) { System.out.println("run thread" + i); } }}...run thread1243run thread1244study thread1862study thread1863study thread1864study thread1865study thread1866run thread1245...线程开启不一定立即执行,由CPU调度执行
1、start():
Java API中的介绍:
使该线程开始执行;Java 虚拟机调用该线程的 run 方法。
结果是两个线程并发地运行;当前线程(从调用返回给 start 方法)和另一个线程(执行其 run 方法)。
多次启动一个线程是非法的。特别是当线程已经结束执行后,不能再重新启动。
用start方法来启动线程,真正实现了多线程运行,这时无需等待run方法体中的代码执行完毕而直接继续执行后续的代码。通过调用Thread类的 start()方法来启动一个线程,这时此线程处于就绪(可运行)状态,并没有运行,一旦得到cpu时间片,就开始执行run()方法,这里的run()方法 称为线程体,它包含了要执行的这个线程的内容,Run方法运行结束,此线程随即终止。
2、run():
Java API中的介绍:
如果该线程是使用独立的 Runnable 运行对象构造的,则调用该 Runnable 对象的 run 方法;否则,该方法不执行任何操作并返回。
Thread 的子类应该重写该方法。
run()方法只是类的一个普通方法而已,如果直接调用Run方法,程序中依然只有主线程这一个线程,其程序执行路径还是只有一条,还是要顺序执行,还是要等待run方法体执行完毕后才可继续执行下面的代码,这样就没有达到写线程的目的。
3、总结:
调用start方法方可启动线程,而run方法只是thread类中的一个普通方法调用,还是在主线程里执行。
package com.it.thread;import org.apache.commons.io.FileUtils;import java.io.File;import java.io.IOException;import java.net.URL;//多线程同步下载图片public class TestThread2 extends Thread{ private String url; private String name; public TestThread2(String url, String name){ this.url = url; this.name = name; } public static void main(String[] args) { TestThread2 t1 = new TestThread2("https://upload-bbs.mihoyo.com/upload/2021/07/27/264469153/fdfe02f60ce8078379dbd09e38350f2a_9119338217925927699.jpg?x-oss-process=image//resize,s_500/quality,q_80/auto-orient,0/interlace,1/format,jpg", "原神1.jpg"); TestThread2 t2 = new TestThread2("https://upload-bbs.mihoyo.com/upload/2021/07/27/218492859/0066d5baf610b5a89ed44dafcbc0fc26_904584898153905617.jpg?x-oss-process=image//resize,s_500/quality,q_80/auto-orient,0/interlace,1/format,jpg","原神2.jpg"); TestThread2 t3 = new TestThread2("https://upload-bbs.mihoyo.com/upload/2021/07/27/218492859/b69337893471973ae52ca13f4197b1c4_7012300301442561739.jpg?x-oss-process=image//resize,s_500/quality,q_80/auto-orient,0/interlace,1/format,jpg", "原神3.jpg"); t1.start(); t2.start(); t3.start(); } @Override public void run() { WebDownloader webDownloader = new WebDownloader(); webDownloader.download(url, name); System.out.println("下载了:" + name); } class WebDownloader{ //下载方法 public void download(String url, String name) { try { FileUtils.copyURLToFile(new URL(url), new File(name)); } catch (IOException e) { e.printStackTrace(); System.out.println("IO异常,download方法出现问题"); } } }}下载了:原神3.jpg下载了:原神1.jpg下载了:原神2.jpg实现Runnable接口,重写run()方法,执行线程需要丢入runnable接口实现类,调用start方法
package com.it.thread;//实现Runnable接口public class TestThread3 implements Runnable{ public void run() { for (int i = 0; i < 2000; i++) { System.out.println("run thread" + i); } } public static void main(String[] args) { //创建runnable接口实现类对象 TestThread3 testThread3 = new TestThread3(); //创建线程对象,通过线程对象来开启我们的线程,代理 new Thread(testThread3).start(); for (int i = 0; i < 2000; i++) { System.out.println("study thread" + i); } }}相比较继承Thread类,没有单继承局限性,推荐使用
package com.it.thread;//多个对象同时操作同一个对象//买票public class TestThread4 extends Thread{ private int ticketNums = 10; @Override public void run() { while(ticketNums > 0){ //模拟延时200毫秒 try { Thread.sleep(200); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "拿到了票,还剩余" + ticketNums-- + "张票"); } } public static void main(String[] args) { TestThread4 testThread4 = new TestThread4(); new Thread(testThread4, "Kobe").start(); new Thread(testThread4, "Lebron").start(); new Thread(testThread4, "Chris").start(); new Thread(testThread4, "Dwight").start(); }}Dwight拿到了票,还剩余8张票Lebron拿到了票,还剩余9张票Chris拿到了票,还剩余10张票Kobe拿到了票,还剩余7张票Chris拿到了票,还剩余6张票Kobe拿到了票,还剩余5张票Dwight拿到了票,还剩余6张票Lebron拿到了票,还剩余4张票Kobe拿到了票,还剩余3张票Chris拿到了票,还剩余0张票Dwight拿到了票,还剩余1张票Lebron拿到了票,还剩余2张票问题:多个线程操作同一个资源的情况,线程不安全,数据紊乱,并发问题
package com.it.thread;public class Race implements Runnable{ private static String winner; public void run() { for (int i = 0; i < 11; i++) { if("兔子".equals(Thread.currentThread().getName()) && i == 8){ try { Thread.sleep(200); } catch (InterruptedException e) { e.printStackTrace(); } } if(gameOver(i))break; System.out.println(Thread.currentThread().getName() + "跑了" + i + "米"); } } private boolean gameOver(int steps){ if(winner != null)return true;//产生胜利者比赛结束 if(steps >= 10){ winner = Thread.currentThread().getName(); System.out.println("winner is " + winner); return true; } return false; } public static void main(String[] args) { Race race = new Race(); new Thread(race, "乌龟").start(); new Thread(race, "兔子").start(); }}乌龟跑了0米兔子跑了0米乌龟跑了1米兔子跑了1米乌龟跑了2米兔子跑了2米乌龟跑了3米兔子跑了3米乌龟跑了4米兔子跑了4米乌龟跑了5米兔子跑了5米乌龟跑了6米兔子跑了6米乌龟跑了7米兔子跑了7米乌龟跑了8米乌龟跑了9米winner is 乌龟实现Callable接口,需要返回值类型,
重写call()方法,需要抛出异常
创建目标对象
创建执行服务
提交执行
获取结果
关闭服务
package com.it.thread;import org.apache.commons.io.FileUtils;import java.io.File;import java.io.IOException;import java.net.URL;import java.util.concurrent.*;//继承Callable接口public class TestCallable implements Callable<Boolean> { private String url; private String name; public TestCallable(String url, String name){ this.url = url; this.name = name; } public static void main(String[] args) throws ExecutionException, InterruptedException { TestCallable t1 = new TestCallable("https://upload-bbs.mihoyo.com/upload/2021/07/27/264469153/fdfe02f60ce8078379dbd09e38350f2a_9119338217925927699.jpg?x-oss-process=image//resize,s_500/quality,q_80/auto-orient,0/interlace,1/format,jpg", "原神1.jpg"); TestCallable t2 = new TestCallable("https://upload-bbs.mihoyo.com/upload/2021/07/27/218492859/0066d5baf610b5a89ed44dafcbc0fc26_904584898153905617.jpg?x-oss-process=image//resize,s_500/quality,q_80/auto-orient,0/interlace,1/format,jpg","原神2.jpg"); TestCallable t3 = new TestCallable("https://upload-bbs.mihoyo.com/upload/2021/07/27/218492859/b69337893471973ae52ca13f4197b1c4_7012300301442561739.jpg?x-oss-process=image//resize,s_500/quality,q_80/auto-orient,0/interlace,1/format,jpg", "原神3.jpg"); //创建执行服务,创建线程池 ExecutorService ser = Executors.newFixedThreadPool(3); //提交执行,详情见线程池 Future<Boolean> result1 = ser.submit(t1); Future<Boolean> result2 = ser.submit(t2); Future<Boolean> result3 = ser.submit(t3); //获取结果 System.out.println(result1); boolean r1 = result1.get(); boolean r2 = result2.get(); boolean r3 = result3.get(); System.out.println(r1); System.out.println(r2); System.out.println(r3); if(r1&&r2&&r3){ System.out.println("下载成功"); //关闭服务 ser.shutdown(); } } public Boolean call(){ TestCallable.WebDownloader webDownloader = new TestCallable.WebDownloader(); webDownloader.download(url, name); System.out.println("下载了:" + name); return true; } class WebDownloader{ //下载方法 public void download(String url, String name) { try { FileUtils.copyURLToFile(new URL(url), new File(name)); } catch (IOException e) { e.printStackTrace(); System.out.println("IO异常,download方法出现问题"); } } }}下载了:原神1.jpg下载了:原神2.jpg下载了:原神3.jpgtruetruetrue下载成功优点:
可以定义返回值
可以抛出异常
package com.it.proxy;//模拟结婚代理public class StaticProxy { public static void main(String[] args) { Marry marry = new WeddingCompany(new You()); marry.HappyMarry(); }}interface Marry{ void HappyMarry();}class You implements Marry{ public void HappyMarry() { System.out.println("你结婚了"); }}class WeddingCompany implements Marry{ private Marry target; public WeddingCompany(Marry target){ this.target = target; } public void HappyMarry() { before(); this.target.HappyMarry(); after(); } private void after() { System.out.println("收尾款"); } private void before() { System.out.println("布置现场"); }}布置现场你结婚了收尾款总结:
Thread类和目标类都实现了Runnable接口,运用了静态代理模式
new Thread( ()-> System.out.println("I love U")).start();//Lambda 表达式new WeddingCompany(new You()).HappyMarry();Lambda:希腊字母表的第11个字母λ
语法格式:
(parameters) -> expression 或 (parameters) ->
参数类型可以不写
重要特征:
避免匿名内部类定义过多,其实质属于函数式编程的概念
任何接口,如果只包含唯一一个抽象方法,那么它就是一个函数式接口(注解:@FunctionalInterface)
对于函数式接口,我们可以通过lambda表达式来创建该接口的对象
package com.it.proxy;//推导lambda表达式public class TestLambda { //3.静态内部类 static class Like2 implements ILike{ @Override public void lambda() { System.out.println("I like Lambda too"); } } public static void main(String[] args) { ILike iLike = new Like(); iLike.lambda(); iLike = new Like2(); iLike.lambda(); //4.局部内部类 class Like3 implements ILike{ @Override public void lambda() { System.out.println("I also like Lambda"); } } new Like3().lambda(); //5.匿名内部类,没有类的名称,必须借助接口或者父类 iLike = new ILike() { @Override public void lambda() { System.out.println("I like lambda more"); } }; iLike.lambda(); //6.Lambda表达式 iLike = ()-> System.out.println("I am lambda"); iLike.lambda(); }}//1.定义一个函数式接口interface ILike{ void lambda();//abstract}//2.实现类class Like implements ILike{ @Override public void lambda() { System.out.println("I like Lambda"); }}
package com.it.thread;//测试停止线程//1、建设线程正常停止--->利用次数,不建议死循环//2、建议使用标志位//3、不要使用stop或destroy等过时的方法public class TestStop implements Runnable{ private boolean flag = true; @Override public void run() { int i = 0; while (flag) System.out.println("run...Thread " + i++); } //设置公开方法停止线程,转换标志位 public void stop(){ this.flag = false; } public static void main(String[] args) { TestStop testStop = new TestStop(); new Thread(testStop).start(); for (int i = 0; i < 20; i++) { System.out.println("main + " + i); if(i == 9){ testStop.stop(); System.out.println("线程停止"); } } }}main + 0main + 1run...Thread 0main + 2run...Thread 1run...Thread 2run...Thread 3run...Thread 4run...Thread 5run...Thread 6run...Thread 7run...Thread 8run...Thread 9run...Thread 10run...Thread 11run...Thread 12main + 3run...Thread 13main + 4run...Thread 14main + 5run...Thread 15main + 6run...Thread 16main + 7run...Thread 17run...Thread 18run...Thread 19run...Thread 20run...Thread 21run...Thread 22main + 8main + 9run...Thread 23线程停止main + 10main + 11main + 12main + 13main + 14main + 15main + 16main + 17main + 18main + 19sleep(时间)制定线程阻塞的毫秒数
存在异常InterruptedException
sleep时间到达后线程进入就绪状态
可以用来模拟网络延时和倒计时等
每一个对象都有一个锁,sleep不会释放锁
package com.it.thread;import java.text.SimpleDateFormat;import java.util.Date;//模拟倒计时public class TestSleep { public static void main(String[] args) { Date startTime = new Date(System.currentTimeMillis()); while(true){ try { Thread.sleep(1000); System.out.println(new SimpleDateFormat(("yyyy/MM/dd HH:mm:ss")).format(startTime)); startTime = new Date(System.currentTimeMillis()); } catch (InterruptedException e) { e.printStackTrace(); } } }}2021/07/29 20:41:052021/07/29 20:41:062021/07/29 20:41:072021/07/29 20:41:082021/07/29 20:41:09...yield()让当前正在执行的线程暂停,但不阻塞
线程从运行状态变为就绪状态
让CPU重新调度,礼让不一定成功,由CPU决定
package com.it.thread;public class TestYield { public static void main(String[] args) { new Thread(new MyYield(), "a").start(); new Thread(new MyYield(), "b").start(); }}class MyYield implements Runnable{ @Override public void run() { System.out.println(Thread.currentThread().getName() + " start"); Thread.yield(); System.out.println(Thread.currentThread().getName() + " end"); }}a startb starta endb endjoin()合并线程,待此线程执行完成后,再执行其他线程,其他线程阻塞,不建议使用
package com.it.thread;public class TestJoin implements Runnable{ @Override public void run() { for (int i = 0; i < 50; i++) { System.out.println("vip: " + i); } } public static void main(String[] args) { TestJoin testJoin = new TestJoin(); Thread thread = new Thread(testJoin); thread.start(); for (int i = 0; i < 20; i++) { System.out.println("main: " + i); if(i == 5){ try { thread.join(); System.out.println("-------------"); } catch (InterruptedException e) { e.printStackTrace(); } } } }}main: 0vip: 0main: 1vip: 1main: 2vip: 2main: 3main: 4main: 5vip: 3vip: 4vip: 5vip: 6vip: 7vip: 8vip: 9vip: 10vip: 11vip: 12vip: 13vip: 14vip: 15vip: 16vip: 17vip: 18vip: 19vip: 20vip: 21vip: 22vip: 23vip: 24vip: 25vip: 26vip: 27vip: 28vip: 29vip: 30vip: 31vip: 32vip: 33vip: 34vip: 35vip: 36vip: 37vip: 38vip: 39vip: 40vip: 41vip: 42vip: 43vip: 44vip: 45vip: 46vip: 47vip: 48vip: 49-------------main: 6main: 7main: 8main: 9main: 10main: 11main: 12main: 13main: 14main: 15main: 16main: 17main: 18main: 19public static enum Thread.Stateextends Enum<Thread.State>线程状态。线程可以处于以下状态之一:
NEW
尚未启动的线程处于此状态。
RUNNABLE
在Java虚拟机中执行的线程处于此状态。
BLOCKED
被阻塞等待监视器锁定的线程处于此状态。
WAITING
正在等待另一个线程执行特定动作的线程处于此状态。
正在等待另一个线程执行动作达到指定等待时间的线程处于此状态。
已退出的线程处于此状态。
一个线程可以在给定时间点处于一个状态。 这些状态是不反映任何操作系统线程状态的虚拟机状态。
package com.it.thread;public class TestThreadState { public static void main(String[] args) throws InterruptedException { Thread thread = new Thread (()->{ for (int i = 0; i < 3; i++) { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println("------------------"); }); //观测状态 Thread.State state = thread.getState(); System.out.println("state1: " + state); //启动后状态 thread.start(); state = thread.getState(); System.out.println("state2: " + state); while(state != Thread.State.TERMINATED){ Thread.sleep(500); state = thread.getState(); System.out.println("state3: " + state); } }}state1: NEWstate2: RUNNABLEstate3: TIMED_WAITINGstate3: TIMED_WAITINGstate3: TIMED_WAITINGstate3: TIMED_WAITINGstate3: TIMED_WAITING------------------state3: TERMINATEDPriority由数字表示,范围1~10
package com.it.thread;public class TestPriority{ public static void main(String[] args) { System.out.println("main--->" + Thread.currentThread().getPriority()); MyPriority myPriority = new MyPriority(); Thread t1 = new Thread(myPriority); Thread t2 = new Thread(myPriority); Thread t3 = new Thread(myPriority); Thread t4 = new Thread(myPriority); Thread t5 = new Thread(myPriority); t1.setPriority(1); t2.setPriority(2); t3.setPriority(Thread.MAX_PRIORITY); t4.setPriority(Thread.MIN_PRIORITY); t5.setPriority(Thread.NORM_PRIORITY); t1.start(); t2.start(); t3.start(); t4.start(); t5.start(); }}class MyPriority implements Runnable{ @Override public void run() { System.out.println(Thread.currentThread().getName() + "--->" + Thread.currentThread().getPriority()); }}main--->5Thread-0--->1Thread-1--->2Thread-2--->10Thread-3--->1Thread-4--->5优先级高的不一定先跑,只是增加权重,调度的概率高,决定权还是在CPU的调度
先设置优先级,后启动
线程分为用户线程和守护(daemon)线程
虚拟机必须确保用户线程执行完毕
虚拟机不必等待守护线程执行完毕,如后台记录操作日志,监控内存,垃圾回收等待…
package com.it.thread;public class TestDaemon { public static void main(String[] args) { God god = new God(); You you = new You(); Thread thread = new Thread(god); thread.setDaemon(true); //设置为守护线程 thread.start(); new Thread(you).start(); }}class God implements Runnable{ @Override public void run() { while(true){ System.out.println("god bless you"); } }}class You implements Runnable{ @Override public void run() { for (int i = 0; i < 80; i++) { System.out.println("you are " + i + "years old"); } System.out.println("goodbye, world"); }}god bless yougod bless you...god bless youyou are 0years oldgod bless you...you are 79years oldgod bless you...goodbye, worldgod bless yougod bless yougod bless yougod bless yougod bless yougod bless you...并发:同一个对象被多个线程同时操作
处理多线程问题时,某些线程还想修改这个对象,这时我们就需要线程同步,线程同步其实就是一种等待机制,多个需要同时访问这个对象的线程进入这个线程的等待池形成队列,等待前面的线程使用完毕,下一个线程再使用
为了保证数据在方法中被访问时的正确性,在访问时加入锁机制 synchronized,每个对象都有一把锁,当一个线程获得对象的排它锁,独占资源,其他线程必须等待,使用后释放锁即可
package com.it.thread;//安全问题public class TestBank { public static void main(String[] args) { new Drawing("Me", 50, 0).start(); new Drawing("You", 100, 0).start(); } static class Drawing extends Thread{ private String name; private int drawMoney; private int nowMoney; public Drawing(String name, int drawMoney, int nowMoney) { this.name = name; this.drawMoney = drawMoney; this.nowMoney = nowMoney; } @Override public void run() { //sleep放大问题的发生性 try { sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } Account.totalMoney -= drawMoney; nowMoney += drawMoney; System.out.println(name + "取走了" + drawMoney + "元,现在有" + nowMoney + "元,账户余额:" + Account.totalMoney + "元"); } } static class Account{ private static int totalMoney = 100; public Account(int totalMoney) { this.totalMoney = totalMoney; } }}You取走了100元,现在有100元,账户余额:-50元Me取走了50元,现在有50元,账户余额:-50元List的不安全性
package com.it.thread;import java.util.ArrayList;import java.util.List;public class UnsafeList { public static void main(String[] args) { List<String> list = new ArrayList<>(); for (int i = 0; i < 10000; i++) { new Thread(()->list.add(Thread.currentThread().getName())).start(); } try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(list.size()); }}9998同一时间,两个元素被添加到了数组的同一位置,就导致了添加到List的数据变少
由于我们可以通过private关键字来保证数据对象只能被方法访问,所以我们只需要针对方法提出一套机制,这套机制就是synchronized关键字,包括两种用法:synchronized方法和synchronized块
synchronized方法控制对对象的访问,每个对象对应一把锁,每个synchronized方法都必须获得调用该方法的对象的锁才能执行,否则线程会阻塞,方法一旦执行,就独占该锁,直到该方法返回才释放锁后面被阻塞的线程才能获得这个锁
缺陷:若将一个大方法设置为synchronized将会影响效率
方法里面需要修改的内容才需要锁
package com.it.thread;public class TestBank { public static void main(String[] args) { Account account = new Account(100); new Drawing(account, "Me", 50, 0).start(); new Drawing(account, "You", 100, 0).start(); } static class Drawing extends Thread{ private String name; private int drawMoney; private int nowMoney; private Account account; public Drawing(Account account, String name, int drawMoney, int nowMoney) { this.account = account; this.name = name; this.drawMoney = drawMoney; this.nowMoney = nowMoney; } @Override public void run() { synchronized (account){ //sleep放大问题的发生性 try { sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } account.totalMoney -= drawMoney; nowMoney += drawMoney; System.out.println(name + "取走了" + drawMoney + "元,现在有" + nowMoney + "元,账户余额:" + account.totalMoney + "元"); } } } static class Account{ private int totalMoney; public Account(int totalMoney) { this.totalMoney = totalMoney; } }}Me取走了50元,现在有50元,账户余额:50元You取走了100元,现在有100元,账户余额:-50元package com.it.thread;//多个对象同时操作同一个对象//买票public class TestThread4 extends Thread{ private int ticketNums = 10; @Override public synchronized void run() { while(ticketNums > 0){ //模拟延时200毫秒 try { Thread.sleep(200); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "拿到了票,还剩余" + ticketNums-- + "张票"); } } public static void main(String[] args) { TestThread4 testThread4 = new TestThread4(); new Thread(testThread4, "Kobe").start(); new Thread(testThread4, "Lebron").start(); new Thread(testThread4, "Chris").start(); new Thread(testThread4, "Dwight").start(); }}Kobe拿到了票,还剩余10张票Kobe拿到了票,还剩余9张票Kobe拿到了票,还剩余8张票Kobe拿到了票,还剩余7张票Kobe拿到了票,还剩余6张票Kobe拿到了票,还剩余5张票Kobe拿到了票,还剩余4张票Kobe拿到了票,还剩余3张票Kobe拿到了票,还剩余2张票Kobe拿到了票,还剩余1张票package com.it.thread;import java.util.ArrayList;import java.util.List;public class UnsafeList { public static void main(String[] args) { List<String> list = new ArrayList<>(); for (int i = 0; i < 10000; i++) { new Thread(()->{ synchronized (list){ list.add(Thread.currentThread().getName()); } }).start(); } try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(list.size()); }}10000package com.it.thread;import java.util.concurrent.CopyOnWriteArrayList;//测试JUC(java.util.concurrent:并发包)安全类型的集合public class TestJUC { public static void main(String[] args) { CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>(); for (int i = 0; i < 10000; i++) { new Thread(()->list.add(Thread.currentThread().getName())).start(); } try { Thread.sleep(300); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(list.size()); }}10000同步块:synchronized (Obj)
多个资源各自占用一些共享资源,并且相互等待其他线程占有的资源才能运行,而导致都停止执行的行为
某一个同步块同时拥有两个以上对象的锁时,就可能发生死锁的问题
package com.it.thread;//死锁public class DeadLock { public static void main(String[] args) { MakeUp girl1 = new MakeUp(1, "A"); MakeUp girl2 = new MakeUp(0, "B"); girl1.start(); girl2.start(); }}//口红class Lipstick{}//镜子class Mirror{}class MakeUp extends Thread{ //static保证资源只有一份 static Lipstick lipstick = new Lipstick(); static Mirror mirror = new Mirror(); int choice;//选择 String user;//用化妆品的人 public MakeUp(int choice, String user) { this.choice = choice; this.user = user; } private void makeup() throws InterruptedException { if(choice == 0){ synchronized (lipstick){//获得口红的锁 System.out.println(this.user + "获得口红"); Thread.sleep(1000); synchronized (mirror){ System.out.println(this.user + "获得镜子"); } } }else{ synchronized (mirror){//获得口红的锁 System.out.println(this.user + "获得镜子"); Thread.sleep(2000); synchronized (lipstick){ System.out.println(this.user + "获得口红"); } } } } @Override public void run() { try { makeup(); } catch (InterruptedException e) { e.printStackTrace(); } }}B获得口红A获得镜子产生死锁的必要条件:
从jdk5.0开始,java提供了通过显式定义同步锁对象来实现同步,同步锁使用Lock对象充当
java.util.concurrent.locks.Lock接口是控制多个线程对共享资源进行访问的工具,锁提供了对资源的独占访问,每次只能有一个线程对Lock对象加锁,线程开始访问资源之前应先获得Lock对象
ReentrantLock类(可重入锁)实现了Lock,它拥有与synchronized相同的并发性和内存语义,在实现线程安全的控制中,比较常用的是ReentrantLock,可以显式加锁和释放锁
与synchronized的区别
wait():表示线程一直等待,直至其他线程通知,与sleep不同,会释放锁
wait(long timeout):指定等待的毫秒数
notify():唤醒一个处于等待状态的线程
notifyAll():唤醒一个对象上所有调用wait()方法的线程,优先级高的线程优先调度
以上方法均是Object类的方法,只能在同步方法或同步块中使用,否则会抛出异常IIIegalMonitorStateException
package com.it.thread;//生产者/消费者模式-->利用缓冲区解决:管程法public class TestPC { public static void main(String[] args) { SynContainer synContainer = new SynContainer(); new Productor(synContainer).start(); new Consumer(synContainer).start(); }}//生产者class Productor extends Thread{ SynContainer container; public Productor(SynContainer container) { this.container = container; } //生产 @Override public void run() { for (int i = 0; i < 100; i++) { container.push(new Chicken(i)); System.out.println("生产了编号为" + i + "的鸡"); } }}//消费者class Consumer extends Thread{ SynContainer container; public Consumer(SynContainer container) { this.container = container; } //消费 @Override public void run() { for (int i = 0; i < 100; i++) { System.out.println("消费了编号为" + container.pop().getId() + "的鸡"); } }}//产品class Chicken{ private int id; public Chicken(int id) { this.id = id; } public int getId() { return id; } public void setId(int id) { this.id = id; }}//缓冲区class SynContainer{ //容器 Chicken[] chickens = new Chicken[10]; //计数器 int count = 0; //生产者放入产品 public synchronized void push(Chicken chicken){ //如果容器满了,就等待消费者消费 if(count == chickens.length){ try { this.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } //如果没有满,就丢入商品 chickens[count] = chicken; count++; //通知消费者消费 this.notify(); } //消费者消费产品 public synchronized Chicken pop(){ //判断能否消费 if(count == 0){ //等待生产者生产 try { this.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } //如果可以消费 count--; Chicken chicken = chickens[count]; //吃完,通知生产者生产 this.notify(); return chicken; }}生产了编号为0的鸡生产了编号为1的鸡生产了编号为2的鸡生产了编号为3的鸡生产了编号为4的鸡生产了编号为5的鸡生产了编号为6的鸡生产了编号为7的鸡生产了编号为8的鸡生产了编号为9的鸡生产了编号为10的鸡消费了编号为9的鸡消费了编号为10的鸡生产了编号为11的鸡消费了编号为11的鸡... ...生产了编号为97的鸡生产了编号为98的鸡生产了编号为99的鸡消费了编号为96的鸡消费了编号为99的鸡消费了编号为98的鸡消费了编号为97的鸡消费了编号为94的鸡消费了编号为93的鸡package com.it.thread;////生产者/消费者模式-->利用标志位解决:信号灯法public class TestPC2 { public static void main(String[] args) { TV tv = new TV(); new Player(tv).start(); new Watcher(tv).start(); }}//生成者-->class Player extends Thread{ TV tv; public Player(TV tv) { this.tv = tv; } @Override public void run() { for (int i = 0; i < 20; i++) { if(i%2 == 0){ this.tv.play("电影"); }else{ this.tv.play("动物世界"); } } }}//消费者-->观众class Watcher extends Thread{ TV tv; public Watcher(TV tv) { this.tv = tv; } @Override public void run() { for (int i = 0; i < 20; i++) { this.tv.watch(); } }}//产品-->节目class TV extends Thread{ //演员表演,观众等待,观众观看,演员等待 String movie; boolean flag = true; //表演 public synchronized void play(String movie){ if(!flag){ try { this.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println("表演" + movie); //通知观众观看 this.notifyAll(); this.movie = movie; this.flag = !this.flag; } //观看 public synchronized void watch(){ if(flag){ try { this.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println("观看" + this.movie); //通知观众观看 this.notifyAll(); this.flag = !this.flag; }}表演电影观看电影表演动物世界观看动物世界表演电影观看电影表演动物世界观看动物世界表演电影观看电影表演动物世界观看动物世界表演电影观看电影表演动物世界观看动物世界表演电影观看电影表演动物世界观看动物世界表演电影观看电影表演动物世界观看动物世界表演电影观看电影表演动物世界观看动物世界表演电影观看电影表演动物世界观看动物世界表演电影观看电影表演动物世界观看动物世界表演电影观看电影表演动物世界观看动物世界背景:经常创建和销毁使用量特别大的资源,比如并发情况下的线程,对性能影响很大
思路:提前创建多个线程,放入线程池中,使用时直接获取,使用完放回池中。可以避免频繁创建销毁,实现重复利用
好处:提高响应速度(减少了创建的时间)、降低资源消耗(重复利用了池中线程,不需要每次都创建)、便于线程管理(corePoolSize,maximumPoolSize、keepAliveTime…)…
JDK5.0提供了线程池相关的API: ExecutorService和Executors
ExecutorService:真正的线程池接口。常见子类ThreadPoolExecutor
Executors:工具类、线程池的工厂类,用于创建并返回不同类型的线程池
package com.it.thread;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;//测试线程池public class TestPool { public static void main(String[] args) { //1、创建服务,创建线程池 //newFixedThreadPool 参数为线程池大小 ExecutorService service = Executors.newFixedThreadPool(10); //执行 service.execute(new MyThread()); service.execute(new MyThread()); service.execute(new MyThread()); service.execute(new MyThread()); service.execute(new MyThread()); //2、关闭连接 service.shutdown(); }}class MyThread implements Runnable{ @Override public void run() { System.out.println(Thread.currentThread().getName()); }}pool-1-thread-1pool-1-thread-4pool-1-thread-3pool-1-thread-2pool-1-thread-5package com.it.thread;import java.util.concurrent.*;//测试线程池public class TestPool { public static void main(String[] args) { //FutureTask类实现了RunnableFuture接口,RunnableFuture继承了Runnable, Future接口FutureTask<Integer> futureTask = new FutureTask<Integer>(new MyThread()); new Thread(futureTask).start(); Integer integer = null; try { integer = futureTask.get(); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } System.out.println(integer); }}class MyThread implements Callable<Integer> { @Override public Integer call() throws Exception { System.out.println("MyThread"); return 100; }}MyThread100ps -fe 查看所有进程
ps -fT -p 查看某个进程(PID)的所有线程
kill 杀死进程
top 按大写 H 切换是否显示线程
top -H -p查看某个进程(PID)的所有线程
因为以下一些原因导致 cpu 不再执行当前的线程,转而执行另一个线程的代码
当 Context Switch 发生时,需要由操作系统保存当前线程的状态,并恢复另一个线程的状态,Java 中对应的概念就是程序计数器(Program Counter Register),它的作用是记住下一条 jvm 指令的执行地址,是线程私有的
状态包括程序计数器、虚拟机栈中每个栈帧的信息,如局部变量、操作数栈、返回地址等
Context Switch 频繁发生会影响性能
了解:上下文切换会带来直接和间接两种因素影响程序性能的消耗. 直接消耗包括: CPU寄存器需要保存和加载, 系统调度器的代码需要执行, TLB实例需要重新加载, CPU 的pipeline需要刷掉; 间接消耗指的是多核的cache之间得共享数据, 间接消耗对于程序的影响要看线程工作区操作数据的大小).
直接调用 run 是在主线程中执行了 run,没有启动新的线程
使用 start 是启动新的线程,通过新的线程间接执行 run 中的代码
sleep
调用 sleep 会让当前线程从 Running 进入 Timed Waiting 状态(阻塞)
其它线程可以使用 interrupt 方法打断正在睡眠的线程,这时 sleep 方法会抛出InterruptedException
睡眠结束后的线程未必会立刻得到执行
建议用 TimeUnit 的 sleep 代替 Thread 的 sleep 来获得更好的可读性
yield
打断 sleep,wait,join(join的底层还是调用wait) 的线程(打断后都会抛InterruptedException,并且都会清除标记状态)
打断sleep会清空打断状态
打断正常运行的线程, 不会清空打断状态
需要等待结果返回,才能继续运行(可以实现同步)
stop会直接终止线程,直接释放所有占用的资源,会破坏锁结构
suspend和resume对应,前者挂起线程,后者恢复线程(使用会很容易造成死锁)
一个线程不断的去记录系统的信息,当用户按下停止按钮时,启动另一个线程去停止记录线程。
如何让一个线程 T1 去停止另一个线程 T2 呢?很简单,Thread 为我们提供了一个 API,就是 stop() 方法。
使用 stop 方法确实能达到效果,但是却有个致命的问题,当 stop 一个线程时,该线程在哪里被 stop 我们是无法感知的! stop 方法并不稳定,现在已经过时。
可应采取两阶段暂停模式来优雅的停止线程。而两阶段终止模式的关键就在于 interrupt() 方法的使用。
先介绍下 interrupt() 方法。
当调用一个线程的 interrupt 方法时,并不会直接让该线程停止,而是给该线程设置一个打断标记,也就是打断标记为 true。
但是注意,如果被打断线程正处于 sleep、wait、join这三种状态,则会导致被打断的线程抛出 InterruptedException,并清除打断标记,也就是置为
false。
那么我们就可以通过判断打断标记是否为真,来停止线程。
package com.hu;import lombok.extern.slf4j.Slf4j;import org.junit.jupiter.api.Test;import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest@Slf4jclass ThreadStudyApplicationTests { @Test void contextLoads() { Thread t1 = new Thread(() -> { Thread current = Thread.currentThread(); while (true) { if (current.isInterrupted()) { log.info("收尾操作"); break; } try { // 如果睡眠时被打断,需要重新打断,将打断标记设为true Thread.sleep(500); } catch (InterruptedException e) { // 重新打断 current.interrupt(); log.info("是否被打断:{}", current.isInterrupted()); e.printStackTrace(); } // 正常运行时打断,打断标记为true log.info("记录系统信息"); } }, "t1"); t1.start(); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } Thread t2 = new Thread(()->{ log.info("停止监控记录"); t1.interrupt(); }, "t2"); t2.start(); }}Balking (犹豫)模式用在一个线程发现另一个线程或本线程已经做了某一件相同的事,那么本线程就无需再做了,直接结束返回,比如单例模式
]]>只要有并发的地方、任务数量大或小、每个任务执行时间长或短的都可以使用线程池
只不过在使用线程池的时候,注意一下设置合理的线程池大小即可
线程池存在于Java的并发包J.U.C中,线程池可以根据项目灵活控制并发的数目,避免频繁的创建和销毁线程,达到线程对象的重用。

1、 接口Executor
接口Executor中,只有一个方法,为execute()
2、 接口ExecutorService,继承自Executor
几个重要的方法:
(1) 关闭线程池的方法,有两种
一个ExecutorService(J.U.C)可以关闭,这将导致它拒绝新的任务。 ExecutorService的两种关闭线程池的方式,shutdown和shutdownNow方法:
① shutdown():拒收新的任务,立马关闭正在执行的任务,可能会引起报错,需要异常捕获
② shutdownNow():拒收新的任务,等待任务执行完毕,要确保任务里不会有永久等待阻塞的逻辑,否则会导致线程关闭不了
③ 不是马上关闭,要想等待线程池关闭,还需要调用waitFermination来阻塞等待
④ 还有一些业务场景下,需要知道线程池中的任务是否全部执行完成,当我们关闭线程池之后,可以用isTerminated来判断所有的线程是否执行完成,千万不要用isShutdown,它只是返回你是否调用过shutdown的结果
(2) submit()方法
submit()方法在ExecutorService中,ExecutorService接口继承Executor接口,方法submit延伸的方法Executor.execute(Runnable)通过创建并返回一个Future可用于取消执行和/或等待完成。submit()与execute()的一个区别是submit()有返回值,并且能够处理异常,在task里会抛出checked或者unchecked exception, 而又希望外面的调用者能够感知这些exception并作出及时的处理,用 submit,通过捕获Future.get抛出的异常
3、 Executors(J.U.C)
提供了6个静态方法,分别创建6种不同的线程池,六大静态方法 内部都是直接或间接调用ThreadPoolExecutor类的构造方法创建线程池对象,这六个静态方法本身是没有技术含量的。
| Executors(类) | Executors静态方法 | 实现类 |
|---|---|---|
| newCachedThreadPool | ThreadPoolExecutor | |
| newFixedThreadPool | ThreadPoolExecutor | |
| newSingleThreadExecutor | ThreadPoolExecutor | |
| newScheduledThreadPool | ScheduledThreadPoolExecutor | |
| newSingleThreadScheduledExecutor | ScheduledThreadPoolExecutor | |
| newWorkStealingPool | ForkJoinPool | |
| Executor(接口):只有一个方法execute() |
无论是创建何种类型线程池(FixedThreadPool、CachedThreadPool…),均会调用ThreadPoolExecutor构造函数,下面详细解读各个参数的作用
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler);}(1) 刚开始运行时,线程池是空的
(2) 一个任务进来,检查池中的线程数量,是否达到corePoolSize,如果没有达到,则创建线程,执行任务
(3) 任务执行完成之后,线程不会销毁,而是阻塞的等待下一个任务
(4) 又进来一个任务,不是直接使用阻塞的线程,而是检查线程池中的线程数大小,是否达到corePoolSize,如果没有达到,则继续创建新的线程,来执行新的任务,如此往复, 直到线程池中的线程数达到corePoolSize,此时停止创建新的线程
(5) 此时,又来新的任务,会选择线程池中阻塞等待的线程来执行任务,有一个任务进来,唤醒一个线程来执行这个任务,处理完之后,再次阻塞,尝试在workQueue上获取下一 个任务,如果线程池中没有可唤醒的线程,则任务进入workQueue,排队等待
(6) 如果队列是无界队列,比如LinkedBlockingQueue,默认最大容量为Integer.MAX,接近于无界,可用无限制的接收任务,如果队列是有界队列,比如ArrayBlockingQueue,可限定队列大小,当线程池中的线程来不及处理,然后,所有的任务都进入队列,队列的任务数也达到限定大小,此时,再来新的任务,就会入队失败,然后,就会再次尝试在线程池里创建线程,直到线程数达到maximumPoolSize,停止创建线程
(7)此时,队列满了,新的任务无法入队,创建的线程数也达到了maximumPoolSize,无法再创建新的线程,此时,就会reject掉,使用拒绝策略RejectedExecutionHandler,不让继续提交任务,默认的是AbortPolicy策略,拒绝,并抛出异常
(8) 超出corePoolSize数创建的那部分线程,是跟空闲时间keepAliveTime相关的,如果超过keepAliveTime时间还获取不到任务,线程会被销毁,自动释放掉
线程池饱和策略分为一下几种:


Interger.MAX_VALUE,特性先进先出,由于该队列的近似无界性,当线程池中线程数量达到corePoolSize后,再有新任务进来,会一直存入该队列,而不会去创建新线程直到maxPoolSize,因此使用该工作队列时,参数maxPoolSize其实是不起作用的。public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));}创建单个线程。它适用于需要保证顺序地执行各个任务;并且在任意时间点,不会有多个线程是活动的应用场景。SingleThreadExecutor的corePoolSize和maximumPoolSize被设置为1,使用无界队列LinkedBlockingQueue作为线程池的工作队列。

LinkedBlockingQueueLinkedBlockingQueue 获取任务来执行。**使用场景:**适用于串行执行任务场景
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory);}corePoolSize等于maximumPoolSize,所以线程池中只有核心线程,使用无界阻塞队列LinkedBlockingQueue作为工作队列
FixedThreadPool是一种线程数量固定的线程池,当线程处于空闲状态时,他们并不会被回收,除非线程池被关闭。当所有的线程都处于活动状态时,新的任务都会处于等待状态,直到有线程空闲出来。

corePoolSize,则创建新线程来执行任务。corePoolSize后,将新任务放到LinkedBlockingQueue阻塞队列中。LinkedBlockingQueue获取任务来执行。使用场景:适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());}核心线程数为0,总线程数量阈值为Integer.MAX_VALUE,即可以创建无限的非核心线程
执行流程
SynchronousQueue的offer方法提交任务,并查询线程池中是否有空闲线程来执行SynchronousQueue的poll方法来移除任务。如果有,则配对成功,将任务交给这个空闲线程SynchronousQueue的poll方法等待执行SynchronousQueue中新提交的任务。若等待超过60s,空闲线程就会终止

使用场景:执行大量短生命周期任务。因为maximumPoolSize是无界的,所以提交任务的速度 > 线程池中线程处理任务的速度就要不断创建新线程;每次提交任务,都会立即有线程去处理,因此CachedThreadPool适用于处理大量、耗时少的任务。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize);}public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue());}线程总数阈值为Integer.MAX_VALUE,工作队列使用DelayedWorkQueue,非核心线程存活时间为0,所以线程池仅仅包含固定数目的核心线程。
两种方式提交任务:
scheduleAtFixedRate: 按照固定速率周期执行
scheduleWithFixedDelay:上个任务延迟固定时间后执行
使用无界队列的线程池会导致内存飙升吗?
会的,newFixedThreadPool使用了无界的阻塞队列LinkedBlockingQueue,如果线程获取一个任务后,任务的执行时间比较长,会导致队列的任务越积越多,导致机器内存使用不停飙升, 最终导致OOM。
注意:要用ScheduledExecutorService去创建ScheduledThreadpool,如果用Executor去引用,就只能调用Executor接口中定义的方法;如果用ExecutorService接口去引用,就只能调用ExecutorService接口中定义的方法,无法使用ScheduledExecutorService接口中新增的方法,那么也就失去了这种线程池的意义
第一种方式,构建一个线程池
ExecutorService threadPool = Executors.newFixedThreadPool(10);
第二种方式,使用ThreadPoolExecutor构建一个线程池
import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.ExecutorService;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;public class test { public static void main(String args[]) { ExecutorService executorService = new ThreadPoolExecutor(5,10, 10,TimeUnit.SECONDS,new ArrayBlockingQueue<Runnable>(5)); executorService.execute(new Runnable() { @Override public void run() { System.out.println("开始执行线程池中的任务"); } }); }}如果只是简单的想要改变线程名称的前缀的话可以自定义ThreadFactory来实现,在Executors.new…中有一个ThreadFactory的参数,如果没有指定则用的是DefaultThreadFactory。
第三种方式,使用工具来创建线程池,Apache的guava中ThreadFactoryBuilder()来创建线程池,不仅可以避免OOM问题,还可以自定义线程名称,方便出错时溯源
为什么不建议使用Executors创建线程,而使用ThreadPoolExecutor实现类来创建线程?
Executors中FixedThreadPool使用的是LinkedBlockingQueue队列,近乎于无界,队列大小默认为Integer.MAX_VALUE,几乎可以无限制的放任务到队列中,线程池中数量是固定的,当线程池中线程数量达到corePoolSize,不会再创建新的线程,所有任务都会入队到workQueue中,线程从workQueue中获取任务,但这个队列几乎永远不会满,只要队列不满,就不会再去创建新的线程,就跟maximumPoolSize和keepAliveTime没有关系,此时,如果线程池中的线程处理任务的时间特别长,导致无法处理新的任务,队列中的任务就会不断的积压,这个过程,会导致机器的内存使用不停的飙升,极端情况下会导致JVM OOM,系统就挂了。
总结:Executors中FixedThreadPool指定使用无界队列LinkedBlockingQueue会导致内存溢出,所以,最好使用ThreadPoolExecutor自定义线程池
换一种问法:线程池中,无界队列导致的内存飙升问题,同上
线程池如何调优
(1)首先,根据不同的需求选择线程池,如果需要单线程顺序执行,使用SingleThreadExecutor,如果已知并发压力,使用FixedThreadPool,固定线程数的大小,执行时间小的任务,可以使用CachedThreadPool,创建可缓存的线程池,可以无限扩大线程池,可以灵活回收空闲线程,最多可容纳几万个线程,线程空余60s会被回收,需要后台执行周期任务的,可以使用ScheduledThreadPool,可以延时启动和定时启动线程池,
(2)如何确认线程池的最大线程数目,分CPU密集型和IO密集型,如果是CPU密集型或计算密集型,因为CPU的利用率高,核心线程数可设置为n(核数)+1,如果是IO密集型,CPU利用率不高,可多给几个线程数,来进行工作,核心线程数可设置为2n(核数)
线程池适合单系统的大量的异步任务处理,比如发送短信、保存日志等。
1、几个真实的场景中如何选择线程池?
(1)高并发、任务执行时间短,此类任务可用充分利用CPU,尽可能的减少上下文切换,线程池的线程数可用设置为CPU核数+1
(2)并发不高、任务执行时间长
此种类型的任务分两种情况:
① IO密集型的任务,业务长时间集中在IO操作上,因为IO操作并不占用 CPU,所以尽可能的不要让所有的CPU闲下来,可用加大线程池中的线程数目,让CPU处理更多的业务,如设置线程池的线程数为2 * CPU核数
② 计算密集型的任务,业务长时间集中在计算操作上,和(1)一样,线程数可设置为CPU核数+1,减少一下线程数,以便减少线程的上下文切换
(3)并发高、业务执行时间长,这种类型的任务就不单单要关注线程池了,而是要从整体架构上来考虑,看能否使用中间件对任务进行拆分和解耦,部分数据做缓存处理,以及增加服务器等
2、线程池参数设置的一些分析
(1)几个参数:
tasks:每秒的任务数,假设为500~1000
taskcost:每个任务花费的时间,假设为0.1s
responsetime:系统允许容忍的最大响应时间,假设为1s
(2)做几个计算:
① corePoolSize:每秒需要多少个线程处理
threadcount = tasks/(1/taskcount) = (500~1000)*0.1 = 50~100
线程数应该设置为大于50个,根据8020原则,如果80%的每秒任务数 小于800,那么corePoolSize设置为80即可
② queueCapacity = (coreSizePool/taskcost)responsetime = 80/0.11 = 80
③ 注意阻塞队列的大小,LinkedBlockingQueue的大小为Integer.MAX_VALUE,接近于无界,会导致内存溢出,因为当任务徒增 时,都会进入队列中,不能开新的线程来执行
④ maxPoolSize = (max(tasks) - queueCapacity)/(1/taskcount)=(最大 任务数-队列容量)/每个线程每秒处理能力 = 最大线程数,计算可得,最大线程数maxPoolSize = (1000-80)/10 = 92
⑤ rejectedExecutionHandler:根据具体情况来决定,任务不重要可丢弃,任务重要则要利用一些缓冲机制来处理
⑥ keepAliveTime和allowCoreThreadTimeout:采用默认通常能满足
3、几个具体场景的分析(8核CPU为例)
(1) 任务数多但资源占用不大,电商平台的消息推送或短信通知,该场景需要被处理的消息对象内容简单占用资源非常少,通常为百字节量级,但在高并发访问下,可能瞬间产生大量的任务数,而此类任务的处理通常效率非常高,因此处理的重点在于控制并发线程数,不要以为大量的线程启用及线程的上下文频繁切换而导致内存使用率过高,CPU的内核态使用率过高等不良情况发生,通常可以在创建线程池时设置较长的任务队列,并以CPU内核数2-4倍(经验值)的值设置核心线程与扩展线程数,合理固定的线程数使得CPU的使用率更加平滑,如:
BlockingQueue queue = new ArrayBlockingQueue<>(4096);ThreadPoolExecutor executor = newThreadPoolExecutor(16, 16, 0, TimeUnit.SECONDS, queue);(2) 任务数不多但资源占用大,非社交流媒体的使用场景下,该情况多发生于文件流、长文本对象或批量数据加工的处理,如日志收集、图片流压缩或批量订单处理等场景,而此类场景下的单个资源处理,往往会发生较大的资源消耗,因此为使系统达到较强处理能力,同时又可以控制任务资源对内存过大的使用,通常可以在创建线程池时适当加大扩展线程数量,同时设置相对较小的任务队列长度,如此,当遇到任务数突增的情况,可以有更多的并发线程来应对,此外需要合理设置扩展线程空闲回收的等待时长以节省不必要的开销,如:
BlockingQueue queue = new ArrayBlockingQueue<>(512);ThreadPoolExecutor executor = new ThreadPoolExecutor(16, 64, 30, TimeUnit.SECONDS, queue);(3) 极端场景的情况,如遇到任务资源较大,任务数较多,同时处理效率不高的场景,首先需要考虑任务的产生发起需要限流,理论上讲为保障系统的可用性及稳定运行,任务的发起能力应当略小于任务的处理能力,其次,对于类似场景可以采用以时间换取空间的思想,充分利用系统计算资源,当遇到任务处理能力不足的情况,任务发起方的作业将被阻塞,从而充分保护系统的资源开销边界,但可能会导致CPU核心态的使用率高,如:
BlockingQueue queue = new SynchronousQueue<>();ThreadPoolExecutor executor = new ThreadPoolExecutor(64, 64, 0, TimeUnit.SECONDS, queue);CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。
在多重程序系统中,大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部份时间用在三角函数和开根号的计算,便是属于CPU bound的程序。
CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高。
I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。
我们可以把任务分为计算密集型和IO密集型。
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
总之,计算密集型程序适合C语言多线程,I/O密集型适合脚本语言开发的多线程。
]]>show VARIABLES like ‘%character%’
1.1.1 修改默认的字符集
前往/mydata/mysql/conf,添加my.cnf文件:
[mysqld]
character_set_server=utf8
然后重启mysql
1.1.2 修改已有库表的字符集
use dbtest1;
ALTER DATABASE dbtest1 character set ‘utf8’;
ALTER TABLE user convert to CHARACTER set ‘utf8’;
1.2 Mysql各级别的字符集
Mysql字符集的级别分为4种:层级关系由上到下递增。
服务器级别(修改后也决定数据库的级别)。
数据库级别。
表级别。
列级别。
服务器级别字符集设置,一般我们通过配置文件来进行,例如:
[mysqld]
character_set_server=utf8
数据库级别字符集设置,具体语法如:
create database [数据库名] character set [字符集名称];
alter database [数据库名] character set [字符集名称];
表级别字符集设置,具体语法如:
create table [表名] character set [字符集名称];
alter table [表名] character set [字符集名称];
列级别字符集设置,具体语法如:
create table [表名](
[列名] [字符串类型] [character set xxx],
…,
);
1.2.1 字符集比较规则
utf8和utf8mb4的区别:(我们可以发现Mysql8.0默认字符集为utf8mb4)
utf8:表示一个字符需要使用1~4个字节表示字符。
utf8mb3:缩略版的utf8字符集,只使用1~3个字节表示字符。
utf8mb4:正宗的utf8字符集。使用1~4个字节表示字符。
注意:Mysql中utf8是utf8mb3的别名。若有需求去存储4字节编码一个字符的情况,例如emoji表情,那就需要设置字符集为utf8mb4.
img
我们可以发现第三列Default collation,代表字符集的默认比较规则。
后缀描述
_ai不区分重音
_as区分重音
_ci不区分大小写
_cs区分大小写
_bin以二进制方式比较
重要的几个点:
utf8_general_ci和utf8_unicode_ci对于中英文来说没有什么实质区别。
utf8_general_ci相对而言速度快,但是准确度较差。
utf8_unicode_ci准确度高,但是速度较慢。并且适用于多语言的比较。
1.3 Mysql大小写规范
show VARIABLES like ‘%lower_case_table_names%’
该值有以下三种:
0:大小写敏感。
1:大小写不敏感,创建的表,数据库都是以小写的形式存放在磁盘上。对于sql语句,都是将其转化为小写来进行查找的。
2:创建的表和数据库依据sql语句上的格式来存放,但是查找的话都是根据小写来进行。
MySQL在Windows的环境下全部不区分大小写
Mysql对于linux环境下的大小写规范如下:
数据库名、表名、表的别名、变量名严格区分大小写。
关键字、函数名在SQL中不区分大小写。
列名、列的别名在所有情况下忽略大小写。
在Linux中设置大小写不敏感:
编辑MySQL配置文件(my.cnf或者my.ini),在[mysqld]部分添加或修改以下行:
[mysqld]
lower_case_table_names = 1
重启MySQL服务以应用更改。
二. Mysql文件系统和权限
Mysql的存储引擎我们较为熟知的有InnoDB与MyISAM。这样的存储引擎都是将表存储在磁盘上的。我们将操作系统用来管理磁盘的结构称之为文件系统。
2.1 查看数据库
show DATABASES;
其中有4个数据库是Mysql创建的时候就自带的系统数据库:
mysql:核心数据库,存储了Mysql的用户和权限信息、存储过程、事件的定义等。
information_schema:保存着Mysql服务器维护的其他数据库的信息,例如有哪些表、视图、触发器、索引等等。
performance_schema:保存Mysql服务器运行过程中的状态信息,一般用于监控Mysql的各类性能指标,比如最近执行了哪些语句。执行过程花了多少时间等。
sys:主要通过视图的方式把information_schema数据库和performance_schema数据库结合起来。
以自己创建的dbtest1数据库为例,我们去/var/lib/mysql/data/目录下去查看数据
img
db.opt:存储了dbtest1这个数据库的一些基本信息,如使用的字符集、比较规则等。
user.frm:存储了user这张表的表结构。
user.ibd:存放user这张表中的数据(独立表空间)。
当然,Mysql还有个系统表空间用来存储表数据的:
默认情况下,InnoDB会在数据目录下创建一个名为ibdata1、大小为12M的文件。
在Mysql5.6后,默认就会为每个表建立一个独立的表空间,也就是所谓的xxx.ibd文件。
我们可以自己指定使用系统表空间还是独立表空间。
[server]
innodb_file_per_table=0
小结下就是:若表使用InnoDB存储引擎,一张表会产生1~2个文件:
xxx.frm:描述表结构文件。
若采用系统表空间模式,数据和索引信息存储在ibdata1文件中。
若采用独立表空间模式,则产生xxx.idb文件用于存储数据和索引信息。
在Mysql8.0中,不再单独提供xxx.frm文件,而是将其整合到xxx.idb文件中了。
若采用MyISAM存储引擎:一张表会产生3种文件
Mysql5.7中:xxx.frm文件。Mysql8.0中:xxx.sdi文件。两者都是用来描述表结构和字段长度的。
xxx.MYD文件:数据信息文件。
xxx.MYI文件:存储索引信息文件。
2.2 用户管理和权限
Mysql的登录命令如下:
mysql -h hostname -p port -u username -p databaseName -e “SQL语句”
用户的权限查看:
show PRIVILEGES;
授予权限原则:
只授予能够满足需要的最小权限。
创建用户的时候限制用户的登录主机,一般指定IP。
为每个用户设置有一定复杂度的密码。
定期清理不需要的用户。
授权命令:
grant [权限1],[权限2] on [数据库名称 | *].[表名 | *] to [用户名]@[用户地址]
create user ‘hss’ IDENTIFIED by ‘000000’;
GRANT SELECT ,INSERT on dbtest1.student to ‘ljj’@‘%’;
倘若某个用户被删除,那么我们需要回收对应的权限,命令如下:
revoke [权限1],[权限2] on [数据库名称 | *].[表名 | *] from [用户名]@[用户地址]
2.2.1 Mysql访问控制
用户在操作Mysql的时候,Mysql首先会核实该用户对应的操作请求是否被允许,而这个过程叫做访问控制过程。分为两个阶段:
连接核实阶段。
请求核实阶段。
连接核实阶段:
客户端用户在连接请求的时候,会提供用户名、主机地址、密码等信息。
Mysql服务器接收到用户的请求,使用user表中的host、user、authentication_string这三个字段来匹配客户端提供的信息。
只有三者都匹配,服务器才接受连接。若连接核实阶段不通过,服务器就会拒绝访问。 此时进入下一个阶段。
请求核实阶段:
Mysql首先检查user表,若指定的权限没有在user表中被授予,此时检查db表。
db表中的权限限制于数据库层级。该层级中的SELECT权限允许用户查看置顶数据库的所有表数据。
若db表中依旧没有找到权限,则检查tables_priv表以及columns_priv表。
若以上表都没找到对应权限,则返回错误信息,用户请求无法执行。操作失败。
三. Mysql执行流程
img
3.1 查询缓存
客户端发送一个请求的时候,Mysql会先去缓存中去寻找这条SQL语句。
若缓存查询中有,则直接将结果返回给客户端。
若缓存中没有,那么进入下一个阶段解析器阶段。
值得注意的是:查询缓存的效率并不高,因此Mysql8.0之后抛弃了这个功能。
缓存的形式:Key-Value。
Key:执行过的语句。
Value:对应语句的结果、
那么为什么查询缓存的效率不高呢?原因有三点:
只有相同的查询操作才会命中查询缓存。若两个查询请求有任何字符上的不同(空格、字符、大小写等),都会导致缓存不会命中,因此Mysql的查询缓存命中率并不高。
若查询请求中包含某些系统函数、用户自定义变量和函数或者查询系统表。那么该请求不会被缓存。例如函数NOW,每次调用都会产生不同的结果,那么这样的SQL语句是不会被加入到查询缓存当中的。
缓存有失效时间,Mysql的缓存系统会涉及到每张表。但是只要该表的结构或者数据被修改(Insert、Update、Delete)等操作,那么该表相关的高速缓存查询都会置为无效并从缓存中删除。因此对于更新操作频繁的数据库来说, 查询缓存的命中率低的不行。
那么什么样的情况适合使用查询缓存呢?
3.1.1 静态表
如果我们有一些表,基本上不会涉及到更新,比如系统配置表、字典表等。那么我们可以在这张表的查询上使用查询缓存。
如何开启?在my.cnf配置文件中添加:
query_cache_type=2
query_cache_type有3个值:
0:代表关闭查询缓存。
1:代表开启。
2:DEMAND,只有sql语句中有SQL_CACHE关键词的时候才缓存。
例如我希望对以下SQL进行缓存:
select SQL_CACHE * from config where id = 3;
查看当前数据库是否使用查询缓存:
show VARIABLES like ‘%query_cache_type%’
监控查询缓存的命中情况:
show status like ‘%Qcache%’
img
Qcache_free_blocks:空闲的block数量,数值越大,代表缓存中的碎片越多。
Qcache_free_memory:缓存大小。
Qcache_lowmem_prunes:有多少条缓存是因为内存不够而命中不到。若值比较大,说明需要增加查询缓存的内存大小。
Qcache_not_cached:表示因为query_cache_type参数的设置而没有命中查询缓存的次数。
Qcache_hits:表示有多少次命中缓存。数字越大,效果越理想。
Qcache_inserts:表示多少次未命中缓存然后将结果插入到缓存中的情况。
在查询缓存阶段结束后,就该进入解析器解析阶段了。
3.2 解析器解析
这一阶段,Mysql的目的是需要知道传入的SQL语句是要做什么事情,因此需要对其做词法、语法的分析。
词法分析中:
比如分析select关键字,那么此时该SQL是一条查询语句。
将字符串xxx识别成表名xxx,找到对应的表。
列id的识别等。
语法分析中:
主要是根据语法规则,判断输入的这个SQL语句是否满足Mysql的语法。
倘若SQL语句正确,那么此时会生成一个语法树:
img
3.3 优化器解析
该阶段主要是是确定SQL语句的执行方式, 比如:是全表搜索,还是索引检索。
一条查询语句可以有很多种执行方式,最后都返回相同的结果,而优化器的作用就是找到最优的执行方案。
例如:
一张表中有多个索引,优化器决定使用哪个索引。
一个语句中有多表关联join的时候,优化器决定各个表的连接顺序。
表达式优化。子查询转为连接等。
而优化又分为两个阶段:
逻辑查询优化:通过索引和表连接等方式来优化。
物理查询优化:通过SQL等价变化来提升查询效率,即用最优的SQL写法来替代。
3.4 执行器
到这里为止,Mysql服务器已经有了一个执行计划,准备交给执行器来执行。
本阶段主要是调用存储引擎的API对表进行读写操作(在有权限的前提下)
总结下执行流程就是:
SQL语句。
分析器进行语法分析和语义检查。生成对应的语法分析树。
此时进入优化器,进行逻辑和物理优化。生成查询计划。
交给执行器来执行。
生成查询结果。
3.5 查询缓存的使用案例
此时我们如果打开Mysql5.7的查询缓存功能(8.0该功能已抛弃),在配置文件my.cnf中添加属性
query_cache_type=1
然后重启mysql
此时在查看查询缓存的启用情况:
img
确认profiling是否开启,开启它后可以让Mysql收集在SQL执行时所使用的资源情况。
若你的值为0,代表关闭,可以使用命令将其临时开启:
同时在设置以下profiling:
set @@profiling=1;
同样我们执行两边相同的SQL语句,例如:
select name from user where id =1
然后查看SQL执行过程:
show PROFILES;
img
此时我们查看下详情
show PROFILE;
show PROFILE for query 4;
img
第二次查询:
img
我们可以发现:
第一次查询,最后将查询结果加入到了查询缓存中。
第二次查询,查询结果是直接从查询缓存中返回的。
四. 存储引擎
对于Mysql而言。SQL的执行流程这一类不涉及到真实数据存储的功能将其划分为Mysql Server。
而存储数据的功能划分为存储引擎
查看当前的Mysql提供什么存储引擎,命令如下:
show ENGINES;
img
Transaction代表:当前存储引擎是否支持事务。
XA代表:是否支持分布式事务。
Savepoints:是否支持保存点。
Mysql在5.5之前默认的存储引擎为MyISAM,在之后呢,则默认为InnoDB引擎。
4.1 InnoDB引擎和MyISAM引擎的区别
InnoDB的亮点用一句话来说就是:具备外键支持功能的事务存储引擎。
对比MyISAM,InnoDB写的处理效率要差一点,并且占用更多的磁盘空间来保存数据和索引。
MyISAM只缓存索引,不缓存真实数据。InnoDB两者都缓存,因此对内存的要求比较高。
事务方面:InnoDB支持,MYISAM不支持。即崩溃后可以通过事务来回滚。
行表锁:InnoDB支持行锁,操作时只锁一行,不会对其他行有影响,适合高并发。MyISAM支持表锁,不适合高并发。
MyISAM针对数据的统计有额外的常数存储,因此使用count(*)的查询效率很高。
MyISAM数据文件结构:.frm存储表结构,.MYD存储数据,.MYI存储索引。InnoDB数据文件结构:frm(Mysql8.0后整合到ibd文件中了),ibd存储索引和数据。
4.2 索引
Mysql中使用索引,目的是为了减少磁盘的IO次数,加快查询效率。Mysql中对索引的定义为:索引是帮助Mysql高效获取数据的数据结构。
索引的本质是数据结构,满足特定的查找算法,这些数据结构以某种方式指向数据,因此可以在这些数据结构的基础上实现高效查找算法。
索引的优点:
类似图书馆检索,提高数据检索的效率,降低数据库IO成本。
创建唯一索引,保证数据库表中每行数据的唯一性。
加速表和表之间的连接。
在使用分组和排序的时候,可以显著减少查询中分组和排序的时间,降低CPU的消耗。 (建立索引的时候,已经保证数据有效,那么order by排序的时候,效率当然很高)
索引的缺点:
创建和维护索引需要消耗时间。数据量越高,维护的成本越大。
索引需要占用磁盘空间。
索引大大提高查询速度,但是也降低了更新表的速度,对于表数据的删除,增加,索引也需要动态地维护。
现在来看下索引的一些常见概念。
4.2.1 聚簇索引
一种数据存储方式(所有的记录存储在叶子节点),也就是索引即数据,数据即索引。通俗点就是主键。
聚簇的概念:表示数据行和相邻的键值聚簇的存储在一起。
特点:
使用记录主键值的大小进行记录和页的排序,含义:
页内的记录是按照主键的大小顺序排序成一个单向链表。
各个数据页之间则根据页中记录的主键大小顺序排成双向链表。
数据页的相关信息又由目录项记录,分为不同的层次,同一个层次中的页根据页中目录项纪录的主键大小排成双向链表。
B+树的叶子节点,存储的是完整的用户记录。
优点:
数据访问更快。因为聚簇索引将索引和数据保存到同一个B+树中。
聚簇索引对于主键的排序和范围查找速度很快。
按照聚簇索引排序,进行范围查找的时候,由于数据之间紧密相连,因此数据库不用从多个数据块中去提取数据,节省大量IO操作。
缺点:
插入速度严重依赖插入的顺序,按照主键的顺序插入是最快的,否则容易出现页分裂,严重影响性能。因此InnoDB表,一般会定义一个自增ID作为主键。
更新主键的代价高,因为这样的操作会导致行移动。因此一般我们定义主键为不可更新。
二级索引访问需要两次索引查找。第一次找到主键值,第二次根据主键值找到行数据。
限制:
MyISAM不支持聚簇索引。
由于数据物理存储排序方式只能有一种,因此每个表最多只能有一个聚簇索引。
若没有定义主键,InnoDB会选择非空的唯一索引来代替。若不存在这样的索引,InnoDB会隐式定义一个主键作为聚簇索引。
聚簇索引的B+树结构图如下:
img
注意:
最下层的叶子节点,存储的数据都是真实的用户数据(按照主键大小排序)
4.2.2 非聚簇索引
如果除了主键,我们还希望以别的列作为搜索条件,那么这个时候可以多建几颗B+树。也就是非聚簇索引,也可以说是二级索引。
结构图如下:假设我们以列c2作为非聚簇索引。
img
在非聚簇索引的B+树结构图中,可以发现和聚簇索引结构有这么几个不同:
比较内容聚簇索引非聚簇索引
页内的记录(记录之间单项链表)按照什么排序?按照主键c2列的大小
存放用户记录的页(页和页之间双向链表),按照页中的什么来排序?主键c2列的大小
存放目录项记录的页,同一个层次(双向链表连接),按照页中目录项记录的什么来排序?主键c2列的大小
重点:B+树的叶子节点存储的数据主键+完整的用户数据c2列的值+主键
也因此:
如果我们根据非聚簇索引去查找某个用户的所有数据,找到了B+树当中的叶子节点的某条记录。
由于非聚簇索引叶子节点存储的是 (非聚簇索引对应的值+ 主键),此时并不包含用户相关的数据。
因此还需要根据主键,来再进行一次查询。
而步骤三的这个过程,也就是所谓的 回表。也就是说,根据非聚簇索引去查询一个用户的完整信息,需要用到两颗B+树,进行2次查询。
问题:为什么需要进行回表操作呢?干脆把用户信息也存储到非聚簇索引的叶子节点上不就好了。
回答:
首先,用户数据所占的内存空间较大,占存储资源。
而且一张表可以有多个非聚簇索引,那么如果一张表有10个非聚簇索引,那等于有11颗B+树(包括主键的)的叶子节点都存储了用户信息,这不就重复了吗?
4.2.3 联合索引
即同时以多个列的大小作为排序规则。比如让B+树以c2和c3列的大小进行排序:
此时会将各个记录和页按照c2列进行排序。
在记录的c2列相同的情况下,再根据c3列进行排序。
联合索引本质上和非聚簇索引一样,叶子节点存储的记录,以上面为例就是c2+c3+主键构成。
需要注意的点就是:
为c2列和c3列建立联合索引,只会建立一颗B+树。
为c2列,c3列建立非聚簇索引,会建立两颗B+树。
4.3 InnoDB中B+树索引的注意事项
第一点:根页面(B+树根节点)万年不动,InnoDB中B+树的数据结构是通过该根节点不断的进行页分裂得来的。
形成过程如下:
每当为表创建一个B+树索引,都会创建一个根节点页面。随后向表中插入记录时,先将用户记录存储到根节点中。
当根节点中的可用空间用完的时候,此时再插入记录。会将根节点中的所有记录复制到一个新分配的页,例如页A。
然后对这个A进行页分裂,得到另一个新页B。
此时新插入的记录会根据键值的大小,分配到页A或者页B中,而根节点升级为存储目录项记录的页。
以此类推,不断分裂,形成一层层的节点,形成B+树。
第二点:内节点中目录项记录的唯一性。
第三点:一个页中最少存储2条记录。
4.4 MyISAM索引实现
MyISAM引擎也是用B+树来作为索引结构的,不过其叶子节点保存的数据是数据记录的地址。
MyISAM索引原理:
首先我们知道MyISAM将索引和数据分开存储。将表中的记录按照记录的插入顺序单独存储一个文件中(数据文件)。而数据文件并不会划分为若干个数据页,也不会按照主键大小进行排序(按照插入顺序)。所以查找的时候不能在这样的数据结构上使用二分查找。
使用MyISAM的表将索引信息存储到一个专门的索引文件。MyISAM会单独为表的主键创建一个索引,其叶子节点存储的是主键值+数据记录地址。
img
4.4.1 MyISAM和InnoDB对比
MyISAM的索引存储都是非聚簇的(毕竟不是直接保存的数据本身),而InnoDB中包含一个聚簇索引。
在InnoDB中,只需要根据主键值进行一次查找就能找到对应的记录。而MyISAM中,需要进行一次回表操作。
InnoDB的数据文件本身就是索引文件,而MyISAM的索引文件和数据文件是分离的。
InnoDB的非聚簇索引叶子节点的data域存储的是记录的主键值,而MyISAM中存储的是数据的存储地址。
MyISAM的回表操作非常快,因为拿着地址的偏移量直接到文件中读取数据。而InnoDB中是通过获取主键之后,再去B+树进行查找。(比不过直接用地址去访问)
4.4.2 根据存储引擎的实现来优化索引
不建议使用过长的字段作为主键。 原因:所有非聚簇索引都引用了主键索引,过长的主键索引会导致非聚簇索引变得过大。
使用自增字段作为主键。 原因:InnoDB数据存储结构为一颗B+树,非单调的主键插入时,会导致数据文件为了维持B+树的特性而频繁的分裂调整。十分低效。
五. InnoDB数据存储结构
InnoDB是Mysql的默认存储引擎,因此着重学习InnoDB的数据存储结构。
5.1 页
页是磁盘和内存交互的一个基本单位。InnoDB中将数据划分为若干页,而默认大小为16KB。
一次最少从磁盘中读取16KB的内容到内存中。
一次最少把内存中的16KB内容刷新到磁盘中。
在数据库中,不论是读取一行,还是读取多行,都是将这些数据行所在的页进行加载。 因为数据库管理存储空间的基本单位是页,数据库IO操作的最小单位也是页。
页结构(Block)概述:页与页之间可以不在物理结构上相连,只通过双向链表关联即可。每个页中的记录则按照主键值大小顺序组成单向链表。每个数据页都会为存储在里面的记录生成一个页目录,通过主键查找的时候使用二分法进行定位。
img
可以使用命令来查看数据库页的大小:
show VARIABLES like ‘%innodb_page_size%’
5.1.1 页的上层结构
在页外还存在着以下几种结构:
区(Extent):一个区会分配64个连续的页,因此一个区的大小为1MB。
段(Segment):段由一个或者多个区组成,段作为数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。
表空间(Tablespace):一个段只能属于一个表空间,数据库由一个或者多个表空间组成,表空间从管理上可分为系统表空间、用户表空间、撤销表空间、临时表空间。
数据行:页中的一条条数据。
回顾Tip:
InnoDB中采用系统表空间模式:数据信息和索引信息存储到ibdata1中。
采用独立表空间模式:data目录下中产生xx.ibd文件。
结构图如下:
img
其中,区有4种类型:
空闲区 FREE:没有用到该区的任何页。
有剩余空间的碎片区 Free_FRAG:表示碎片区中存在可用的页。
没有剩余空间的碎片区 FULL_FRAG:碎片区中的所有页都被使用。
附属于某个段的区 FSEG:每一个索引都会生成叶子节点段(数据段)和非叶子节点段(索引段)。那么这两个段附属于该索引。
问题1:区存在的意义是什么?
首先背景:
B+树的每一层,页与页之间会形成一个双向链表。如果以页为单位分配存储空间的话,双向链表相邻两个页之间的物理位置可能离得非常远。
在我们进行索引的范围查找的时候,一般是定位到最左边的记录和最右边的记录,然后沿着双向链表进行扫描。
若链表中相邻页的物理位置隔得很远,那么此时扫描就成了随机IO。随机IO的效率远远不及顺序IO。
因此引入区解决这样的问题:
一个区在物理位置上有64个连续的页,也就是1MB。表中数据量大的时候,不再以页为单位分配空间了,而是以区为单位进行分配。
区的目的就是消除了大量的随机IO的发生。
问题2:段存在的意义是什么?
背景:
范围查找的时候,也就是对B+树叶子节点的记录进行顺序扫描。
若不区分叶子节点和非叶子节点,都将其对应的页放入到申请的区中的话,范围扫描的效率就很低了。
因此引入段的概念:
对B+树的叶子节点和非叶子节点进行区别对待。叶子节点有自己的区,非叶子节点有自己的区。
而存放叶子/非叶子节点的区的集合就是一个段, 也就是一个索引会生成2个段。
常见的段有:回滚段,数据段(叶子节点),索引段(非叶子节点)。
注意:段并不是一个连续的物理区域,而是一个逻辑上的概念。一个段可能由若干个零散的页和完整的区构成。
问题3:什么是碎片区?
背景:
一个表使用InnoDB存储引擎,最多一个聚簇索引。一个索引生成2个段。(数据段和索引段)
段以区为单位申请存储空间,一个区=1MB,那么一张表=2个段=2MB。
但是如果一个只存储了几条数据的小表,也需要2MB的存储空间吗?
为了考虑以完整的区为单位分配给某个段,但是数据量较小的表太浪费存储空间的这种情况。引入碎片区的概念:
一个碎片区中,里面的页可以用于不同的目的,来自不同的段。甚至不属于任何段。
碎片区直属于表空间。
因此Mysql为某个段分配存储空间的策略如下:
刚开始向表中插入数据的时候,段是从 某个碎片区 的 单个页 为单位来分配内存空间。
当段已经占用了32个碎片区页面之后,就会申请完整的区为单位来分配存储空间。
5.1.2 页的内部结构
页其实也有类型的划分:
数据页(保存B+树节点)。
系统页。
Undo页。
事务数据页。
其中数据页是我们最常用和接触最多的,其中16KB大小的存储空间划分为七个部分:
文件头:占用38字节,描述页的信息。
页头:占用56字节,描述页的状态信息。
最大最小记录:占用26字节,最大和最小记录(虚拟的行记录)。
用户记录:存储行记录内容。
空闲空间:页中还没有被使用的空间。
页目录:存储用户记录的相对位置。
文件尾:校验页是否完整。
img
一般分为三个部分:
第一部分:校验完整性部分
File Header 文件头:保存了页的编号、页的类型、 还有两个指针指向前后页(双向链表)。当前页的校验和,页最后被修改时对应的日志序列位置LSN。
校验和:对于一个很长的字符串,通过某种算法计算出一个比较短的值来代表该字符串,这个较短的值就是校验和。
若两个字符串之间的比较,其校验和不一致,那么两个字符串本身就是不一样的。
那么Mysql中的校验和有什么用?
检验一个页是否完整(同步过程发生中断),此时通过比较文件尾的校验和和文件头的校验和。
若两个值不一致或者文件头尾的LSN不一致,说明页的传输有问题。
一般来说,一个页面在内存中修改,在同步之前就会将其校验和计算出来,因为文件头会先写入磁盘。
File Trailer 文件尾:保存了页的校验和、以及页最后被修改时对应的日志序列位置LSN。
第二部分:数据记录部分
Free Space 空闲空间:每当插入一条记录,都会从空闲空间中申请一个记录大小的空间,划分到User Records部分。当空闲空间全部被用完,此时需要申请新的页。
User Records 用户记录:按照指定的行格式,一条条地摆在User Records 部分,记录之间以单链表的形式关联。
Infimum+Supremum 最小最大记录:即主键的最小最大值。其实是个虚拟节点(详见下文行格式章节中的记录头信息部分)
img
第三部分:目录和头部分
Page Directory 页目录
会将所有的记录分成多个组,包括最小和最大记录,但是不包括标记为已删除的记录。
第一组,只包含最小记录。
最后一组,即最大记录所在的分组,有1-8条记录。
其余的组的数量在4-8条之间。
而每个组的最后一条记录的记录头信息,会存储改组有多少条记录。
其中,每个组的地址偏移量,称之为槽。
Page Header 页头部:
用于记录每个数据页中存储的记录状态信息。
保存了本页有多少条记录、第一条记录的地址,页中有多少个槽(组)等信息。
5.1.3 从数据页的角度来看B+树的查询原理
一颗B+树按照节点类型分为两个部分:
叶子节点:B+树的最底层节点,高度为0,存储行记录。
非叶子节点:节点高度大于0,存储索引键和页的指针。
问题1:B+树是如何进行记录检索的?
回答:
若通过B+树的索引来查询,从根开始,逐层检索,直到找到叶子节点。
即找到对应的数据页,此时将页加载到内存中。
页目录中的槽,采用二分查找的方式找到一个记录分组。
在分组中通过链表遍历的方式查找记录。
5.2 数据行
我们插入到数据库中的数据都是以行为单位,这些记录在磁盘上的存储方式称之为行格式。 InnoDB提供了4种不同类型的行格式:
Compact。
Redundant。
Dynamic。
Compressed。
查看数据库默认的行格式:
show VARIABLES like ‘%innodb_default_row_format%’
指定行格式:
create table user2(id int,name VARCHAR(10)) row_format=compact;
show table status like ‘user2’
5.2.1 Compact 行格式
Compact 行格式下,一条完整的记录可以被分为4大部分:
变长字段长度列表。
Null值列表。
记录头信息。
记录的真实数据。
第一部分:变长字段长度列表
什么叫变长字段呢?
诸如varchar,varbinary,text等类型。这种字段中存出多少个字节的数据并不是固定的,因此在存储真实数据的时候,需要将这些数据占用的字节数保存下来。
第二部分:Null值列表
将可以为Null的列统一管理起来,形成个列表。存储格式如下:
二进制位的值为1:该列的值为null。
二进制为的值为0:该列的值不为null。
第三部分:记录头信息
记录头信息:
img
此时插入3条数据后
img
记录头信息中包含:
delete_mark:标记着当前记录是否被删除。0代表没有,1代表被删除。
min_rec_mark:B+树每层非叶子结点中的最小记录都会有这个标记,为1。
record_type:表示当前的记录类型。0:普通记录。1:表示B+树非叶子节点记录。2:最小记录。3:最大记录。在回顾下上文的图:img
heap_no:表示当前记录在本页当中的具体位置。
n_owned:页目录中每个组的 最后一条记录的头信息会存储该组有多少条记录,作为n_owned字段。
next_record:当前记录到下一条记录的地址偏移量。(行记录之间通过该字段来形成单链表的结构)
问题1:为什么被删除的记录不是直接删掉,而是通过delete_mark去记录删除标记呢?
回答: 因为移出某条数据之后,其他记录在磁盘上就需要重新排列,导致性能消耗。实际上,所有被删除的记录会组成一个垃圾链表,在这个链表所占用的空间叫做可重用空间,之后有新记录插入到表中的时候,会进行空间的替换。
问题2:为什么记录的位置,以上面案例图为例,为何从2开始,记录0和1呢?
回答:Mysql会自动给每个页都添加两个记录,其作为伪记录,分别代表最小记录和最大记录。其heap_no值分别为0和1。
第四部分:记录的真实数据
该部分,除了我们自定义的一些用户真实数据列。还会有3个隐藏列:
row_id:行id,唯一标识。
transation_id:事务id。
roll_pointer:回滚指针。
5.2.2 Dynamic/Compressed 行格式
首先先来讲个概念:
行溢出:InnoDB可以将一条记录中的某些数据存储在真正的数据页面之外。
下面我们用个案例来表述什么是行溢出。例如,我们创建一张表:
CREATE TABLE varchar_size_demo (
c VARCHAR ( 65535 )
) charset = ASCII row_format = compact;
结果如下,报错:
img
首先我们可以发现,Varchar类型的字段,其大小最高是65535,那我指定的也是65535,也没超过限制,为啥报错呢?我们将其改成65532试试:
img
可见成功了
原因是什么呢?
首先Varchar类型的字段最大是65535字节。
创建一个65532字节,创建成功。此时此刻的公式为。
65535 = 65532 + 2个字节的变长字段的长度 + 1字节的Null标识
比如:我们如果指定了Not Null,那么此时可以再多一个字节用来保存数据。
CREATE TABLE varchar_size_demo1 (
c VARCHAR ( 65533 ) not null
) charset = ASCII row_format = compact;
我们知道,一个页的大小是16KB,也就是16384字节,但是一张表的Varchar类型,最多可以存储65533个字节,这样会出现一个数据页存放不了一条记录,这种现象也就是行溢出。
在Compact和Reduntant行格式中,对于这类数据,在记录真实数据的时候,只会存储该列的一部分数据,剩余的部分则分散存储在其他的几个页中进行分页存储。
Dynamic/Compressed行格式对于处理行溢出有着不同的操作:
Dynamic/Compressed两种行格式,对于这种超大的数据,采用完全行溢出的方式。记录真实数据的时候,只记录(存储了溢出的数据的页)页地址指针。
Compressed还有个功能:存储的行数据会以zlib算法进行压缩。
5.2.3 Reduntant 行格式
不同于Compact行格式,Reduntant的首部是一个字段长度偏移列表(Compact是变长字段长度列表)。
img
Reduntant行格式的记录头信息与Compact相比有这么几个不同:
Reduntant中,多了两个字段n_fields和1byte_offs_flag,分别存储记录中列的数量、字段长度偏移链表每个列对应的偏移量。
Reduntant中没有record_type属性。
5.3 数据页加载的三种方式
首先,Mysql在磁盘等物理层面的地方存储,以 数据页 形式进行存放。当其加载到Mysql中,我们称之为 缓存页。
如果缓存池中没有该页数据,那么缓冲池有3种去读取数据。
内存读取:若该数据存在于内存中,执行时间在1ms左右。
随机读取:若数据不存在内存中,则需要在磁盘上对该页进行查找,整体时间大概在10ms左右。其中时间分配大概如下:
6ms:磁盘的实际繁忙时间。
3ms:对可能发生的排队时间的估计值。
1ms:数据传输时间。将页从磁盘服务器缓冲区传输到数据库缓冲区中。
顺序读取:一种批量读取的方式。我们请求的数据在磁盘上往往是相邻存储的。顺序读取帮助我们批量读取页。
六. 索引的设计原则
索引的分类:
从功能逻辑角度,分为4种:普通索引、唯一索引、主键索引、全文索引。
从物理实现方式角度,分为2种:聚簇索引、非聚簇索引。
从作用字段个数角度,分为2种:单列索引、联合索引。
普通索引:可以创建在任何数据类型上,无任何限制。
主键索引:一种特殊的唯一性索引。在其基础上增加了不为空的约束。一张表最多一个主键索引。
单列索引:在表的单个字段上创建索引。
联合索引:在表的多个字段上创建索引。只有查询条件中使用了这些字段的第一个字段才会被使用。遵循最左前缀原则。
全文索引:通过FULLTEXT设置索引为全文索引,允许在这种索引列中插入重复值和控制。该类型的索引只能作用于CHAR、VARCHAR、TEXT及系列类型的字段上。 适用于大型数据集。
6.1 Mysql8.0索引新特性
6.1.1 降序索引
Mysql在4版本的时候就支持降序索引的语法,但是DESC的定义是被忽略的,在Mysql8.0版本才开始真正地支持降序索引,但是仅限于InnoDB引擎。
例如一个查询,需要对多个列进行排序,但是顺序要求并不一致,那么使用降序索引会避免数据库使用额外的文件排序操作,从而提高性能。案例如下:
在Mysql5.7和8.0版本分别创建数据库表(a字段默认升序,b降序)
CREATE TABLE test(a int, b int, index idx_a_b(a,b desc));
Mysql5.7版本:
img
Mysql8.0版本:
img
可以发现Mysql8.0创建的索引已经是降序了,接下来用案例来测试降序索引的效率。分别在两个版本的数据库中插入1000条数据:
DELIMITER //
CREATE PROCEDURE insert1000()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 1000
DO
INSERT INTO test SELECT rand()*80000,rand()*80000;
SET i = i + 1;
END WHILE;
COMMIT;
END //
DELIMITER ;
CALL insert1000() ;
执行查询语句,并且使用Explain 关键词:
EXPLAIN SELECT * from test ORDER BY a,b DESC LIMIT 5;
Mysql5.7版本:
img
Mysql8.0版本:
img
这两者的区别是很大的。Mysql5.7版本的查询结果中的Extra字段中显示了Using filesort值。说明使用了文件内排序的操作,这种操作是非常耗时的,同时检索了1000条记录。而Mysql8.0当中,使用了降序索引,仅仅检索了5条数据。
6.1.2 隐藏索引
Mysql8.0开始支持隐藏索引,只需要将待删除的索引设置为隐藏索引,那么查询优化器就不会再使用这个索引, 这种通过先将索引设置为隐藏索引,再删除索引的方式叫做软删除。
6.2 索引的设计原则
6.2.1 数据准备
测试表准备:
CREATE TABLE student_info (
id INT(11) NOT NULL AUTO_INCREMENT,
student_id INT NOT NULL,
name VARCHAR(20) DEFAULT NULL,
course_id INT NOT NULL,
class_id INT(11) DEFAULTNULL,
create_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY(id)
)ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
CREATE TABLE course (
id INT(11) NOT NULL AUTO_INCREMENT,
course_id INT NOT NULL,
course_name VARCHAR(40) DEFAULT NULL,
PRIMARY KEY(id)
)ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
函数准备:
set global log_bin_trust_function_creators=1;
#函数1:创建随机产生字符串函数
DELIMITER //
CREATE FUNCTION rand_string ( n INT ) RETURNS VARCHAR ( 255 ) #该函数会返回一个字符串
BEGIN
DECLARE
chars_str VARCHAR ( 100 ) DEFAULT ‘abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ’;
DECLARE
return_str VARCHAR ( 255 ) DEFAULT ‘’;
DECLARE
i INT DEFAULT 0;
WHILE
i < n DO
SET return_str = CONCAT(return_str,SUBSTRING( chars_str, FLOOR( 1+RAND ()* 52 ), 1 ));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER;
#函数2:创建随机数函数
DELIMITER //
CREATE FUNCTION rand_num ( from_num INT, to_num INT ) RETURNS INT ( 11 ) BEGIN
DECLARE
i INT DEFAULT 0;
SET i = FLOOR(
from_num + RAND()*(to_num - from_num + 1));
RETURN i;
END //
DELIMITER;
存储过程准备:
DELIMITER //
CREATE PROCEDURE insert_course( max_num INT ) BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务
REPEAT #循环
SET i=i+1; #赋值
INSERT INTO course (course_id, course_name ) VALUES
(rand_num(10000,10100),rand_string(6));
UNTIL i = max_num
END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
DELIMITER //
CREATE PROCEDURE insert_stu( max_num INT ) BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务
REPEAT #循环
SET i=i+1; #赋值
INSERT INTO student_info (course_id, class_id ,student_id ,NAME ) VALUES
(rand_num(10000,10100),rand_num(10000,10200),rand_num(1,200000),rand_string(6)); UNTIL i = max_num
END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
数据插入:
CALL insert_course(100);
CALL insert_stu(1000000);
6.2.2 适合创建索引的情形
字段的数值具备唯一性的特性,此时即使它是组合字段,也必须建立唯一索引。
频繁作为where查询条件的字段。
经常group by和order by的列
注意:联合索引中,根据最左匹配原则,要将已经具有索引的student_id放到前面。
Update、Delete操作中,where条件中的列,也可以添加索引。
如果进行更新的时候,更新的字段是非索引字段,那么此时提升的效率会更明显,因为非索引字段更新的时候不需要对索引进行维护。
Distinct字段需要创建索引。
多表Join连接操作的时候创建索引注意事项。
select xxx from A,B
on A.id = B.id
where A.name = ‘xxx’;
注意点:
连接表的数量尽量不要超过3张,因为每增加一张表,相当于增加一次嵌套循环,数量级增长快。
对where条件创建索引。因为where语句才是对数据条件进行过滤。
最后。对于连接的字段创建索引。同时该字段在多张表中的类型必须一致。
使用列的类型小的创建索引。
类型大小指的是该类型表示的数据范围大小。 以整数类型为例,有tinyint,mediumint,int,bigint。它们占用的存储空间依次递增。此时我们应该从小的类型开始去创建索引。
原因:
数据类型越小,在查询时进行的比较操作越快。
数据类型越小,索引占用的存储空间就越少,在一个数据页中就可以存储更多的记录,从而减少磁盘IO带来的性能损耗。
使用字符串前缀创建索引。
背景:表中某个列的字符串长度很长。
这种情况下带来的问题:
B+树索引中的记录,也就是叶子节点上会保存该数据的完整信息,这个保存的过程耗费的时间长。同时字符串越长,占据的存储空间越大。
字符串越长,做字符串比较的时候会占用更多的时间。
为了解决这种情况 ,最好通过截取字符串的方式,将截取部分作为索引,也就是建立前缀索引。 不仅能节约空间,还能减少字符串的比较时间。
同时Alibaba开发手册中建议:
在varchar字段上建立索引的时候,必须指定索引的长度,没必要对全字段建立索引。
例如:
create table shop(address varchar(120) not null);
alter table shop add index(address(12));
一般长度为20的索引,区分度就高达90%以上了。
区分度计算公式:
count(distinct left(列名, 索引长度))/count(*)
区分度高的列适合作为索引。
使用最频繁的列放在联合索引的左侧。增加联合索引的使用率。
多个字段都要创建索引的情况下,联合索引优于多个单个索引的创建。
当然,索引虽然能够提升查询的效率,但也不是说数量越多越好,对索引有限制:单表索引数量最好不超过6个。 原因如下:
每个索引都需要占用磁盘空间,索引数量越多,占据的磁盘空间越大。
索引会造成Insert、Delete、Update等语句的性能。(涉及到维护B+树的消耗)
优化器在选择如何优化查询的时候,会对每一个可能用到的索引进行评估,因此索引数量越多,会增加Mysql优化器生成执行计划的时间,降低查询性能。
七. Mysql性能分析
当出现执行SQL的时候,存在高延迟的情况,就可以采用分析工具来定位有问题的SQL了,一般分为三个步骤:慢查询、Explain、show Profiling。
7.1 查看系统性能参数
语法结构如下:
SHOW [GLOBAL|SESSION] STATUS LIKE ‘参数’;
常用的几个性能参数如下:
Connections:连接Mysql服务器的次数。
UpTime:Mysql服务器的上线时间。
Slow_queries:慢查询的次数。
Innodb_rows_read:Select查询返回的行数。
Innodb_rows_inserted:执行Insert操作插入的行数。
Innodb_rows_updated:执行Update操作更新的行数。
Innodb_rows_deleted:执行Delete操作删除的行数。
Com_select:查询操作的次数。
Com_insert:插入操作的次数。(批量插入的insert操作,只会算一次)
Com_update:更新操作的次数。
Com_delete:删除操作的次数。
7.2 慢查询
Mysql有个慢查询日志,一般用来记录哪些响应时间超过阈值(默认10s)的语句。不过默认是关闭的,若非调优需要,一般不建议启动该参数。因为开启慢查询日志多少会带来一定的性能影响。
临时开启慢查询:
set global slow_query_log=‘ON’;
查看:
show VARIABLES like ‘slow_query_log%’
img
同时为了方便,我们可以将慢查询默认的阈值10s改成0.1s:
set global long_query_time = 0.1;
测试:
SELECT * from student_info where name = ‘bchEBT’
此时用命令查看下,慢查询语句的次数有几条:
show status like ‘slow_queries’;
7.2.1 慢查询日志分析工具
在开启慢查询功能后,Mysql就会将相关的慢查询日志写入对应目录的文件下:
img
先看下mysqldumpslow的用法:
mysqldumpslow --help
结果如下:
-a: 不将数字抽象成N,字符串抽象成S。
-s: 是表示按照何种方式排序。
c: 访问次数
l: 锁定时间
r: 返回记录
t: 查询时间
al:平均锁定时间
ar:平均返回记录数
at:平均查询时间 (默认方式)
ac:平均查询次数
-t: 即为返回前面多少条的数据。
-g: 后边搭配一个正则匹配模式,大小写不敏感。
小插曲:mysqldumpslow命令没有。当你出现以下错误:
bash: mysqldumpslow: command not found
这时候是因为mysqldumpslow不在/usr/bin下面,而系统默认会查找/usr/bin下的命令。因此需要找到mysqldumpslow,并将其软连接到/user/bin下。
通过find命令查找mysqldumpslow到底在哪:
find ./ -name mysqldumpslow
复制对应的路径,然后建立软连接:ln -s [原地址] [目标地址]
ln -s /var/lib/docker/overlay2/e99c397fbbed993eece52ff597970fd763ccfd5320ddeb46b4a801c2cc648f3e/diff/usr/bin/mysqldumpslow /usr/bin/
此时在执行命令即可,输入命令:
mysqldumpslow -s t -t 5 /mydata/mysql/data/f634e0d26724-slow.log
img
7.3 分析查询语句Explain
假如我们开启了慢查询,然后发现了哪几个语句特别慢的,咱们就可以用Explain进行分析了。
Explain为我们提供了查看某个语句的具体执行计划的功能,例如:
表的读取顺序。
数据库读取操作的类型。
哪些索引可以被使用。
哪些索引被实际使用。
表之间的引用。
每张表有多少行数据被优化器查询到。
重点:Explain并不会真正执行后面的语句。
字段描述
id在一个大的查询语句中每个SELECT关键字都对应一个唯一的id
select_typeSelect关键字对应的查询类型
table表名
type针对单表的访问方法
possible_keys可能用到的索引
key实际上使用的索引
key_len实际上使用到的索引长度
ref当使用索引列等值查询时,与索引列进行等值匹配的对象信息
rows预估的需要读取的记录条数
filtered某个表经过搜索条件过滤后剩余记录条数的百分比
Extra额外信息
7.3.1 id 和 table 字段
案例1:
EXPLAIN SELECT * FROM s1 INNER JOIN s2;
EXPLAIN中,第一行的表叫做驱动表,也就是s1。后面的表叫做被驱动表。
img
这里的table字段也非常好理解,就是实际对应的是哪一张表。因为上述查询语句涉及到两张表,因此对于的EXPLAIN结果,也会出现两条结果。
案例2:
EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2) OR key3 = ‘a’;
结果如下:
img
因为上述语句包含了子查询,而且子查询肯定是优先执行的。此时id并不再是案例1中的id一致的情况了。
案例3:
EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key2 FROM s2 WHERE common_field = ‘a’);
但是这种子查询的情况,利用Explain查出来的结果,其id号竟然是一样的。这是因为查询优化器可能对涉及到的子查询进行重写,转变为多表查询的操作。
img
得出以下结论
id如果相同,可以认为是一组,从上往下顺序执行。
所有组中,id值越大,优先级越高,越先执行。
每一个id号代表一个独立的查询,一个sql的查询次数越少越好。
7.3.2 select_type 字段
select_type字段表述这个查询的一个类型,有这么几种:
名称描述
SIMPLE不使用UNION的简单查询
img
PRIMARY/UNION/UNION RESULTMysql中使用临时表来完成UNION查询的工作,针对该临时表的查询,对应的select_type是UNION_RESULT。img
SUBQUERY和DEPENDENT SUBQUERYimg
DEPENDENT UNIONimg
DERIVEDimg
MATERIALIZED当查询优化器在执行包含子查询的语句的时候,选择将子查询物化之后,再与外层查询进行连接查询。物化表:比如只包含key1字段的表,相当于一个集合常量。img
7.3.4 type 字段(重要)
type代表执行查询时的一个访问方法,访问方法如下:system、const、eq_ref、ref、fulltext、ref_or_null、index_merge、unique_subquery、index_subquery、range、index、ALL。按顺序从前往后,性能越来越差。
system:当表中 只有一条记录 并且该表使用的存储引擎的统计数据是精确的,例如MyISAM。那么此时对该表的访问是system。
CREATE TABLE t(i int) Engine=MyISAM;
INSERT INTO t VALUES(1);
EXPLAIN SELECT * FROM t;
img
其他的类型:
结合表s1的结构来看:
img
类型描述和案例
const当我们根据主键或者唯一二级索引列与常数进行等值匹配的时候,单表访问就是constimg
eq_ref在连接查询时,若被驱动表是通过主键或者唯一二级索引列等值匹配的方式进行访问的,那么对该被驱动表的访问是eq_refimg
ref当通过普通的二级索引列和常量进行匹配时,那么对该表的访问是refimg
ref_or_null通过普通二级索引进行等值匹配时,该列的值可以为null的时候,此时为ref_or_nullimg
index_merge单表访问的时候,某些场景可能涉及到索引合并的方式来查询,比如where语句中有两个条件,每个列都有自己单独的索引。img
unique_subquery针对一些包含In子查询的语句,若查询优化器决定将In子查询转化为Exists子查询,并且子查询可以使用主键进行等值匹配时,那么此时子查询执行计划的type是unique_subqueryimg
range使用索引获取某些范围区间的记录。img
index当我们可以使用索引覆盖,但是需要扫描全部的索引记录的时候,就是index方式img
ALL全表扫描img
几个注意点哈:
eq_ref针对的是被驱动表。
ref_or_null等于在ref的基础上允许有null值罢了。
ref访问,不包括主键索引。const包括主键。
index_merge目前一共三种索引合并:Intersection、Union、Sort-Union。上述案例通俗点来说。就是where 索引1=xxx or 索引2=xxx的这种情况。
SQL性能优化的角度来看:至少到达range级别,要求是ref级别,最好是consts级别。
7.3.5 possible_keys、key 字段
EXPLAIN SELECT * FROM s1 WHERE key1 > ‘z’ AND key3 = ‘a’;
img
意思是,该查询当中,优化器检查的是否发现可能用到的索引有idx_key1和idx_key3,但是实际上用到的索引是idx_key3。
其中key_len的大小是303,这里的大小指的是字节大小。同时值越大越好,主要针对于联合索引。
7.3.6 key_len 字段 (重要)
例如:根据主键查询
EXPLAIN SELECT * FROM s1 WHERE id = 10005;
那么此时结果:因为id是int类型,占4个字节。
img
根据key2查询:key2在id的基础上,具有唯一性索引,因此是非空,而非空占1个字节,因此对应的索引长度是5个字节。
EXPLAIN SELECT * FROM s1 WHERE key2 = 10126;
img
key_len的计算公式如下:
varchar(10)变长字段且允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段)
varchar(10)变长字段且不允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+2(变长字段)
char(10)固定字段且允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)
char(10)固定字段且不允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)
7.3.7 ref 字段
ref字段是当使用索引列进行等值查询的时候,与索引列进行等职匹配的对象信息。 比如对象是一个常数或者是某个列。
img
7.3.8 rows 和 filtered 字段(重要)
rows字段代表预估的需要读取的记录条数,值越小越好,查询所消耗的时间也就越小。
filtered字段代表某个表经过搜索条件过滤后,剩余记录条数所占的百分比。
EXPLAIN SELECT * FROM s1 WHERE key1 > ‘z’ AND common_field = ‘a’;
这里就是说查询出来的结果,占总数据条数的10%。
img
7.3.9 Extra 字段(重要)
Extra这个字段非常重要,我们可以通过额外的信息来更准确的理解Mysql如何执行给定的查询语句的。
下面给出几个比较重要和常见的额外信息:
额外信息描述和案例
No tables used查询语句没有from子句的时候提示。img
Impossible WHERE当查询语句where子句永远为false的时候img
Using where当使用全局扫描来执行查询,但是where子句中有针对性该表的搜索条件的时候img
No matching min/max row当查询列表处有Min或者Max聚合函数,但是并不符合where子句中的搜索条件的时候出现img
Using index当查询列表以及搜索条件中只包含属于某个索引的列的情况出现(比如不需要回表查询)img
Using index condition搜索条件中虽然出现了索引列,但是却不能使用索引,比如使用模糊查询导致索引失效img
Using join buffer (Block Nested Loop)连接查询过程中,当被驱动表不能有效地利用索引来加快访问速度的时候,Mysql就会分配一块名为join buffer的内存块来加快查询速度。 也就是基于块的嵌套循环算法。 例如下面的common_field列不包含索引img
Not exists当使用左连接时,若where子句包含要求被驱动表的某个列等于null值的搜索条件,但是那个列又不允许为null, 此时出现提示。img
Using intersect(…) 、 Using union(…) 和 Using sort_union(…)准备使用索引合并的方式执行查询 img
Zero limit当limit子句的参数为0,表示此时读不出任何记录,此时提示。img
Using filesort很多情况排序操作无法使用到索引,只能在内存或者磁盘中进行排序,Mysql将这种在内存上或者磁盘上进行排序的方式叫做文件排序。(效率低)img
Using temporary当执行语句包含Distinct、Group By、Union等子句查询的时候,若不能有效利用索引来完成查询,此时Mysql会借助临时表完成功能, 此时会提示Using temporaryimg
八. 索引失效
8.1 数据准备
建表和创建相关的存储函数:
CREATE TABLE class (id INT(11) NOT NULL AUTO_INCREMENT,className VARCHAR(30) DEFAULT NULL,address VARCHAR(40) DEFAULT NULL,monitor INT NULL ,
PRIMARY KEY (id)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE student (id INT(11) NOT NULL AUTO_INCREMENT,stuno INT NOT NULL ,name VARCHAR(20) DEFAULT NULL,age INT(3) DEFAULT NULL,classId INT(11) DEFAULT NULL,
PRIMARY KEY (id)
#CONSTRAINT fk_class_id FOREIGN KEY (classId) REFERENCES t_class (id)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
set global log_bin_trust_function_creators=1;
#随机产生字符串
DELIMITER //
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT ‘abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ’;
DECLARE return_str VARCHAR(255) DEFAULT ‘’;
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1)); SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
#用于随机产生多少到多少的编号
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11) BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
#创建往stu表中插入数据的存储过程
DELIMITER //
CREATE PROCEDURE insert_stu( START INT , max_num INT ) BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务
REPEAT #循环
SET i=i+1; #赋值
INSERT INTO student (stuno, name ,age ,classId ) VALUES
((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000)); UNTIL i = max_num
END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
#执行存储过程,往class表添加随机数据
DELIMITER //
CREATE PROCEDURE insert_class( max_num INT ) BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor ) VALUES
(rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
DELIMITER //
CREATE PROCEDURE proc_drop_index(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT ‘’;
DECLARE _cur CURSOR FOR SELECT index_name FROM
information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND seq_in_index=1 AND index_name <>‘PRIMARY’ ;
#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束
DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ; #若没有数据返回,程序继续,并将变量done设为2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>‘’ DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index=‘’;
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;
执行函数,创建数据:
#执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
#执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000,200000);
8.2 最左匹配原则
案例如下:首先创建个联合索引,注意顺序:age,classId,name
CREATE INDEX idx_age_classid_name ON student(age,classId,name);
EXPLAIN SELECT SQL_NO_CACHE * FROM student where age = 30 and classid = 1 and name = ‘abcd’;
EXPLAIN SELECT SQL_NO_CACHE * FROM student where classid = 1 and name = ‘abcd’;
EXPLAIN SELECT SQL_NO_CACHE * FROM student where age = 30 and name = ‘abcd’;
img
可以发现:
首先我们联合索引是以age为开头的,根据最左匹配原则,若查询条件不带有age列相关查询,此时索引会失效。 对应上图的第二个查询,没有用到任何索引。并且对于的type为ALL,说明进行了全表扫描。
我们写的SQL中关于where子句中条件的顺序问题,其实没什么关系,因为优化器会帮助我们优化语句。
联合索引为age,classId,name,若不带classId或者name,依旧是可以根据索引查询的。但是此时只会根据最左侧的字段来索引,跳过的字段以及其后续的索引都无法被使用。
8.3 计算、函数、类型转换导致索引失效
函数导致索引失效
计算导致索引失效
类型转换导致索引失效
注意,name是字符串列。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=‘123’;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;
8.4 范围条件右侧的列索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.classId = 20 AND student.name = ‘abc’ ;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.classId > 20 AND student.name = ‘abc’ ;
img
8.5 不等于判断造成索引失效
就是 != 以及<>
8.6 is not null 造成索引失效
8.7以%为开头的模糊查询造成索引失效
8.8 or 的前后存在非索引列造成索引失效
只要在or的前后存在一个非索引列的时候,索引就会失效。
同时需要大家注意:不同的字符集之间的比较,会进行转换操作,此时也会造成索引失效。
九. join语句原理
例如一个很简单的join语句:
select * from a left join b on (a.c1 = b.c1) and a.c2 = b.c2;
9.1 简单嵌套循环连接
img
假设表A有100条数据,表B有50条数据。那么该算法的实现过程就是:
循环遍历表A的每一条数据。
每一次循环,拿着当前表A的遍历到的一行数据,去被驱动表B中进行扫描匹配。
此时外表(表A)扫描次数为1次。内表(表B)扫描次数为100次。
读取记录的次数:100+100*50。
join比较的次数为100*50。
对于内表的扫描次数,可以发现完全决定于外表的数据量。因此我们也常常听别人说过,join语句的使用时,要 小表 join 大表。
由于这种算法的效率非常的低下,因此有了其他两种优化算法。
9.2 索引嵌套循环连接
img
本算法主要的思路就是减少内层表数据的匹配次数。 因此要求被驱动表上必须要有索引:
通过外层表匹配条件直接和内层表索引进行匹配。
避免和内层表的每条记录进行比较。
说白了,就是算法1的基础上增加个索引,避免全表扫描。当然需要大家注意:
被驱动表增加索引,效率是非常高的,但是索引如果不是主键索引,就得做一次回表查询。因此最好是使用主键索引进行匹配。
9.3 块嵌套循环连接
根据前面两种算法:
若join的列存在索引,就用索引嵌套算法。
若join的列不存在索引,就用简单嵌套算法。效率低下。
从另一个角度来看:
每次访问被驱动表,其中的表记录都会加载到内存中。再从驱动表中取一条记录进行匹配,匹配结束后清除内存。
上述的操作循环执行,大大增加了IO的次数,因此为了减少被驱动表的IO次数,就出现了块嵌套循环连接。
块嵌套循环连接:
相比之前的一条一条记录的IO,成了一块一块数据的获取 。
引入join buffer缓冲区,将驱动表join相关的部分数据列缓存到缓冲区中,然后全表扫描被驱动表。
被驱动表的每一条记录一次性和join buffer缓冲区中的所有记录进行匹配。
即将多次比较合并成一次。
img
小结下就是:
整体的效率比较:索引嵌套> 块嵌套>简单嵌套。
永远都用小表作为驱动表,减少外层循环的次数。
增大join buffer size的大小,一次缓存的数据越多,那么内表扫描的次数越少。
十. 覆盖索引和索引下推
10.1 覆盖索引
覆盖索引的概念:一个索引包含了满足查询结果的数据就叫做覆盖索引。
create index idx_age_name on student(age,name);
EXPLAIN SELECT * from student where age <> 20;
EXPLAIN SELECT age,name from student where age <> 20;
img
在第一章节中,我们知道,当使用不等于判断的时候,索引会失效,但是为什么第二个SQL语句,在使用了<>的情况下,依旧用到了索引呢?这里就用到了覆盖索引的概念,做个解释:
第一个SQL语句,是select *操作,即需要获取到所有列的数据。
第二个SQL语句,是SELECT age,name操作,只需要获取指定的列。
InnoDB引擎中,只有主键的B+树,其叶子节点存储了列的完整信息,而其他的非聚簇索引,是不包含的,因此第一个SQL语句需要进行回表操作。
而第二个SQL语句中,已经根据age和name建立了联合索引,而联合索引的本质也是非聚簇索引,是包含对应列的相关值的。并且联合索引包含的信息,正好覆盖到了查询的返回集。此时就不需要进行回表查询
优化器认为此时利用索引查询的效率比不使用索引而去回表查询的效率要高,因此使用了索引。
覆盖索引的优点:
避免Innodb表进行索引的二次查询(回表)。
可以把随机IO变成顺序IO加快查询效率。
覆盖索引的缺点:
需要进行维护索引字段的维护,联合索引覆盖面越广,维护成本越大。
10.2 索引下推
索引下推:Index Condition Pushdown(ICP),是Mysql5.6中的新特性。一种在存储引擎层使用索引过滤数据的一种优化方式。
用一种直观的对比就是:
没有ICP的情况:存储引擎会遍历索引来定位基表中的数据行,并将他们返回给Mysql服务器,由Mysql服务器来评估where子句是否保留行,即进行过滤操作。
有ICP的情况:若部分where子句可以仅仅使用索引中的列来评估,那么这部分会交给存储引擎来进行筛选(过滤)。
ICP的作用:
减少存储引擎访问基表的次数。
减少Mysql服务器访问存储引擎的次数。
其实,我们使用Explain进行分析的时候,Extra字段中,倘若出现了Using index condition,说明就使用了索引下推。
Using index condition:搜索条件中虽然出现了索引列,但是却不能使用索引,比如使用模糊查询导致索引失效。
EXPLAIN SELECT * from s1 where key1 > ‘z’ and key1 like ‘%a’;
img
再给个案例:
1.首先,将student表中的索引全部删除,然后建立个联合索引:
CREATE INDEX idx_age_classid_name ON student(age,classId,name);
EXPLAIN SELECT SQL_NO_CACHE * FROM student where age = 30 and classid = 1 and name = ‘abcd’;
EXPLAIN SELECT SQL_NO_CACHE * FROM student where age = 30 and classid <> 1 and name = ‘abcd’;
img
咱们用通俗点的话来说就是。
首先通过age索引进行查找,找到100条数据。
若没有ICP的情况下,由于此时使用了<>运算,索引失效,那么一般会直接进行回表查询,要查100次。
但是有ICP的情况下,会在已有的100条数据的基础上,做一次过滤,此时数据可能过滤到10条了,此时再去回表查询。只用查10次。
10.2.1 开启和关闭ICP的性能对比
SELECT * from people where zipcode = ‘00001’ and lastname like ‘%张%’;
SELECT /*+ no_icp (people) */ * from people where zipcode = ‘00001’ and lastname like ‘%张%’;
当然,数据量越大,这个差别体现的也就越明显,也可以通过这种方式来关闭ICP功能:
set optimizer_switch = ‘index_condition_pushdown=off’;
set optimizer_switch = ‘index_condition_pushdown=on’;
10.2.2 ICP使用的注意事项
当SQL使用覆盖索引的时候,不支持ICP,因为此时使用ICP的作用不大,并不会减少IO。
对于InnoDB表,ICP仅仅适用于二级索引。
10.3 补充查询优化策略
10.3.1 Exists 和 In 的区分
select * from A where exists (select col from B where B.col = A.col);
select * from A where col in (select col from B);
一般来说,选择标准都是小表驱动大表。
当A小于B的时候,用Exists。因为Exists的实现相当于外表循环。
for(i int A){
for(j int B){
}}
相反,B小于A的时候,用In,因为其实现相当于内表循环:
for(i int B){
for(j int A){
}}
10.3.2 count(*) 和count(字段)效率
Mysql中统计表的数据其实一般有三种写法:
select count(*);
select count(1);
select count(具体的某个字段);
count(*)和count(1)本质上没有区别。
倘若在InnoDB表中进行扫描,若采用count(具体字段)的方式来统计行数,尽量采用二级索引,因为主键为聚簇索引,包含的数据信息比较多。 对于前两者方式,系统会自动采用占用空间更小的二级索引来进行统计。
10.3.3 select * 注意事项
首先,在表查询的时候,应该明确查询的字段,不要使用*作为查询的字段列表。 原因如下:
Mysql在解析的时候,会通过查询数据字典,将 * 按序转化成所有的列名,会大大增加耗费的时间和资源。
无法使用覆盖索引。
10.3.4 limit 1对优化的影响
若某些SQL语句是会全表扫描的,并且能够确定结果集只有一条数据,那么此时加上limit 1的时候,当找到了目标结果,就会停止继续扫描,从而加快查询速度。
十一. 数据库设计规范
10.1 数据库主键的设计
首先来说下自增主键ID有哪些问题:
可靠性不高:存在自增ID回溯的问题。
安全性不高:对外暴露的接口可以非常容易猜测对应的信息,进行爬虫来获取数据。
性能差:自增ID的性能较差,需要在数据库服务器端生成。
交互多:当前插入的数据,若需要知道其自增ID是多少,那么需要多一次IO的交互,才能够得知。
局部唯一性:最重要的一点,自增ID是局部唯一,只在当前数据库实例中唯一,而不是全局唯一,在分布式系统来说,每台服务器之间无法保证自增ID的唯一性。
10.1.1 自增ID回溯问题
首先,自增ID回溯问题,在Mysql8.0才恢复,因此我们使用Mysql5.7版本来复现。
CREATE TABLE teacher (id int(11) NOT NULL AUTO_INCREMENT,name varchar(255) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT into teacher values(1,‘a’),(2,‘a’),(3,‘a’)
我们使用命令查看下当前的AUTO_INCREMENT值是多少:AUTO_INCREMENT=4
show create table teacher;
CREATE TABLE teacher (id int(11) NOT NULL AUTO_INCREMENT,name varchar(255) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8
此时呢,我们将Id为3的这条数据删除:再次查看AUTO_INCREMENT的值发现还是4
show create table teacher;
此时重启Mysql,再次查看值发现:AUTO_INCREMENT的值变回了3,这就是自增ID回溯。
10.1.2 推荐主键设计
以淘宝的主键设计为例,其可能为:
订单ID = 时间 + 去重字段 + 用户ID后6位尾号
对于非核心业务,我们可以使用主键自增ID。对于核心业务,主键设计的目标至少是全局唯一并且单调递增 。
最简单的主键设计就是UUID。其特点:全局唯一,占用36字节,数据无序,插入性能差。
Mysql的UUID组成结构为:
UUID = 时间+UUID版本(16字节)- 时钟序列(4字节) - MAC地址(12字节)
改造UUID:
将时间高低位互换,例如使用时间戳,就是单调递增的。
Mysql8.0就支持这样的UUID存储,同时除去了UUID字符串中无意义的"-"字符串,并且将字符串用二进制类型保存,这样存储空间降低为了16字节
MySQL8.0提供的uuid_to_bin函数实现上述功能
SET @uuid = UUID();
SELECT @uuid,uuid_to_bin(@uuid),uuid_to_bin(@uuid,TRUE);
结果如下:保证全局唯一+单调递增。
img
10.2 范式
范式(Normal Form 简称 NF)的概念:在关系型数据库中,关于数据表设计的基本原则、规则就称之为范式。
按照范式的级别,从低到高分别是:
第一范式(1NF)。
第二范式(2NF)。
第三范式(3NF)。
巴斯-科德范式(BCNF)了解即可。
第四范式(4NF)了解即可。
第五范式(5NF)了解即可。
10.2.1 键和相关属性概念
超键:能够唯一标识元组的属性集。
候选键:如果超键不包括多余的属性,那么这个超键就是候选键。
主键(主码):用户可以从候选键中选做一个作为主键。
外键:若数据表A中的某个属性集并不是A的主键,而是另外一个数据表B中的主键,那么该属性集就是数据表A的外键。
主属性:包含在任一候选键中的属性称之为主属性。
非主属性:与主属性相对的概念。
例如存在两张表:
球员表(player) :球员编号 | 姓名 | 身份证号 | 年龄 | 球队编号
球队表(team) :球队编号 | 主教练 | 球队所在地
那么这里对应的上述属性就是:
超键 :对于球员表来说,超键就是包括球员编号或者身份证号的任意组合,比如(球员编号) (球员编号,姓名)(身份证号,年龄)等。
候选键 :就是最小的超键,对于球员表来说,候选键就是(球员编号)或者(身份证号)。
主键 :我们自己选定,也就是从候选键中选择一个,比如(球员编号)。
外键 :球员表中的球队编号。
主属性/非主属性 :在球员表中,主属性是(球员编号)(身份证号),其他的属性(姓名)(年龄)(球队编号)都是非主属性。
10.2.2 各个范式的概念
第一范式:确保数据表中每个字段的值必须具有原子性,即数据表中每个字段的值为不可拆分的最小数据单元。
第二范式:在满足第一范式的基础上,还要满足数据表里的每一条数据记录都是可唯一标识的。同时所有非主键字段都必须完全依赖主键。
第三范式:在第二范式的基础上,确保数据表中的每一个非主键字段都和主键字段直接相关。即要求数据表中的所有非主键字段不能依赖于其他非主键字段。
巴斯范式:在第三范式的基础上,对第三范式的设计规范要求更强,使得数据库冗余度更小。即只存在一个候选键,或者它的每个候选键都是单属性。 此时关系成为了巴斯范式。(因为其相当于扩充的第三范式,因此还并不能称之为第四范式)它在 3NF 的基础上消除了主属性对候选键的部分依赖或者传递依赖关系 。
第四范式:在巴斯范式的基础上,消除非平凡且非函数依赖的多值依赖。
多值依赖概念:多值依赖:属性之间的一对多关系,记为K→→A。
函数依赖:本质上是单值依赖。不能表达属性值之间的一对多关系。
平凡的多值依赖:全集U=K+A,一个K可以对应多个A,此时整个表就是一组一对多关系。
非平凡的多值依赖:全集U=K+A+B,一个K可以对应多个A或者B。A和B之间相互独立。K→→A,K→→B,整个表有多组一对多关系。
第五范式:满足第四范式的基础上,消除不是由候选键所蕴含的连接依赖。 若关系模式R中的每一个连接依赖都由R的候选键所隐含,此时此关系模式叫第五范式。
10.2.3 反规范化
反规范化:为了提高某些查询性能,需要破坏范式规则的行为。
举个简单的案例:员工的信息存储在employees中,部门信息存储在departments中。通过 employees 表中的 department_id字段与 departments 表建立关联关系。如果要查询一个员工所在部门的名称,SQL假语句就是:
select employee_id,department_name from employees e
join departments d on e.department_id = d.department_id;
此时出现需求和解决方案:
需求:但是如果该操作的执行频率非常高,那么每次进行连接查询就会浪费很多时间。
解决:可以在 employees 表中增加一个冗余字段 department_name,就不用每次都进行连接表操作了。
这样的操作违反了范式,因此也就是反规范化。总的来说可以分为这两种:
通过在给定的表中添加额外的字段,以减少大量表连接所需的搜索时间(好处)。
通过在给定的表中插入计算列,以方便查询(好处)。
反规范化的问题:
存储空间变大了。
一个表中字段做了修改,另一个表中冗余的字段也需要做同步修改,否则造成数据不一致。
若采用存储过程来支持数据的更新、删除等额外操作,如果更新频繁,会非常消耗系统资源。
在数据量小的情况下,反范式不能体现性能的优势,可能还会让数据库的设计更加复杂。
反规范化的适用场景:
当冗余信息有价值或者能够大幅度提高查询效率的时候,采取反规范化的优化。
十二. 事务
事务的基本概念:一组逻辑操作单元,使数据从一种状态变换到另一种状态。
事务的ACID特性:
原子性:原子性是指事务是一个不可分割的工作单位,要么全部提交,要么全部失败回滚。
一致性:一致性是指事务执行前后,数据从一个合法性状态变换到另外一个合法性状态
隔离性:一个事务的执行不能被其他事务干扰,即一个事务内部的操作和使用的数据对其他并发的事务是隔离的。
持久性:持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的。(持久性是通过事务日志来保证的。日志包括了重做日志和回滚日志 )
总结下就是:ACID作为事务的四大特性,原子性是基础,隔离性是手段,一致性是约束条件,目的是保持持久性。
事务的状态:
活动的:事务对应的数据库操作正在执行过程中。
部分提交的:当事务中的最后一个操作执行完成,但由于操作都在内存中执行,所造成的影响并没有刷新到磁盘时,我们就说该事务处在部分提交的状态。
失败的:当事务处在活动的或者部分提交的状态时,可能遇到了某些错误而无法继续执行,或者人为的停止当前事务的执行,我们就说该事务处在失败的状态。
中止的:如果事务执行了一部分而变为失败的状态,那么就需要把已经修改的事务中的操作还原到事务执行前的状态。即回滚,回滚完毕后,处于中止状态。
提交的:当一个处在部分提交状态的事务将修改过的数据同步到磁盘上后,此时处于提交状态。
img
12.1 事务的使用
显式事务的使用:
begin;
start transaction [read only | read write | with consistent snapshot];
commit;
ROLLBACK;
ROLLBACK TO [SAVEPOINT];
READ ONLY:标识当前事务是一个只读事务,也就是属于该事务的数据库操作只能读取数据,而不能修改数据。
READ WRITE :标识当前事务是一个读写事务,也就是属于该事务的数据库操作既可以读取数据,也可以修改数据。
WITH CONSISTENT SNAPSHOT :启动一致性读。
隐式事务的使用,关键字:autocommit
show VARIABLES like ‘autocommit’;
默认开启,此时一条完整独立的SQL语句,其本身就是一个独立的事务。
注意:虽然事务默认是开启的,哪怕会自动提交事务,但是一旦我们声明了start transaction 后,后面的DML操作就不会自动提交数据,而是需要通过commit命令来生效。
隐式提交数据的情况:
数据定义语言(DDL):指的是当我们使用create/alert/drop等语句去修改数据库对象的时候,就会隐式的提交。
隐式使用或修改mysql数据库的表:当使用Alert user、Create user、Drop user、Grant、Rename user、revoke、set password等操作时候,也会提交前面语句所属事务。
事务控制或者关于锁定的语句,三种情况:
1.当我们在一个事务还没提交或者回滚时就又使用 START TRANSACTION 或者 BEGIN 语句开启了另一个事务时,会隐式的提交上一个事务
2.当前的 autocommit 系统变量的值为 OFF ,我们手动把它调为 ON 时,也会隐式的提交前边语句所属的事务。
3.使用Lock Tables、Unlock Tables等关于锁定的语句也会提交前边语句所属的事务。
12.2 数据并发问题
12.2.1 脏写
对于两个事务 Session A、Session B,如果事务Session A 修改了另一个未提交事务Session B 修改过的数据,那就意味着发生了脏写。
img
以上面示意图为例,当SessionB发生回滚之后,SessionA做的更新也就将不复存在,这种现象就叫脏写。
12.2.2 脏读
Session A 读取了已经被 Session B 更新但还没有被提交的字段。之后若 Session B 回滚 ,Session A 读取的内容就是临时且无效的。
img
12.2.3 不可重复读
Session A 读取了一个字段,然后 Session B 更新了该字段。 之后Session A 再次读取同一个字段,值就不同了。那就意味着发生了不可重复读。
img
12.2.4 幻读
Session A 从一个表中读取了一个字段, 然后 Session B 在该表中插入了一些新的行并满足SessionA当中的查询条件。之后如果 Session A 再次读取同一个表, 就会多出几行。那就意味着发生了幻读。
img
这几种并发问题的严重程度,从大到小进行排序:
脏写 > 脏读 > 不可重复读 > 幻读
12.3 事务隔离级别
Mysql中事务隔离级别一共有4种:
读未提交(READ UNCOMMITTED):在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。不能避免脏读、不可重复读、幻读。
读已提交(READ COMMITTED):一个事务只能看见已经提交事务所做的结果,可以避免脏读。
可重复读(REPEATABLE READ):事务A在读到一条数据之后,此时事务B对该数据进行了修改并提交,那么事务A再读该数据,读到的还是原来的内容。可以避免脏读、不可重复读。 Mysql的默认隔离级别。
可串行化(SERIALIZABLE):确保事务可以从一个表中读取相同的行。在这个事务持续期间,禁止 其他事务对该表执行插入、更新和删除操作。所有的并发问题都可以避免,但性能十分低下。能避免脏读、不可重复读和幻读。
用图表做结论就是:
img
Mysql中默认的隔离级别是可重复读,我们也可以手动修改下事务的隔离级别。
show variables like ‘tx_isolation’;
show variables like ‘transaction_isolation’;
如何设置事务的隔离级别
第一种方式:
set [global | session] transaction isolation level [隔离级别]
这里的隔离级别指的是:
1.READ UNCOMMITTED
2.READ COMMITTED
3.REPEATABLE READ
4.SERIALIZABLE
第二种方式:
set [global | session] transaction_isolation = [隔离级别]
这里的隔离级别指的是:
1.READ-UNCOMMITTED
2.READ-COMMITTED
3.REPEATABLE-READ
4.SERIALIZABLE
备注:关于设置变量的时候,使用global和session的区别
global:全局范围内影响。但是对于已经存在的会话是无效的。
session:当前会话范围内影响。对当前会话的后续所有事务有效。
十三. 事务日志
事务的隔离性由锁机制来实现,而事务的原子性、一致性和持久性则交给事务的redo日志和undo日志来保证。
首先,来看下两种日志的作用分别是什么:
Redo Log:重做日志,提供再写入操作,恢复提交事务修改的页操作,用来保证事务的持久性。
Undo Log:回滚日志,回滚行记录到某个特定的版本,用来保证事务的原子性和一致性。
其次,两种日志都是存储引擎层InnoDB生成的日志。看看两种日志的区别:
Redo Log:记录的是物理级别上的页修改操作。比如页号、偏移量、写入了什么数据等。
Undo Log:记录的是逻辑操作日志,比如对某一行数据进行了插入操作,那么Undo Log会记录一条与之相反的删除操作。用于事务的回滚。
13.1 Redo 日志
背景:InnoDB存储引擎以页为单位来管理存储空间, 真正访问页之间,需要把磁盘上的页缓存到内存中的Buffer Pool之后才可以访问。所有的变更都必须先更新缓冲池中的数据,然后缓冲池的脏页(内存中修改了,但是磁盘还没更新)会以一定的频率刷入到磁盘中(checkpoint机制)
为什么需要Redo日志呢?先来看下背景:
问题1:SQL修改量与刷新磁盘工作量严重不成比例。
有些时候我们可能仅仅修改了某页中的一条数据。但是InnoDB是以页为单位来进行磁盘IO的。因此在提交事务进行磁盘更新的时候,不得不将该数据所在的整个页进行刷新到磁盘中。这样的操作没必要。
问题2:随机IO刷新较慢。
一个事务可能包含多个语句,倘若事务修改的这些页面并不相邻,意味着进行事务提交的时候,将缓冲池中的页刷新到磁盘这个动作的时候,需要进行很多的随机IO,也会带来性能问题。
所以我们其实没有必要在每次事务提交时就把该事务在内存中修改过的全部页面刷新到磁盘,只需要把修改了哪些东西记录一下就好,这也就是需要Redo日志的原因。
而InnoDB引擎的事务采用了WAL技术(Write Ahead Logging),即先写日志,在写磁盘, 只有日志写入成功,才算事务提交成功。这里的日志也就是RedoLog。
RedoLog的优点:
降低了刷盘频率。
占用的存储空间比较小。
RedoLog是顺序写入磁盘,并且在事务执行过程中,RedoLog不断记录。
13.1.1 Redo 日志的组成
Redo日志主要分为两个部分:
重做日志缓冲(redo log buffer),保存在内存中,容易丢失。
在Mysql服务器启动的时候,就会申请一块连续的内存空间,其划分为若干个连续的redo log block,一个块占用512kb,如图:
img
重做日志文件(redo log file),保存到磁盘中,是持久的。 例如数据库data文件下的这两个文件就是重做日志文件:
img
这里设置到这么几个参数:
innodb_log_files_in_group:知名redo log file的个数,命名格式如:ib_logfile0,ib_logfile1,默认是2个。
img
innodb_log_file_size:单个redo log文件的大小,默认是48MB。
img
上述两个文件,他们属于同一个日志文件组,一个文件组中的日志写入也是有顺序的,按照序号的大小,从小到大开始写:
img
13.1.2 Redo 的流程和刷盘策略
以更新事务为例:
img
从上面的流程我们得知:
redo log并不是直接写入到磁盘中,而是先写入缓冲池里。
再以一定的频率做刷盘,将数据写入到redo log file中。
InnoDB存储引擎给出了三种刷盘策略,通过设置innodb_flush_log_at_trx_commit参数,共有三种值:
值为0:表示每次事务提交时不进行刷盘操作。(系统默认masterthread每隔1s进行一次重做日志的同步)
img
值为1:表示每次事务提交时都将进行同步刷盘操作。也是InnoDB的默认刷盘行为。
img
值为2:表示每次事务提交时都只把 redo log buffer 内容写入 page cache,不进行同步。由os自己决定什么时候同步到磁盘文件。
img
总结下就是:
第一种,全权交给主线程来每隔一秒来刷新,可能出现数据丢失(Mysql服务器挂了)。
第二种,事务提交一次,刷盘一次,不会丢失数据。
第三种,交给操作系统来同步,也会出现数据丢失(操作系统挂了)。
13.1.3 写入redo log buffer 的过程
首先,Mysql中对底层页的一次原子访问的过程叫做Mini-Transaction。简称mtr。
一个事务可能由若干语句组成,一个语句又可能由若干mtr组成,而每个mtr过程又可以包含多条redo日志。示意图如下:
img
回到我们说写入redo log buffer 的过程。写入的顺序是有序的,我们得知有个redo log block的概念,多个连续的redo log block也就是组成了重做日志缓冲池。写入的示意图如下:
img
注意:
不同的事务之间可能是并发执行的,因此在每个block body中写入redo log的时候,可能是交替写入的。
13.2 Undo 日志
上面提到,Redo 日志是事务持久性的一个保证,中心思想:先写日志再写磁盘。 而Undo 日志是事务原子性的保证,同样的,在事务中更新数据也有个前置动作,先写入undo log。
注意:undo log的生成也会产生redo log。因为undo log也需要持久性的保护。
undo 日志用在什么地方呢?
某个事务执行到一半时发生了系统错误或者断电。
在事务执行过程中,通过输入Rollback语句来结束当前事务的执行。
那么此时,我们需要将数据改回原本的样子,这个过程就叫做回滚,也符合原子性的要求。从一个持久性状态到另一个持久性状态。即不包括这种中间态。
undo 日志作用:
回滚数据。
MVCC。
13.2.1 Undo 日志存储结构
InnoDB对undoLog的管理采用段的方式,即回滚段(rollback segment)。每个回滚段记录了1024个undo log segment。在每个undo log segment中再进行undo页的申请。
undo页:
当我们开启事务,需要写undoLog的时候,就得去undo log segment中申请一块空闲位置,即申请undo页。
在这个申请到的undo页中再进行回滚日志的写入。
undo页具有重用性,事务提交的时候,并不会立刻删除对应的undo页。而是将其放入到一个链表中。
若undo页的使用空间小于四分之三,则当前的undo页可以被重用,即不会被回收。而是将其分配给下一个事务来使用。
回滚段和事务之间的关系:
每个事务只会使用一个回滚段,一个回滚段在同一时刻可能会服务于多个事务。
在事务进行的过程中,当数据被修改时,原始的数据会被复制到回滚段。
回滚段中的数据分类:
未提交的回滚数据(uncommitted undo information) :该数据关联的事务并未提交,因此用于实现读一致性,并且该数据是不能够被其他事务的数据所覆盖。
已经提交但未过期的回滚数据(committed undo information):该数据关联的事务已提交,但是受到undo retention参数的保持时间的影响。
事务已经提交并过期的数据(expired undo information):事务已提交,并且超过了保持时间,属于过期数据,这部分的数据,在回滚段满了之后,会优先被覆盖。
undoLog类型分为两种:
insert undo log:insert操作中产生的日志,只对事务本身可见,对其他事务不可见(隔离性)。因此该类型日志可以在事务提交之后直接删除,不需要进行purge操作。
update undo log:针对delete和update操作产生的日志,可能需要提供MVCC机制。不能在事务提交的时候就删除,提交的时候放入到undoLog链表,等待purge线程来删除。
13.2.2 Undo 流程
以下是undo+redo事务的简化流程:
需求如下:一共2条数据,A=1,B=2。事务中作出更改:A=3,B=4。那么流程简化如下:
img
有了事务日志之后:
img
十四. 锁的分类
在上一章事务日志当中,我们知道
事务的持久性由redo log来实现。
一致性和原子性由undo log来实现。
那么剩下的隔离性则由本章的锁机制来实现。
锁是计算机协调多个进程或者线程并发访问某一资源的一种机制。
背景:在Mysql中,并发事务的访问大概可以分为三种情况:
读-读:不会有什么影响。
写-写:会发生脏写问题。
读-写:会发生脏读、不可重复读、幻读等问题。
那么如何解决脏读、不可重复读、幻读等问题呢?
方案一: 读操作利用多版本并发控制MVCC实现。写操作进行加锁。
方案二:读写操作都进行加锁。
脏读的产生是因为当前事务读取了另一个未提交事务写的一部分记录。 那么如果另一个事务在写记录的时候就给这条记录加锁,那么当前事务就读取不到这条记录了,也就避免了脏读。
不可重复读的产生和脏读是比较相似的,只不过从读操作变成了修改操作。当前事务先读取一条记录,另外一个事务对该记录做出了改动并提交,那么当前事务再次读取时就会获得不同的值。 同样给对应的记录添加锁时,当前的事务就无法修改这条记录,也就避免的不可重复读。
幻读的产生是因为当前事务读取了一个范围记录,然后另外的事务插入了一条满足当前事务的一个查询条件,此时当前事务再次查询的时候,就会发现多出来的记录。
但问题来了,采用加锁的方式来解决幻读的话,会遇到一些麻烦:因为当前事务在第一次读取记录的时候幻影记录并不存在,那么读取的时候就加上锁就不太合适,而且并不知道到底给谁加锁,因为你无法为一条不存在的记录加锁。
也因此,Mysql中MVCC在READ COMMITTED 和 REPEATABLE READ隔离级别下会使用,因为其无法解决幻读。
接下来看下Mysql对于锁的分类。
14.1 根据对数据的操作类型划分
此时可以分为两种锁:
读锁/共享锁。
写锁/排他锁。
14.1.1 读锁/共享锁
读锁(read lock):英文用S标识。针对同一份数据,多个事务的读操作可以同时进行而不会互相影响,相互不阻塞的。
对读取的记录加S锁:
select … lock in share mode;
select … for share;
倘若当前事务对某一条语句加了S锁。那么当别的事务继续获取当前记录的时候,允许它们获取这个S锁,但是不能获取这些记录的X锁,倘若想获取X锁,则发生阻塞。直到当前事务提交之后将记录上的S锁释放掉。
14.1.2 写锁/排他锁
写锁(write lock):英文用 X 表示。当前写操作没有完成前,它会阻断其他写锁和读锁。 这样就能确保在给定的时间里,只有一个事务能执行写入,并防止其他用户读取正在写入的同一资源。
对读取的记录加X锁:
select … for update;
若当前事务加了X锁,那么其他的事务对于该数据既不能加S锁也不能加X锁。会阻塞。
注意:读写锁可以加在表上和数据行上。
在Mysql5.7及更老的版本中,对于加X锁的时候,倘若获取不到,那么进入阻塞一直等待,直到innodb_lock_wait_timeout超时。在Mysql8.0中,可以添加NOWAIT、SKIP LOCKED语法,跳过锁等待,若查询的行已经加了锁:
NOWAIT:立即报错返回。
SKIP LOCKED:立即返回,但是返回的结果中不包含被锁定的行。
14.2 根据数据操作的粒度划分
倘若锁根据粒度来进行划分,那么此时可以分为三种锁:
表锁。
行锁。
页锁。
14.2.1 表锁(Table Lock)
表锁会锁定整张表,是Mysql中最基本的锁策略,并不依赖于存储引擎,是开销最小的策略(粒度最大),可以很好地避免死锁问题。
① 表级别的S/X锁
对表A添加表级别的S/X锁,语法如下:
LOCK TABLES A READ;# 添加读锁
LOCK TABLES A WRITE;# 添加写锁
② 意向锁
InnoDB支持多粒度锁,允许行级锁和表级锁共存,其中意向锁就是一种表锁。
意向锁:
其存在是为了协调行锁和表锁的关系,支持多粒度的锁并存。
意向锁是一种不与行级锁冲突的表级锁。
意向锁能解决什么问题?假设此时有两个事务,T1和T2,若T2尝试在表级别上尝试加排它锁:
若没有意向锁:那么T2就需要检查该表中的各个数据页或者行是否存在锁。
若有意向锁:那么此时就会受到T1控制的表级别意向锁阻塞。 T2在锁定该表之前不必检查各个页或者行锁,只需检查表上的意向锁即可。大大提高了效率。
即给更大一级别的空间做个标识,标识空间内的元素是否加上了锁。 那么换句话说就是**意向锁会告诉其他事务,当前表中的某些记录已经被其他事务锁定了。
意向锁分为两种:
意向共享锁(intention shared lock, IS):事务有意向对表中的某些行加共享锁(S锁)。
– 事务要获取某些行的 S 锁,必须先获得表的 IS锁。
SELECT column FROM table … LOCK IN SHARE MODE;
意向排他锁(intention exclusive lock, IX):事务有意向对表中的某些行加排他锁(X锁)。
– 事务要获取某些行的 X 锁,必须先获得表的 IX锁。
SELECT column FROM table … FOR UPDATE;
如果事务想要获得数据表中某些记录的共享锁,就需要在数据表上添加意向共享锁。
如果事务想要获得数据表中某些记录的排它锁,就需要在数据表上添加意向排它锁。
案例如下:
打开两个会话
在第一个会话中,开启一个事务,为这个表中的某一条数据添加X锁:
img
在另一个会话中,同样开启一个事务,尝试对该表添加个读锁:
img
此时会话2是进入阻塞状态的,因为会话1中,哪怕是给表中的某一条记录添加了X锁,但是Mysql会自动的给对应的表添加个意向锁IX锁。因此此时其他的事务还想要添加表锁的时候,就会进入阻塞(无论是读锁还是写锁)。
此时尝试将会话1中的事务提交。
img
此时再看会话2:发现阻塞结束了
img
意向锁和普通的排他/共享锁(表级别的)之间的兼容关系如下:
img
③ 自增锁(AUTO-INC锁) 了解
我们平常使用过自增主键,例如:
CREATE TABLE teacher (id int NOT NULL AUTO_INCREMENT,name varchar(255) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
对于这种拥有自增ID的,在数据插入的时候我们可以不显式地指定对应的值,例如:
INSERT INTO teacher (name) VALUES (‘zhangsan’), (‘lisi’);
这样的数据插入方式一共有三种:
简单插入(Simple inserts): 可以预先确定要插入的行数。
批量插入(Bulk inserts):事先不知道要插入的行数。
混合模式插入(Mixed-mode inserts):这些是简单插入模式但是指定部分新行的自动递增值。
其实上面一个简单的插入就用到了自增锁:
AUTO-INC锁就是当向 含有AUTO_INCREMENT列的表插入数据时需要获取到的一种特殊表级锁。在执行插入语句时就会添加自增锁。
然后为每一条待插入记录的AUTO_INCREMENT修饰的列分配递增值,在该语句执行结束后,就会将自增锁释放掉。
一个事务在持有自增锁的过程中,其他事务的插入语句都会被阻塞。
当我们向一个含有AUTO_INCREMENT关键字的主键插入值的时候,每条语句都要为这个表锁进行竞争, 这样就导致并发能力低下,因此InnoDB可以通过innodb_autoinc_lock_moda参数来提供不同的锁定机制:
0:在此锁定模式下,所有类型的insert语句都会获得一个特殊的表级AUTO-INC锁,用于插入具有 AUTO_INCREMENT列的表。
1:在此锁定模式下,对于批量插入,会添加自增表级锁。但是对于简单插入(插入的行数已知),则通过在 mutex(轻量锁) 的控制下获得所需数量的自动递增值来避免添加自增表级锁, 它只在分配过程的持续时间内保持,而不是直到语句完成。
2:在此锁定模式下,自动递增值保证在所有并发执行的所有类型的insert语句中是唯一且单调递增的。
④ 元数据锁(MDL锁)
在对某个表执行SELECT、INSERT、DELETE、UPDATE语句时,InnoDB存储引擎是不会为这个表添加表级 别的 S锁 或者 X锁 的。 在对某个表执行一些诸如 ALTER TABLE 、 DROP TABLE 这类的 DDL 语句时,其他事务对这个表并发执行诸如SELECT、INSERT、DELETE、UPDATE的语句会发生阻塞。反之同理。这个过程其实是通过在 server层使用一种称之为元数据锁 (英文名: Metadata Locks,MDL )结构来实现的。
MDL锁的作用:保证读写的正确性。
当一个表做增删改查操作的时候,添加MDL读锁。
当对表结构做变更操作的时候,添加MDL写锁。
MDL锁是在访问表的时候自动添加的,不需要显式的调用。
14.2.2 行锁(Row Lock)
注意:MyISAM不支持行锁,因此接下来的内容都是针对于InnoDB的。
行级锁只在存储引擎层实现:
优点:锁粒度更小,发生锁冲突的概率低。可以实现的并发度高。
缺点:对于锁的开销比较大,加锁慢,容易出现死锁。
行锁可以分为四种:
记录锁。
间隙锁。
临键锁。
插入意向锁。
① 记录锁
当在一个事务中,对某一条记录进行了update操作,那么就会加上对于的记录锁。记录锁是有S锁和X锁之分的,称之为S型记录锁和X型记录锁 。
当一个事务获取了一条记录的S型记录锁后,其他事务也可以继续获取该记录的S型记录锁,但不可以继续获取X型记录锁;
当一个事务获取了一条记录的X型记录锁后,其他事务既不可以继续获取该记录的S型记录锁,也不可以继续获取X型记录锁。
② 间隙锁(Gap Locks)
我们在上文中提到,通过加锁的方式去解决幻读问题是行不通的,因为无法为一条不存在的幻影记录进行加锁。因此InnoDB提出来一种锁叫间隙锁。gap锁的提出仅仅是为了防止插入幻影记录。例如,给id为8的记录增加一个间隙锁,官方名称叫LOCK_GAP,简称gap锁:
img
此时意味着不允许别的事务在id值为8的记录前边的间隙插入新的记录。 即在(3,8)这个id区间内,不允许其他事务插入新数据。
注意,倘若以上述图为例,为id为25的数据添加一个X锁(不存在的数据),那么此时,这个间隙锁将会是(20,正无穷)。
同时,间隙锁容易造成死锁。因为间隙锁会将某个范围的数据进行锁定,若范围控制的不好,容易造成不同事务之间的抢夺锁行为,造成死锁
③ 临键锁(Next-key Locks)
有时候我们希望锁住当前记录 ,又想阻止其他事务在该记录前边的 间隙插入记录 。即一个左开右闭区间。 此时InnoDB就提出了Next-key Locks。简称next-key锁。在事务级别为可重复读的情况下使用的数据库锁默认就是临键锁。
相当于间隙锁的一个升级了,我觉得可以这么理解:
next-key锁 = 记录锁 + 间隙锁。
④ 插入意向锁
一个事务在插入一条记录的时候,需要判断一下插入位置是否被别的事务加了gap锁,若有的话,插入操作需要等待,直到拥有gap锁的事务提交。
InnoDB规定:事务在等待的时候需要在内存中生成一个锁结构,表明有事务想在某个间隙中插入新纪录。
这种类型的锁就叫Insert Intention Locks,就是插入意向锁,也是gap锁的一种。在insert操作一条记录之前产生。
特点:
插入意向锁是一种特殊的间隙锁,可以锁定开区间内的部分记录。
插入意向锁之间互不排斥,即使多个事务在同一个区间内插入多条记录,只要记录本身的主键不冲突,那么事物之间就不会出现阻塞等待。
14.2.3 页锁
页锁也就是在页的粒度上进行锁定,锁定的数据资源比行锁要多。页锁的开销介于表锁和行锁之间,会出现死锁。
14.3 根据对待锁的态度划分
此时,Mysql中的锁分为两种,这里的锁并不是真正的锁,而是一种设计思想。
乐观锁。
悲观锁。
14.3.1 悲观锁(数据库锁机制实现)
对数据被其他事务的修改持保守态度,会通过数据库自身的锁机制来实现,从而保证数据操作的排它性。比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁,当其他线程想要访问数据时,都需要阻塞挂起。
例如Java当中的Synchronized还有ReentrantLock都是悲观锁的设计。
在Mysql中,例如这样的语句就是个典型的悲观锁实现:
select … for update;
但是值得注意的是:select … for update;执行过程中会将所有扫描到的行都锁上,因此在Mysql中使用悲观锁必须确定使用了索引,而不是全表扫描,否则会将整个表锁住。
14.3.2 乐观锁(程序实现)
乐观锁则认为对统一数据的并发操作属于小概率事件,保持乐观态度,不用每次都对数据进行上锁,通过程序来实现。 例如:
版本号控制。
CAS机制(Java的AutomicInteger类等等)。
乐观锁的版本号机制如下:
表中设计一个版本字段version。
每次读取的时候,会获取version的值,然后对数据进行修改的时候。
会执行update … set version = version + 1 where version = version。
那么倘若已经有事务对这条数据进行修改,就会出现版本号不一致的情况,修改也就不会成功。
乐观锁的时间戳机制如下:
和版本号机制一样,在更新提交的时候,将当前数据的时间戳和之前获取到的时间戳进行比较。
若两者一致,则更新成功。
两种锁的适用场景:
乐观锁:适合读操作多的场景。
悲观锁:适合写操作多的场景。因为写的操作具有排他性。
img
14.4 根据加锁的方式划分
14.4.1 隐式锁
隐式锁存在于哪呢:
img
隐式锁的逻辑过程
InnoDB的每条记录中都一个隐含的trx_id字段,记录着最后改动该条记录的事务id,这个字段存在于聚簇索引的B+树中。
在操作一条记录前,首先根据记录中的trx_id检查该事务是否是活动的事务(未提交或回滚)。如果是活动的事务,首先将隐式锁转换为显式锁 (就是为该事务添加一个锁)。
检查是否有锁冲突,如果有冲突,创建锁,并设置为waiting状态。如果没有冲突不加锁,跳到第五步。
等待加锁成功,被唤醒,或者超时。
写数据,并将自己的trx_id写入trx_id字段。
14.4.2 显式锁
本文当中诸如以下这样显式加锁的方式都称之为显式锁:
select … for update
select … lock in share mode
14.5 死锁
Mysql中死锁指的是:多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环。
出现死锁后,Mysql有两种策略:
第一种:进入等待直到超时。超时时间通过innodb_lock_wait_timeout控制。默认50s。
img
第二种:发起死锁检测,主动回滚死锁链中持有最少行级排它锁的事务。 让其他事务得以继续执行。该策略通过参数innodb_deadlock_detect=on开启。
十五. 锁的内存结构
给一条记录加锁的本质也就是在内存中创建一个锁结构与之关联。 但是也并不是一个事务对多条记录加锁,那么就会生成多个表结构,只有符合条件的记录才会放到一个表结构中:
在同一个事务中进行加锁操作。
被加锁的记录在同一个页中。
加锁的类型是一样的。
等待状态一样。
InnoDB中的锁结构如下:
img
15.1 锁所在事务信息
这里存储的是一个指针,通过指针来找到内存中关于该事务的更多信息,例如事务的ID。
15.2 索引信息
对于行锁来说,需要记录一下加锁的记录是属于哪一个索引的,也是一个指针。
15.3 表锁/行锁信息
表锁:记录着是对哪一张表加的锁以及其他信息。
行锁:记录三个重要信息:
Space ID:记录所在表空间。
Page Number:记录所在页号。
n_bits:对于行锁来说,一条记录就对应着一个比特位,一个页面中包含很多记录,用不同的比特位来区分到底是哪一条记录加了锁。这个n_bits 属性代表使用了多少比特位。
15.4 type_mode
type_mode是一个32位的数字,分为三个部分
img
lock_mode:锁模式。占用低4位,可选值如下:
img
lock_type:锁类型,有两种:
img
rec_lock_type:行锁的具体类型,只有在lock_type的值为LOCK_REC的时候,即该锁表示为行级锁,才会被细分为更多的类型,如下:
img
15.5 其他信息和比特位
其他信息:存储了管理系统运行过程中生成的各种哈希表和链表。
比特位:如果是行锁结构的话,在该结构末尾还放置了一堆比特位,主要作为页中数据的一个映射。
十六. MVCC 多版本并发控制
MVCC:(Multiversion Concurrency Control)多版本并发控制。通过数据行的多个版本管理来实现数据库的并发控制。
先理解以下概念。
16.1 快照读和当前读
快照读(一致性读):读取的是快照数据。例如不加锁的简单的Select语句都属于快照读。快照读的实现就基于MVCC。
select … from student where …;
当前读:读取的是记录的最新版本,读取的时候还要保证其他并发事务不会修改当前的记录。会对读取的记录进行加锁,即加锁的select操作。
select … from student lock in share mode;
普通的Select语句在以下两种隔离级别下会使用到MVCC读取记录:
READ COMMITTED :一个事务在执行过程中每次执行SELECT操作时都会生成一个ReadView,ReadView的存在本身就保证了事务不可以读取到未提交的事务所做的更改 ,也就是避免了脏读现象。
REPEATABLE READ:一个事务在执行过程中只有第一次执行SELECT操作才会生成一个ReadView,之后的SELECT操作都复用这个ReadView,这样也就避免了不可重复读和幻读的问题。
16.2 MVCC实现原理之ReadView
MVCC的实现依赖于三个层面:
隐藏字段:比如事务ID,回滚指针。
Undo Log。
ReadView。
关于ReadView:事务在使用MVCC机制进行快照读操作的时候产生的读视图。
当事务启动的时候,就会生成当前数据库系统的一个快照。InnoDB为每个事务都构造了一个数组,用来记录当前活跃事务的ID(启动了但未提交)。
ReadView中主要包含4个重要内容:
creator_trx_id:创建这个ReadView的事务ID。(只有对表中的记录作出update类改动时,才会为事务分配事务ID,否则在一个只读事务中的事务ID值为0)也因此ReadView和事务之间的关系是一对一的。
trx_ids:生成ReadView的此时此刻,当前系统中活跃的事务ID列表。
up_limit_id:活跃事务中的最小事务ID。
low_limit_id:表示生成ReadView时系统中应该分配给下一个事务的ID值。
使用ReadView的规则,当访问某条记录的时候,遵循下属步骤就可以判断某条记录的某个版本是否可见。
若被访问版本的trx_id值和ReadView中的creator_trx_id值相同:意味着当前事务正在访问他自己修改过的记录,该版本可以被当前事务访问。
若被访问版本的trx_id值 小于 ReadView中的up_limit_id值:意味着被访问的版本已经事务提交,该版本可以被当前事务访问。
若被访问版本的trx_id值 大于或者等于 ReadView中的low_limit_id值:意味着该版本的事务在当前事务生成 ReadView之后才开启,不可访问。
若被访问版本的trx_id值 在 ReadView中的up_limit_id值和low_limit_id值之间:那么当前事务是否可访问当前版本决定于trx_id值是否存在于trx_ids列表中。
MVCC查找到一条记录的操作流程如下:
首先获取事务自己的版本号,即事务ID。
获取到ReadView。
查询得到的数据,然后于ReadView中事务版本号进行比较。
若不符合ReadView规则,那么需要从Undo Log中,即版本链获取历史快照。
最后返回符合规则的数据。
注意:隔离级别为读已提交的时候,一个事务中的每一次Select查询都会重新获取一次ReadView。 否则可能产生不可重复读或者幻读的情况。
现在我们有一张student表,下面有一条由事务ID为8插入的数据:
img
16.2.1 在读提交隔离级别下举例
读提交:Read Committed,在该隔离级别下,每次读取数据都会生成一个ReadView。
现在有两个事务ID分别为10和20的事务在执行:
img
那么此时student表中的这条记录,其版本链如下:
img
倘若此时有一个事务正在读取这条数据:
select * from student where id = 1;
此时的执行过程如下:
在执行select语句的时候,根据该隔离级别的特性,会生成一个ReadView。此时其trx_ids列表的内容就是[10,20],up_limit_id为10(最小值),low_limit_id为21(下一个最大值),creator_trx_id为0(只有update类操作才会分配)。
此时需要从版本链挑选可见的记录,从上图可得最新的记录是王五,该版本的trx_id是10,在trx_ids列表中,不符合可见性要求,根据回滚指针roll_pointer跳到下一个版本。
下一个版本的数据是李四,其同理不符合版本要求,继续跳到下一个版本。
到最后一条版本数据张三,trx_id值为10,小于等于ReadView中up_limit_id的值10,因此符合版本要求,最终返回给用户。
返回张三所在的数据行。
倘若此时我们将事务10进行commit提交:
img
再去事务20中更新一下表student中id为1的记录:
img
此时此刻的版本链为:
img
此时的执行过程如下:
在执行select语句的时候,根据该隔离级别的特性,会生成一个ReadView。此时其trx_ids列表的内容就是[20](事务10已经提交,不再属于活跃事务),up_limit_id为20(最小值),low_limit_id为21(下一个最大值),creator_trx_id为0(只有update类操作才会分配)。
此时需要从版本链挑选可见的记录,从上图可得最新的记录是宋八,该版本的trx_id是20,在trx_ids列表中,不符合可见性要求,根据回滚指针roll_pointer跳到下一个版本。
下一个版本的数据是钱七,其同理不符合版本要求,继续跳到下一个版本。
到最后一条版本数据王五,trx_id值为10,小于ReadView中up_limit_id的值20,因此符合版本要求,最终返回给用户。
返回王五所在的数据行。
16.2.2 在重复读隔离级别下举例
在该隔离级别下的事务而言:只会在第一次执行查询语句时生成一个ReadView。
现在有两个事务ID分别为10和20的事务在执行:
img
那么此时student表中的这条记录,其版本链如下:
img
倘若此时有一个事务正在读取这条数据:
select * from student where id = 1;
此时的流程和读提交隔离级别下的流程是一模一样的,但是倘若事务10提交之后,就会发生区别了(重要):
事务10进行commit提交,开启一个新事务对数据进行更新操作:
此时此刻的版本链为:
img
此时的执行过程如下:
在执行select语句的时候,根据该隔离级别的特性,由于第一次查询的时候已经生成了一个ReadView,因此此时此刻复用之前的ReadView。此时其trx_ids列表的内容就是[10,20],up_limit_id为20,low_limit_id为21,creator_trx_id为0。
此时需要从版本链挑选可见的记录,从上图可得最新的记录是宋八,该版本的trx_id是20,在trx_ids列表中,不符合可见性要求,根据回滚指针roll_pointer跳到下一个版本。
下一个版本的数据是钱七,其同理不符合版本要求,继续跳到下一个版本。
直到最后一条版本数据张三,trx_id值为8,小于ReadView中up_limit_id的值10,因此符合版本要求,最终返回给用户。
返回张三所在的数据行。
16.3 MVCC如何解决幻读(快照读前提)
注意:只有在快照读的情况下,MVCC是可以解决幻读的。前提是快照读,快照读,快照读!
这里的举例和上面的特别相似,依旧假设student表中只有一条数据,主键id为1。事务ID为10,那么其undoLog为:
img
此时有两个事务A,B并发执行,事务ID分别为20,30。流程如下:
事务A进行查询,并生成一个ReadView:trx_ids=[20,30],up_limit_id=20,low_limit_id=31,creator_trx_id=0。能够查询到张三的这条数据。
select * from student where id >= 1;
事务B往student表中插入两条数据并提交事务。
img
此时对应的undoLog为:
img
此时事务A进行第二次查询,根据可重复读的规则,事务A并不会再重新生成一个ReadView,此时student中的三条记录都是满足where子句的条件的,都是可以查出来的,然后会根据ReadView的机制,判断每条数据是否可以被事务A看到。
id为1的数据肯定是看得到的。id为2的数据,其trx_id为30,处于trx_ids之间,表示id为2的这条数据是与事务A在同一时刻启动的其他事务提交的,因此该数据不能被事务A看到。id为3的数据同理。
img
因此事务A依旧只会读取到id为1的一条记录,即不会产生幻读。
十七. 文件
文件的种类:
参数文件:一些初始化参数
日志文件:如错误日志文件、二进制日志文件、慢查询日志文件、查询日志文件等
socket 文件
pid 文件
MySQL 表结构文件:存放 MySQL 表结构定义文件
存储引擎文件:每个存储引擎都会有自己的文件
17.1 参数文件
参数分 动态参数 和 静态参数。动态参数可以在 MySQL 实例运行中进行更改,静态参数在整个实例生命周期内不得更改。
17.2 日志文件
错误日志(error log):对 MySQL 的启动、运行、关闭过程进行记录,记录所有错误信息及部分告警和正确信息。
二进制日志(binlog):记录了对 MySQL 执行更改的所有操作,不管更改操作是否使数据库发生了变化。
二进制日志有以下几种作用:恢复、复制、审计
二进制日志文件默认关闭,需要手动启动
对于支持事务的存储引擎,会在事务提交之前先将二进制日志存入缓存中,等事务提交之后再写入二进制文件
MySQL 5.1 开始引入了 binlog_format 参数,该参数可以设置 STATEMENT、ROW、MIXED
STATEMENT 格式和之前 MySQL 版本一样,记录逻辑 SQL 语句
MIXED,默认采用 STATEMENT ,有些情况采用 ROW
ROW 记录表的行更改情况,通常情况设置为 ROW
优点:可以为数据库恢复和复制带来更好的可靠性
缺点:1. 文件大小会增加 2. 语句执行时间会变长 3. 复制是采用传输二进制文件实现,所以网络开销也会增大
慢查询日志(slow query log):记录超过时间阈值(启动时设置)和没有使用索引的查询语句
阈值可以通过 long_query_time 设置
默认不开启,用户需要手动开启
MySQL 5.1 开始,可以将慢查询日志放入一张表中, mysql 架构下的 slow_log 表
查询日志(log):记录所有对 MySQL 数据库请求的信息,无论是否得到了正确的执行
MySQL 5.1 开始,可以将查询日志放入 mysql 架构下的 general_log 表中
17.3 InnoDB 存储引擎文件
17.3.1 表空间文件
InnoDB 采用将存储的数据按表空间进行存放的设计,默认配置下会有一个初始大小为 10MB 名为 ibdatal 的文件,该文件就是默认表空间文件。
还有一个参数是 innodb_file_per_table ,若设置了该参数,则每张表会生成一个独立表空间。这些单独的表空间文件仅存储该表的数据、索引和插入缓冲 BITMAP 等信息,其余信息还是存放在默认的表空间中。
17.3.2 重做日志文件(redo log)
redo log 可以用来保证数据的完整性。
重做日志(redo log)和二进制日志(bin log)的区别:
bin log 是数据库层的日志,包括其它存储引擎的日志;redo log 是 InnoDB 的日志,只记录本身的事务日志。
bin log 记录的是关于一个事务的具体操作内容,即该日志是逻辑日志;redo log 记录的是关于某页的更改的物理情况。
写入时间也不同,bin log 仅在事务提交前进行提交,只写磁盘一次;在事务提交过程中,却不断有重做日志条目(redo entry)被写入到重做日志文件中。
写入重做日志不是直接写,而是先写入一个重做日志缓冲中。而且是按照一个扇区的大小(512 字节)写入的,因为扇区是写入的最小单位,所以不需要 doublewrite。
]]>https://registry.npmmirror.com/binary.html?path=node/latest-v16.x/
tar -zxvf node-v16.20.0-linux-x64.tar.gz vim /etc/profile在末尾加上
export NODE_HOME=/home/local/nodejs/node-v16.20.0-linux-x64
export PATH=PATH
source /etc/profilenode -vnpm -vnpm config set registry https://registry.npmmirror.comhttps://maven.apache.org/download.cgi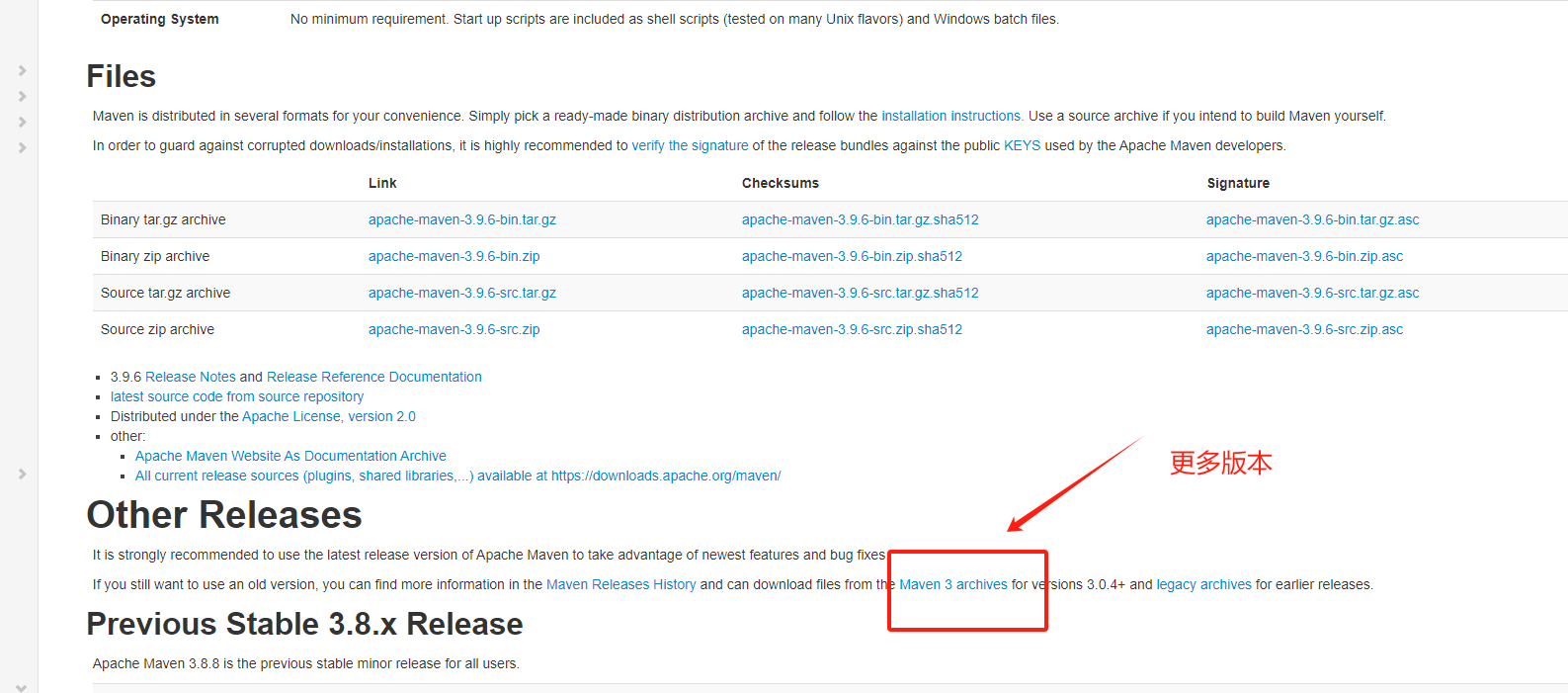
cd /homemkdir -p local/mavencd /home/local/mavenchmod 777 maventar zxvf apache-maven-3.5.4-bin.tar.gzvim /etc/profile#文件添加以下内容# maven environmentexport M2_HOME=/home/local/maven/apache-maven-3.5.4export CLASSPATH=$CLASSPATH:$M2_HOME/libexport PATH=$PATH:$M2_HOME/bin #输入命令使配置文件生效source /etc/profile测试是否安装成功
mvn -vmkdir repository
#修改文件夹权限
chmod 777 repository/
#进入maven的conf目录
cd /home/local/maven/apache-maven-3.5.4/confchmod 777 settings.xml<localRepository>/home/local/maven/repository</localRepository>... ...<mirror> <id>nexus-aliyun</id> <mirrorOf>central</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url></mirror>通过以下命令可以看到系统自带的JDK版本信息,看是否为OpenJDK version
java -version
如果显示Java version说明别人已经安装过Oracle JDK,不用在重复安装了。
查询本机中已经安装过的java rpm包,命令如下;
rpm -qa |grep java[root@localhost ~]$ rpm -qa |grep javajava-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64javapackages-tools-3.4.1-11.el7.noarchjava-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64nuxwdog-client-java-1.0.3-2.el7.x86_64java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64mysql-connector-java-5.1.25-3.el7.noarchpython-javapackages-3.4.1-11.el7.noarchtzdata-java-2015g-1.el7.noarchjavassist-3.16.1-10.el7.noarchjava-1.7.0-openjdk-devel-1.7.0.91-2.6.2.3.el7.x86_64javamail-1.4.6-8.el7.noarchjava-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64nuxwdog-client-java-1.0.3-2.el7.x86_64java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64java-1.7.0-openjdk-devel-1.7.0.91-2.6.2.3.el7.x86_64.noarch文件属于通用文件,不影响,不用删除,删了也没事~
javapackages-tools-3.4.1-11.el7.noarchmysql-connector-java-5.1.25-3.el7.noarchpython-javapackages-3.4.1-11.el7.noarchtzdata-java-2015g-1.el7.noarchjavassist-3.16.1-10.el7.noarchjavamail-1.4.6-8.el7.noarch删除命令,(注:删除命令需要用root权限)
rpm -e --nodeps xxxrpm -e --nodeps java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64rpm -e --nodeps nuxwdog-client-java-1.0.3-2.el7.x86_64rpm -e --nodeps java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64rpm -e --nodeps java-1.7.0-openjdk-devel-1.7.0.91-2.6.2.3.el7.x86_64检查是否已经删除成功
在命令窗口键入java -version,如下说明已经删除成功了:
[root@localhost ~]$ java -version-bash: java: command not foundmkdir -p /home/local/javacd /home/local/javatar -zxvf jdk-8u401-linux-x64.tar.gz用vim或vi 打开/etc/profile 文件
vim /etc/profile将下面内容粘贴到末尾;
export JAVA_HOME=/home/local/java/jdk1.8.0_401export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarEsc
Shift + q 进入键盘编辑
wq 保存并退出
source /etc/profile 输入:java -version,javac,java
]]>项目管理、性能调优
执行java字节码文件的虚拟机,负责装载字节码到其内部,解释/编译为对应平台上的机器码指令执行
特点:
现在的JVM不仅可以执行java字节码文件,还可以执行其他语言编译后的字节码文件,是一个跨语言平台。
程序在执行之前先要把 java 代码转换成字节码(class 文件),类加载器(ClassLoader)把文件加载到内存中的运行时数据区(Runtime Data Area),而字节码文件是 jvm 的一套指令集规范,并不能直接交个底层操作系统去执行,因此需要特定的命令解析器执行引擎(Execution Engine)将字节码翻译成底层系统指令再交由CPU去执行,而这个过程中需要调用其他语言的接口本地库接口(Native Interface) 来实现整个程序的功能
Java类加载器(Class Loader)是Java虚拟机(JVM)的一部分,负责将类的字节码加载到内存中,并将其转换为可执行的Java对象。
类加载器是Java虚拟机用于加载类文件的一种机制。在Java中,每个类都由类加载器加载,并在运行时被创建为一个Class对象。类加载器负责从文件系统、网络或其他来源中加载类的字节码,并将其转换为可执行的Java对象。类加载器还负责解析类的依赖关系,即加载所需的其他类。
Java虚拟机定义了三个主要的类加载器:
启动类加载器(Bootstrap Class Loader):也称为根类加载器,它负责加载Java虚拟机的核心类库,如java.lang.Object等。启动类加载器是虚拟机实现的一部分,它通常是由本地代码实现的,不是Java类。
扩展类加载器(Extension Class Loader):它是用来加载Java扩展类库的类加载器。扩展类库包括javax和java.util等包,它们位于jre/lib/ext目录下。
应用程序类加载器(Application Class Loader):也称为系统类加载器,它负责加载应用程序的类。它会搜索应用程序的类路径(包括用户定义的类路径和系统类路径),并加载类文件。
除了这三个主要的类加载器,Java还支持自定义类加载器,开发人员可以根据需要实现自己的类加载器。
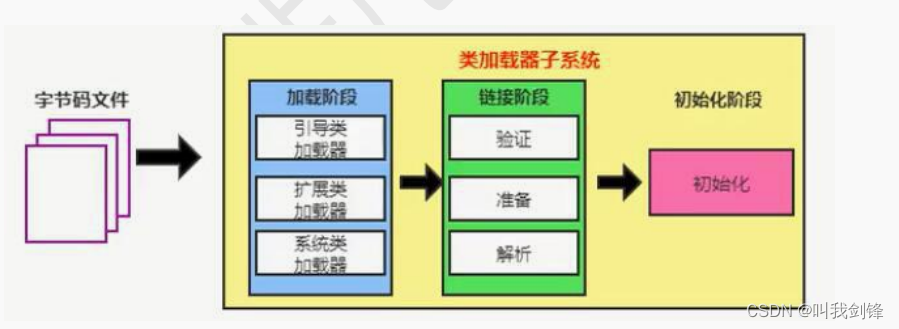
加载的类信息存放于一块称为方法区的内存空间。
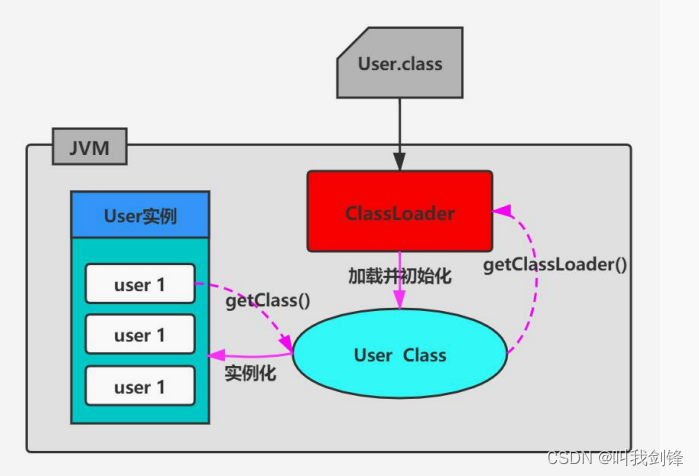
class file 存在于硬盘上,可以理解为设计师画在纸上的模板,而最终这个模板在执行的时候是要加载 JVM 当中来,根据这个模板实例化出 n 个实例.
class file 加载到 JVM 中,被称为 DNA 元数据模板. 此过程就要有一个运输工具(类加载器 Class Loader),扮演一个快递员的角色
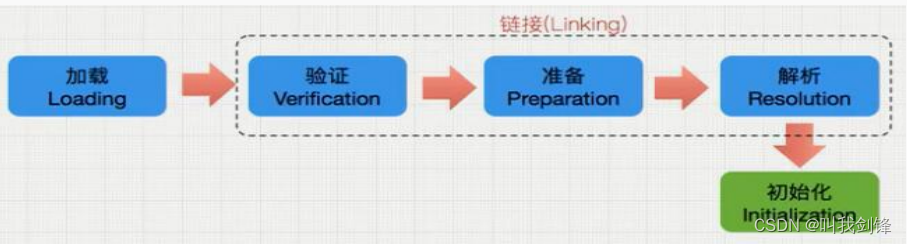
类加载器的工作可以简化为三个步骤:
加载(Loading):定位(根据类的全限定名),读取类文件的字节码。
链接(Linking):将类的字节码转换为可以在虚拟机中运行的格式。链接过程包括三个阶段:
验证(Verification):验证字节码的正确性和安全性,确保它符合Java虚拟机的规范。
准备(Preparation):为类的静态变量分配内存,并设置默认的初始值。
解析(Resolution):将类的符号引用(比如方法和字段的引用)解析为直接引用(内存地址)。
初始化(Initialization):执行类的初始化代码,包括静态变量的赋值和静态块的执行。
验证:
检验被加载的类是否有正确的内部结构,并和其他类协调一致;
验证文件格式是否一致: class 文件在文件开头有特定的文件标识(字节码文件都以 CA FE BA BE 标识开头);主,次版本号是否在当前 java 虚拟机接收范围内.
元数据验证:对字节码描述的信息进行语义分析,以保证其描述的信息符合java语言规范的要求,例如这个类是否有父类;是否继承不允许被继承的类(final 修饰的类)…
准备:
解析:将类的二进制数据中的符号引用替换成直接引用(符号引用是 Class 文件的逻辑符号,直接引用指向的方法区中某一个地址)
为类的静态变量赋予正确的初始值,JVM 负责对类进行初始化,主要对类变量进行初始化。初始化阶段就是执行底层类构造器方法
类什么时候初始化:
JVM规定:每个类或者接口被首次主动使用时才对其进行初始化。引用该类的静态常量,注意是常量,不会导致初始化,但是也有意外,这里的常量是指已经指定字面量的常量,对于那些需要一些计算才能得出结果的常量就会导致类加载,比如:
public final static int NUMBER = 5 ; //不会导致类初始化,被动使用public final static int RANDOM = new Random().nextInt() ; //会导致类加载构造某个类的数组时不会导致该类的初始化,比如:
Student[] students = new Student[10];类的初始化顺序对static修饰的变量或语句块进行赋值,如果同时包含多个静态变量和静态代码块,则按照自上而下的顺序依次执行。
如果初始化一个类的时候,其父类尚未初始化,则优先初始化其父类。顺序是:父类 static –> 子类 static
站在JVM的角度看,类加载器可以分为两种:
划分得更细致一些.自 JDK1.2 以来 java 一直保持者三层类加载器
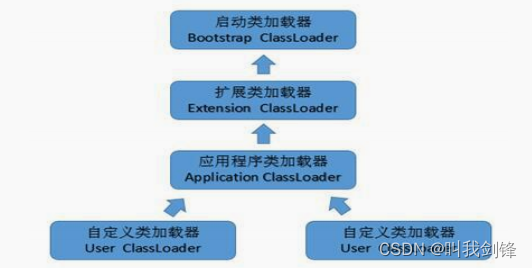
Java 虚拟机对 class 文件采用的是按需加载的方式,也就是说当需要该类时才会将它的 class 文件加载到内存中生成 class 对象.而且加载某个类的 class 文件时,Java 虚拟机采用的是双亲委派模式,即把请求交由父类处理,它是一种任务委派模式
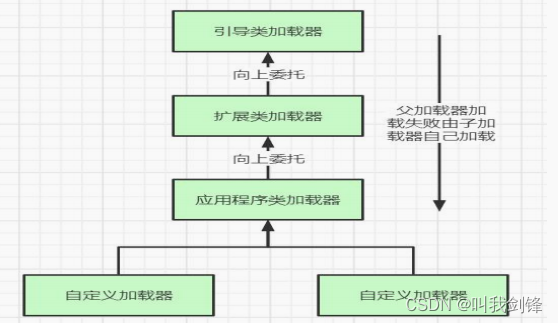
工作原理:
类加载器加载类的过程,首先调用loadClass()方法,在该方法中调用findClass()方法。最后在findClass()方法中调用defineClass()方法。
loadClass(String name),findClass(String name) 这两个方法并没有被 final 修饰,也就表示其他子类可以重写
继承ClassLoader类,重写 loadClass 方法(是实现双亲委派逻辑的地方,修改他会破坏双亲委派机制, 不推荐)
重写 findClass 方法 (推荐)
为什么要自定义类加载器
隔离加载类
在某个应用中需要使用中间件,这个中间件有自己的依赖的jar包,在同一个工程里面,如果引用多个框架的话,有可能会出现某些类的路径一样、类名也相同,这样就会出现类的冲突了,这个时候就需要做一个类的仲裁,像现在主流的容器类的框架一样,它们都会自定义类的加载器,实现不同的中间件隔离,避免类的冲突
修改类的加载方式
在整个类的加载过程中,bootstrap引导类加载器是一定被使用的,用来加载系统需要的核心API,除了bootstrap引导类加载器之外,其他的类加载器也不是必须的,我们可以根据实际情况中修改类的加载方式,具体要用的时候我们再引用
扩展加载源
加载的类除了可以在网络、本地物理磁盘、jar包去加载之外,我们还可以考虑通过数据库、电视机的机顶盒等等来扩展加载源
防止源码泄露
当有了字节码文件或者没有反编译的手段,java代码是很容易被编译和篡改,所以,为了防止编译和篡改,我们可以对字节码文件进行加密,当我们需要运行这个字节码文件时候,我们需要解密来还原成内存中的类,而这个解密的操作,就需要自定义类的加载器来实现
自定义加载类实现热部署
package config;import java.io.*;public class MyClassLoader extends ClassLoader { // 此类加载器加载的路径 private String root; public MyClassLoader(ClassLoader parent, String root) { super(parent); this.root = root; } public MyClassLoader(String root) { this.root = root; } @Override protected Class<?> findClass(String name) throws ClassNotFoundException { // IO流读取字节码文件为二进制流 try (BufferedInputStream bis = new BufferedInputStream((new FileInputStream(root + name + ".class"))); ByteArrayOutputStream bos = new ByteArrayOutputStream()) { int len; byte[] bytes = new byte[1024]; while ((len = bis.read(bytes)) != -1) { bos.write(bytes, 0, len); } bos.flush(); bytes = bos.toByteArray(); return defineClass(null,bytes,0,bytes.length); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return null; }}import config.MyClassLoader;public class TestService { public static void main(String[] args) throws Exception { while (true) { MyClassLoader classLoader = new MyClassLoader("d:/"); Class<?> person = classLoader.loadClass("Person"); System.out.println(person.getDeclaredConstructor(int.class,String.class). newInstance(21,"张三")); Thread.sleep(5000); } }}将Person.java转换为class文件存到d盘
package entity;import lombok.Data;@Datapublic class Person { private int age; private String name; public Person(int age, String name) { this.age = age; this.name = name; } @Override public String toString() { return "Person{" + "age=" + age + ", name='" + name + '\'' + '}'; }}修改后编译为class文件替换在d盘
package entity;import lombok.Data;@Datapublic class Person { private int age; private String name; public Person(int age, String name) { this.age = age; this.name = name; } @Override public String toString() { return "Person{" + "age=" + age + ", name='" + name + '\'' + '}' + "\n====测试热部署====="; }}
JVM 的运行时数据区,不同虚拟机实现可能略微有所不同,但都会遵从 Java 虚拟机规范
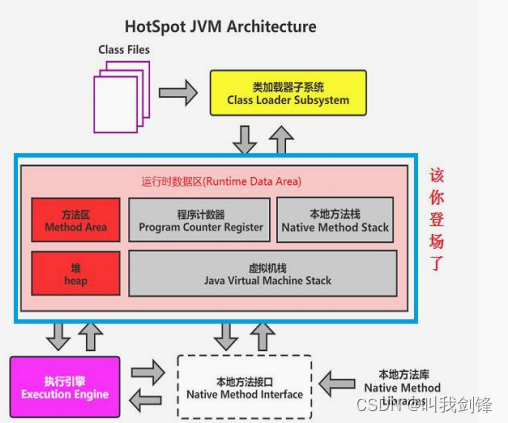
Java 8 虚拟机规范规定,Java 虚拟机所管理的内存将会包括以下几个运行时数据区域:
程序计数寄存器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。
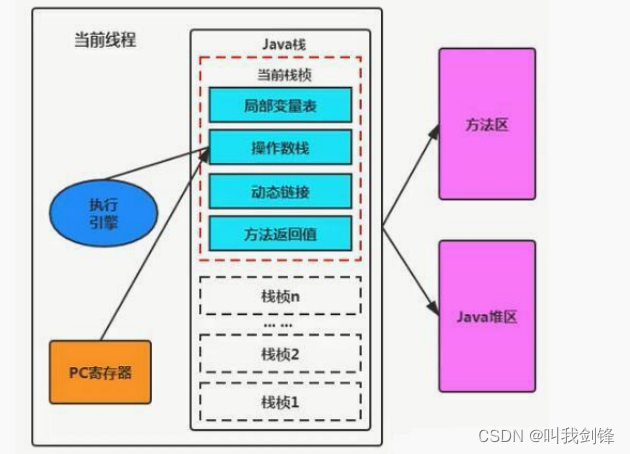

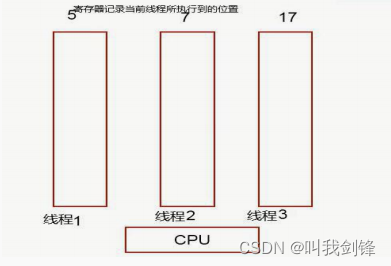
描述的是 Java 方法执行的内存模型,每个方法在执行的同时都会创建一个线帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息,每个方法从调用直至执行完成的过程,都对应着一个线帧在虚拟机栈中入栈到出栈的过程。
除了一些 Native 方法调用是通过本地方法栈实现的,其他所有的 Java 方法调用都是通过栈来实现的
栈是运行时的单位,即栈解决程序的运行问题,即程序如何执行,或者说如何处理数据. Java 虚拟机栈(Java Virtual Machine Stack),早期也叫 Java 栈.每个线程在创建时都会创建一个虚拟机栈,其内部保存一个个栈帧,对应着一次方法的调用.Java 虚拟机栈是线程私有的。作用:主管 Java 程序的运行,它保存方法的局部变量(8种基本数据类型,对象的引用地址),部分结果,并参与方法的调用和返回

栈的特点
栈是一种快速有效的分配存储方式,访问速度仅次于程序计数器.
JVM 直接对 java 栈的操作只有两个:调用方法 入栈 .执行结束后 出栈 .
对于栈来说不存在垃圾回收问题.

栈中会出现异常,当线程请求的栈深度大于虚拟机所允许的深度时 , 会出现StackOverflowError.
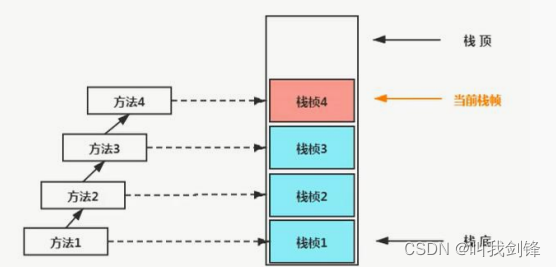
不同线程中所包含的栈帧(方法)是不允许存在相互引用的,即不可能在一个栈中引用另一个线程的栈帧(方法).
如果当前方法调用了其他方法,方法返回之际,当前栈帧会传回此方法的执行结果给前一个栈帧,接着虚拟机会丢弃当前栈帧,使得前一个栈帧重新成为当前栈帧.
Java 方法有两种返回的方式,一种是正常的函数返回,使用 return 指令,另一种是抛出异常.不管哪种方式,都会导致栈帧被弹出.
每个栈帧中存储着:
局部变量表(Local Variables)
局部变量表是一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量。对于基本数据类型的变量,则直接存储它的值,对于引用类型的变量,则存的是指向对象的引用。
操作数栈(Operand Stack)(或表达式栈)
栈最典型的一个应用就是用来对表达式求值。在一个线程执行方法的过程中,实际上就是不断执行语句的过程,而归根到底就是进行计算的过程。因此可以这么说,程序中的所有计算过程都是在借助于操作数栈来完成的。
动态链接(Dynamic Linking) (或指向运行时常量池的方法引用)
因为在方法执行的过程中有可能需要用到类中的常量,所以必须要有一个引用指向运行时常量。
方法返回地址(Retuen Address)(或方法正常退出或者异常退出的定义)
当一个方法执行完毕之后,要返回之前调用它的地方,因此在栈帧中必须保存一个方法返回地址。
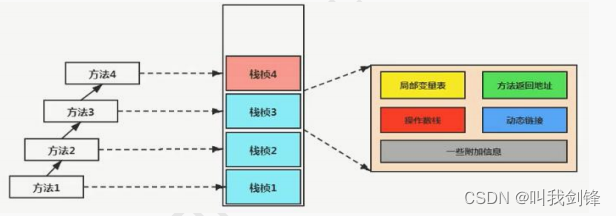
详细介绍:https://zhuanlan.zhihu.com/p/520519929
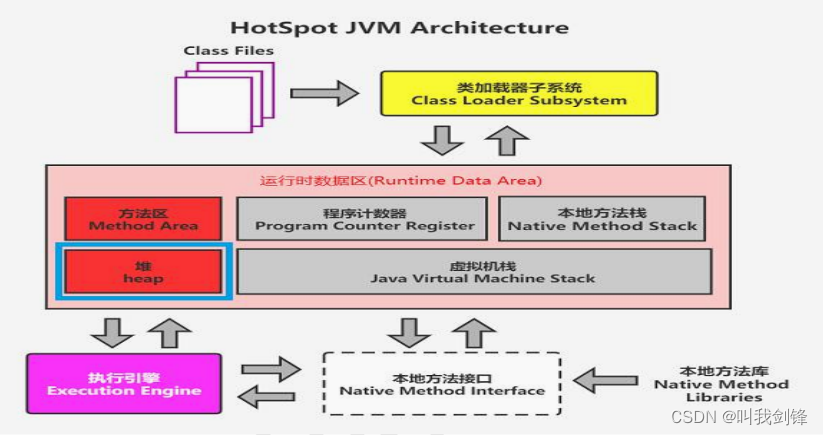
一个 JVM 实例只存在一个堆内存,堆也是 Java 内存管理的核心区域.
Java 堆区在 JVM 启动时的时候即被创建,其空间大小也就确定了,是 JVM 管理的最大一块内存空间.
堆内存的大小是可以调节.例如: -Xms:10m(堆起始大小) -Xmx:30m(堆最大内存大小)。一般情况可以将起始值和最大值设置为一致,这样会减少垃圾回收之后堆内存重新分配大小的次数,提高效率.
《Java 虚拟机规范》规定,堆可以处于物理上不连续的内存空间中,但逻辑上它应该被视为连续的.
所有的线程共享 Java 堆,在这里还可以划分线程私有的缓冲区.
《Java 虚拟机规范》中对 Java 堆的描述是:所有的对象实例都应当在运行时分配在堆上.
在方法结束后,堆中的对象不会马上被移除,仅仅在垃圾收集的时候才会被移除。
堆是 GC(Garbage Collection,垃圾收集器)执行垃圾回收的重点区域.
Java8 及之后堆内存分为:新生区(新生代)+老年区(老年代)
新生区分为 Eden(伊甸园)区和 Survivor(幸存者)区
为什么分区(代)
为新对象分配内存是一件非常严谨和复杂的任务,JVM 的设计者们不仅需要考虑内存如何分配,在哪分配等问题,并且由于内存分配算法与内存回收算法密切相关,所以还需要考虑 GC 执行完内存回收后是否会在内存空间中产生内存碎片。
JVM 在进行 GC 时,并非每次都新生区和老年区一起回收的,大部分时候回收的都是指新生区.针对 HotSpot VM 的实现,它里面的 GC 按照回收区域又分为两大类型:一种是部分收集,一种是整堆收集.
部分收集:不是完整收集整个 java 堆的垃圾收集.其中又分为:
收集整个 java 堆和方法区的垃圾收集.整堆收集出现的情况:
System.gc();时
老年区空间不足
方法区空间不足
开发期间尽量避免整堆收集
-XX:+PrintFlagsInitial
查看所有参数的默认初始值
-XX:+PrintFlagsFinal
查看所有参数的最终值(修改后的值)
-Xms
初始堆空间内存(默认为物理内存的 1/64)
-Xmx
最大堆空间内存(默认为物理内存的 1/4)
-Xmn
设置新生代的大小(初始值及最大值)
-XX:NewRatio
配置新生代与老年代在堆结构的占比
-XX:SurvivorRatio
设置新生代中 Eden 和 S0/S1 空间比例
-XX:MaxTenuringTreshold
设置新生代垃圾的最大年龄
XX:+PrintGCDetails
输出详细的 GC 处理日志
JDK7 及以后的版本中将字符串常量池放到了堆空间中。因为方法区的回收效率很低,在 Full GC 的时候才会执行永久代的垃圾回收,而 Full GC 是老年代的空间不足、方法区不足时才会触发。这就导致字符串常量池回收效率不高,而我们开发中会有大量的字符串被创建,回收效率低,导致永久代内存不足。放到堆里,能及时回收内存。
方法区,是一个被线程共享的内存区域。其中主要存储加载的类字节码、class/method/field 等元数据、static final 常量、static 变量、即时编译器编译后的代码等数据。另外,方法区包含了一个特殊的区域“运行时常量池”。
Java 虚拟机规范中明确说明:”尽管所有的方法区在逻辑上是属于堆的一部分,但对HotSpotJVM 而言,方法区还有一个别名叫做 Non-Heap(非堆),目的就是要和堆分开.
所以,方法区看做是一块独立于 java 堆的内存空间.
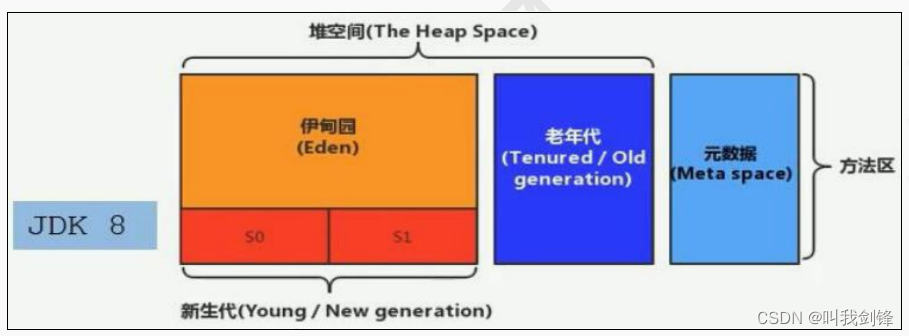
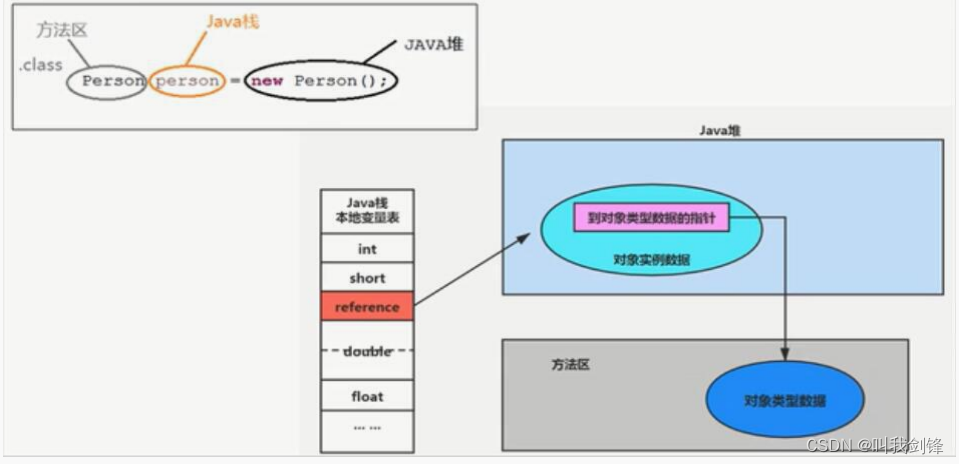
Java 方法区的大小不必是固定的,JVM 可以根据应用的需要动态调整.
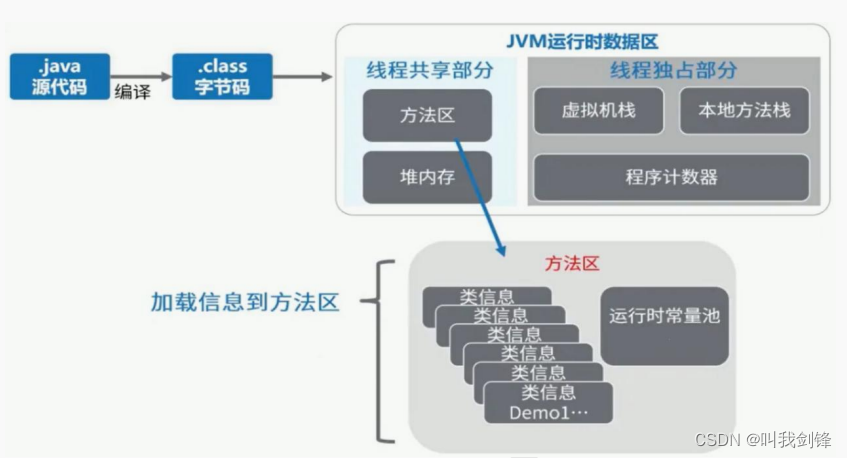
方法区它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存,运行常量池等。
运行常量池就是一张表,虚拟机指令根据这张表,找到要执行的类名、方法名、参数类型、字面量(常量)等信息,存放编译期间生成的各种字面量(常量)和符号引用。
通过反编译字节码文件查看
反编译字节码文件,并输出值文本文件中,便于查看。参数 -p 确保能查看private 权限类型的字段或方法
javap -v -p Demo.class > test.txt
方法区的垃圾收集主要回收两部分内容:运行时常量池中废弃的常量和不再使用的类型。
下面也称作类卸载
判定一个常量是否“废弃”还是相对简单,而要判定一个类型是否属于“不再被使用的类”的条件就比较苛刻了。需要同时满足下面三个条件:
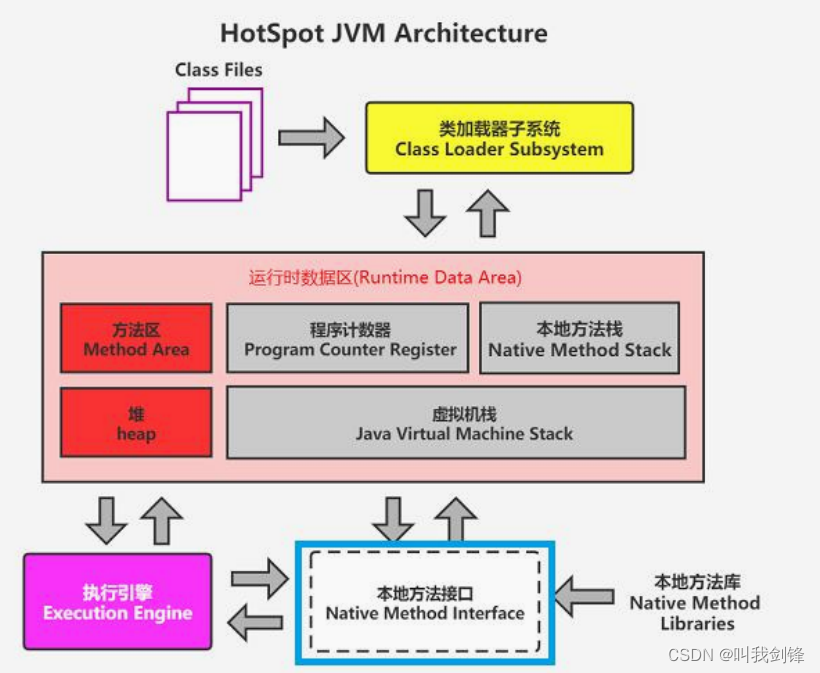
简单来讲, 一个 Native Method 就是一个 java 调用非 java 代码的接口 ,一个Native Method 是这样一个 java 方法:该方法的底层实现由非 Java 语言实现,比如 C。这个特征并非 java 特有,很多其他的编程语言都有这一机制在定义一个 native method 时,并不提供实现体(有些像定义一个 Java interface),因为其实现体是由非 java 语言在外面实现的。
关键字 native 可以与其他所有的 java 标识符连用,但是 abstract 除外。
Java 使用起来非常方便,然而有些层次的任务用 java 实现起来不容易,或者我们对程序的效率很在意时,问题就来了。
注意区分概念:
起初将 Java 语言定位为“解释执行”还是比较准确的。再后来,Java 也发展出可以直接生成本地代码的编译器。现在 JVM 在执行 Java 代码的时候,通常都会将解释执行与编译执行二者结合起来进行。
原因:
JVM 设计者们的初衷仅仅只是单纯地为了满足 Java 程序实现跨平台特性,因此避免采用静态编译的方式由高级语言直接生成本地机器指令,从而诞生了实现解释器在运行时采用逐行解释字节码执行程序的想法。
解释器真正意义上所承担的角色就是一个运行时“翻译者”,将字节码文件中的内容“翻译”为对应平台的本地机器指令执行,执行效率低。
JIT 编译器将字节码翻译成本地代码后,就可以做一个缓存操作,存储在方法区的 JIT 代码缓存中(执行效率更高了)。
是否需要启动 JIT 编译器将字节码直接编译为对应平台的本地机器指令,则需要根据代码被调用执行的频率而定。
JIT 编译器在运行时会针对那些频繁被调用的“热点代码”做出深度优化,将其直接编译为对应平台的本地机器指令,以此提升 Java 程序的执行性能。
一个被多次调用的方法,或者是一个方法体内部循环次数较多的循环体都可以被称之为“热点代码”。
目前 HotSpot VM 所采用的热点探测方式是基于计数器的热点探测。
JIT 编译器执行效率高为什么还需要解释器?
当程序启动后,解释器可以马上发挥作用,响应速度快,省去编译的时间,立即执行。
编译器要想发挥作用,把代码编译成本地代码,需要一定的执行时间,但编译为本地代码后,执行效率高。就需要采用解释器与即时编译器并存的架构来换取一个平衡点。
Java 和 C语言的区别,就在于垃圾收集技术和内存动态分配上,C语言没有垃圾收集技术,需要程序员手动的收集
垃圾收集机制是 Java 的招牌能力,极大地提高了开发效率。如今,垃圾收集几乎成为现代语言的标配,即使经过如此长时间的发展,Java 的垃圾收集机制仍然在不断的演进中,不同大小的设备、不同特征的应用场景,对垃圾收集提出了新的挑战。
在早期的 C/C++时代,垃圾回收基本上是手工进行的。开发人员可以使用 new关键字进行内存申请,并使用 delete 关键字进行内存释放。
这种方式可以灵活控制内存释放的时间,但是会给开发人员带来频繁申请和释放内存的管理负担。倘若有一处内存区间由于程序员编码的问题忘记被回收,那么就会产生内存泄漏 ,垃圾对象永远无法被清除,随着系统运行时间的不断增长,垃圾对象所耗内存可能持续上升,直到出现内存溢出并造成应用程序崩溃。
现在,除了 Java 以外,C#、Python、Ruby 等语言都使用了自动垃圾回收的思想,也是未来发展趋势,可以说这种自动化的内存分配和来及回收方式已经成为了现代开发语言必备的标准。
自动内存管理的优点
自动内存管理的担忧
应该关心哪些区域的回收
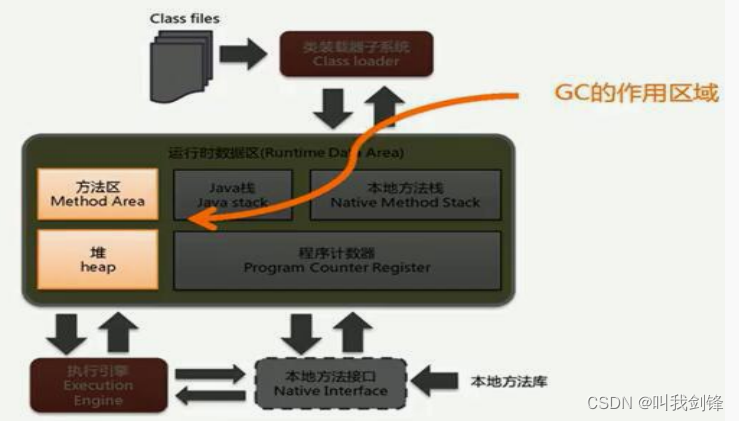
垃圾收集器可以对年轻代回收,也可以对老年代回收,甚至是全栈和方法区的回收,其中,Java 堆是垃圾收集器的工作重点
从次数上讲:
目的:主要是为了判断对象是否是垃圾对象
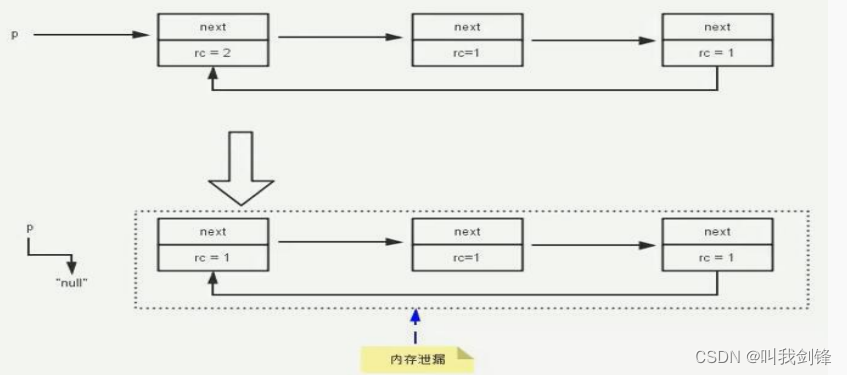
obj1.name = obj2 // 对象循环obj2.name = obj1 // 引用数值并不为0 ,不会释放空间,造成空间浪费也可以称为根搜索算法、追踪性垃圾收集
相对于引用计数算法而言,可达性分析算法不仅同样具备实现简单和执行高效等特点,更重要的是该算法可以有效地解决在引用计数算法中循环引用的问题,防止内存泄漏的发生。
相较于引用计数算法,这里的可达性分析就是 Java、C#选择的。这种类型的垃圾收集通常也叫作追踪性垃圾收集(Tracing Garbage Collection)
所谓"GCRoots”根就是一组必须活跃的引用
其基本思路如下:
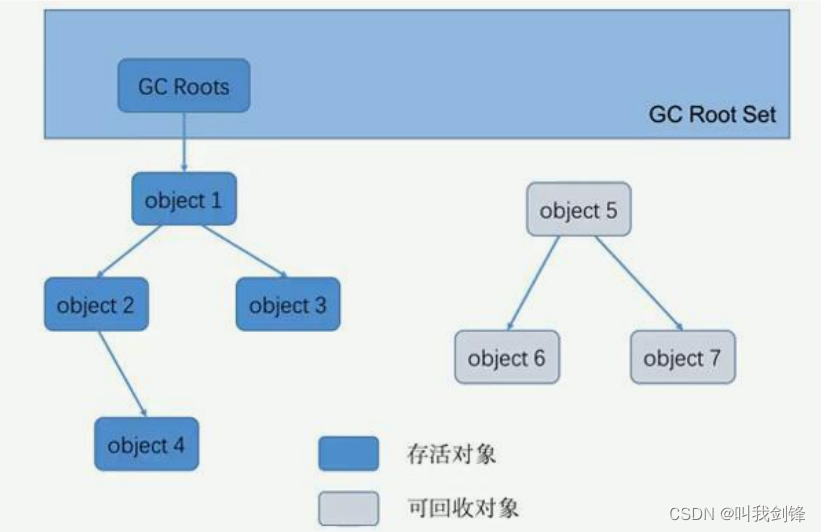
GC Roots 可以是哪些元素
finalize() 方法机制:对象销毁前的回调方法:finalize();
永远不要主动调用某个对象的 finalize()方法,应该交给垃圾回收机制调用。理由包括下面三点:
生存还是死亡
由于 finalize()方法的存在,虚拟机中的对象一般处于三种可能的状态。
如果从所有的根节点都无法访问到某个对象,说明对象己经不再使用了。一般来说,此对象需要被回收。但事实上,也并非是“非死不可”的,这时候它们暂时处于“缓刑”阶段。一个无法触及的对象有可能在某一个条件下“复活”自己,如果这样,那么对它立即进行回收就是不合理的。
为此,定义虚拟机中的对象可能的三种状态 。如下:
以上 3 种状态中,是由于 finalize()方法的存在,进行的区分。只有在对象不可触及时才可以被回收。
具体过程
判定一个对象 objA 是否可回收,至少要经历两次标记过程:
finalize() 方法可复活对象
第一次自救成功,但由于 finalize() 方法只会执行一次,所以第二次自救失败。
它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。在垃圾回收时将正在使用的内存中的存活对象复制到未被使用的内存块中,之后清除正在使用的内存块中的所有对象,交换两个内存的角色,最后完成垃圾回收。
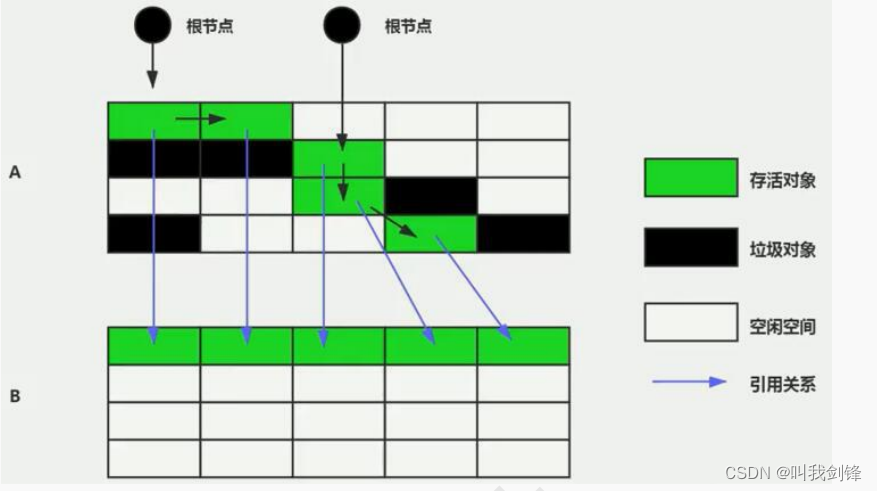
复制算法的优缺点
复制算法的应用场景
执行过程
当堆中的有效内存空间被耗尽的时候,然后进行这项工作.
**清除:**这里所谓的清除并不是真的置空,而是把需要清除的对象地址保存在空闲的地址列表里。下次有新对象需要加载时,判断垃圾的位置空间是否够,如果够,就存放(也就是覆盖原有的地址)
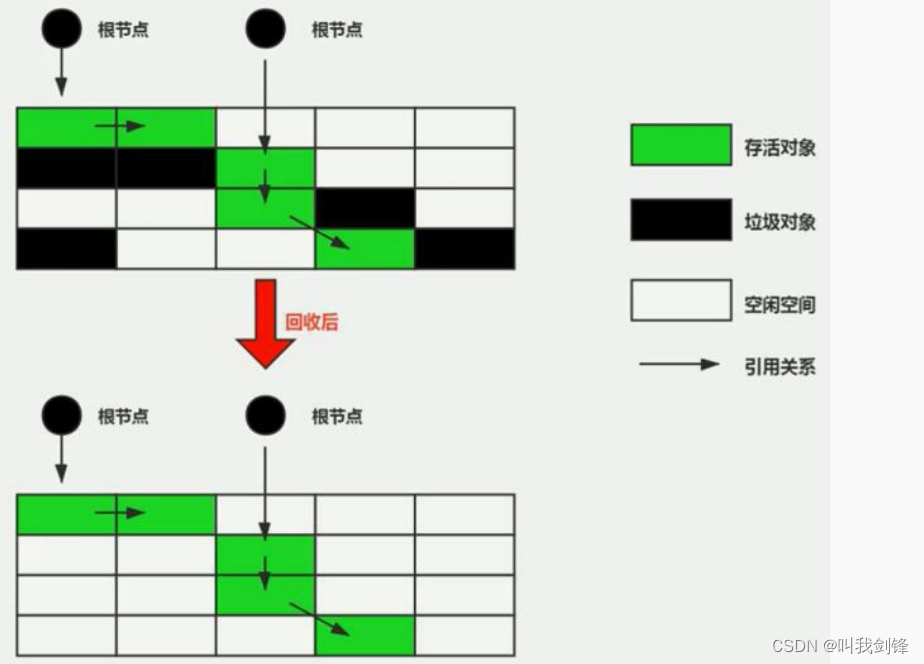
标记-清除算法的优点:
非常基础和常见的垃圾收集算法容易理解
标记-清除算法的缺点:
标记清除算法的效率不算高
这种方式清理出来的空闲内存是不连续的,产生内碎片。
背景
复制算法的高效性是建立在存活对象少、垃圾对象多的前提下的。这种情况在新生代经常发生,但是在老年代,更常见的情况是大部分对象都是存活对象。 如果依然使用复制算法,由于存活对象较多,复制的成本也将很高。因此,基于老年代垃圾回收的特性,需要使用其他的算法。
标记-清除算法的确可以应用在老年代中,但是该算法不仅执行效率低下,而且在执行完内存回收后还会产生内存碎片,所以 JVM 的设计者需要在此基础之上进行改进
执行过程
第一阶段和标记清除算法一样,从根节点开始标记所有被引用对象
第二阶段将所有的存活对象压缩到内存的一端,按顺序排放。之后,清理边界外所有的空间。
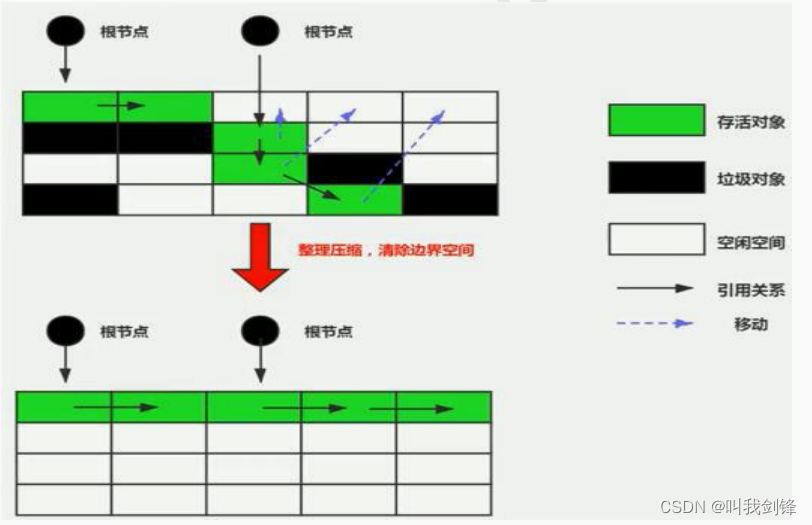
与标记-清除算法的比较
标记-压缩算法的优缺点
优点
消除了标记-清除算法当中,内存区域分散的缺点,我们需要给新对象分配内存时,JVM 只需要持有一个内存的起始地址即可。
消除了复制算法当中,内存减半的高额代价。
缺点
效率上来说,复制算法是当之无愧的老大,但是却浪费了太多内存。而为了尽量兼顾上面提到的三个指标,标记-压缩算法相对来说更平滑一些,但是效率上不尽如人意,它比复制算法多了一个标记的阶段,比标记-清除多了一个整理内存的阶段。
| 标记清除 | 标记整理 | 复制 | |
|---|---|---|---|
| 速率 | 中等 | 最慢 | 最快 |
| 空间开销 | 少(会堆积碎片) | 少(无堆积碎片) | 通常需要活动对象的两倍空间(无堆积碎片) |
| 移动对象 | 否 | 是 | 是 |
年轻代(Young Gen)
年轻代特点:区域相对老年代较小,对象生命周期短、存活率低,回收频繁。
这种情况复制算法的回收整理,速度是最快的。复制算法的效率只和当前存活对象大小有关,因此很适用于年轻代的回收。而复制算法内存利用率不高的问题,通过 hotspot 中的两个 survivor 的设计得到缓解。
老年代(Tenured Gen)
老年代特点:区域较大,对象生命周期长、存活率高,回收不及年轻代频繁。
这种情况存在大量存活率高的对象,复制算法明显变得不合适。一般是由标记- 清除或者是标记-清除与标记-压缩的混合实现。
Mark 阶段的开销与存活对象的数量成正比。
Sweep 阶段的开销与所管理区域的大小成正相关。
Compact 阶段的开销与存活对象的数据成正比。
分代的思想被现有的虚拟机广泛使用。几乎所有的垃圾回收器都区分新生代和老年代。
在默认情况下,通过 System.gc()者 Runtime.getRuntime().gc() 的调用,会显式触发 Full GC,同时对老年代和新生代进行回收,尝试释放被丢弃对象占用的内存。
然而 System.gc()调用附带一个免责声明,无法保证对垃圾收集器的调用(不能确保立即生效)。
JVM 实现者可以通过 System.gc() 调用来决定 JVM 的 GC 行为。而一般情况下,垃圾回收应该是自动进行的,无须手动触发,否则就太过于麻烦了。在一些特殊情况下,我们可以在运行之间调用 System.gc()。
内存溢出
内存溢出相对于内存泄漏来说,尽管更容易被理解,但是同样的,内存溢出也是引发程序崩溃的罪魁祸首之一。
由于 GC 一直在发展,所有一般情况下,除非应用程序占用的内存增长速度非常快,造成垃圾回收已经跟不上内存消耗的速度,否则不太容易出现 OOM 的情况。
大多数情况下,GC 会进行各种年龄段的垃圾回收,实在不行了就放大招,来一次独占式的 Full GC 操作,这时候会回收大量的内存,供应用程序继续使用。
Javadoc 中对 OutofMemoryError 的解释是,没有空闲内存,并且垃圾收集器也无法提供更多内存。
内存泄漏
内存泄漏也称作“存储渗漏”。严格来说,只有对象不会再被程序用到了,但是 GC 又不能回收他们的情况,才叫内存泄漏。
但实际情况很多时候一些不太好的实践(或疏忽)会导致对象的生命周期变得很长甚至导致 OOM,也可以叫做宽泛意义上的“内存泄漏”。
尽管内存泄漏并不会立刻引起程序崩溃,但是一旦发生内存泄漏,程序中的可用内存就会被逐步蚕食,直至耗尽所有内存,最终出现 OutofMemory 异常,导致程序崩溃。
注意,这里的存储空间并不是指物理内存,而是指虚拟内存大小,这个虚拟内存大小取决于磁盘交换区设定的大小。
常见例子
Stop-the-World,简称 STW,指的是 GC 事件发生过程中,会产生应用程序的停顿。停顿产生时整个应用程序线程都会被暂停,没有任何响应,有点像卡死的感觉,这个停顿称为 STW。
可达性分析算法中枚举根节点(GC Roots)会导致所有 Java 执行线程停顿,为什么需要停顿所有 Java 执行线程呢?
单线程垃圾回收器(Serial)
只有一个线程进行垃圾回收,使用于小型简单的使用场景,垃圾回收时,其他用户线程会暂停.
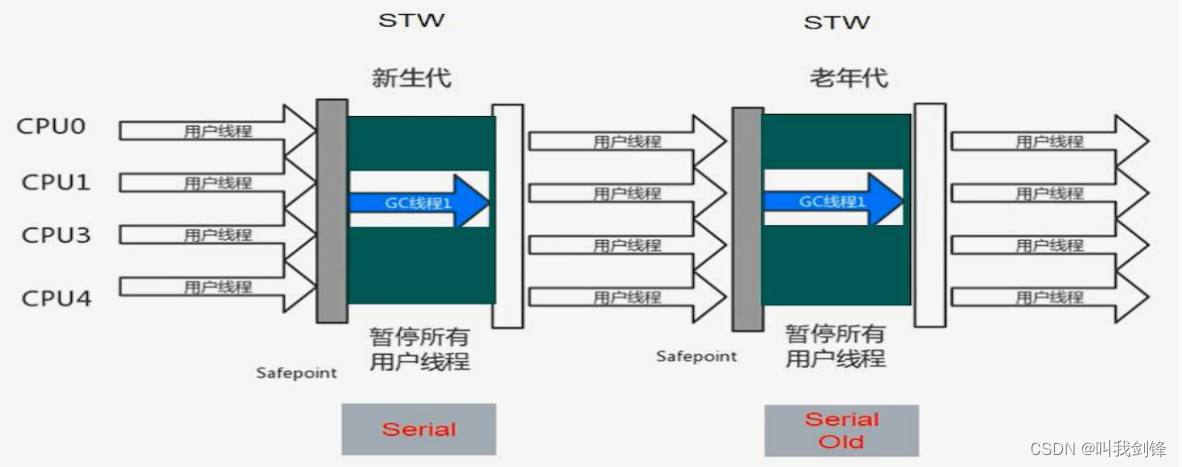
多线程垃圾回收器(Parallel)
多线程垃圾回收器内部提供多个线程进行垃圾回收,在多 cpu 情况下大大提升垃圾回收效率,但同样也是会暂停其他用户线程.
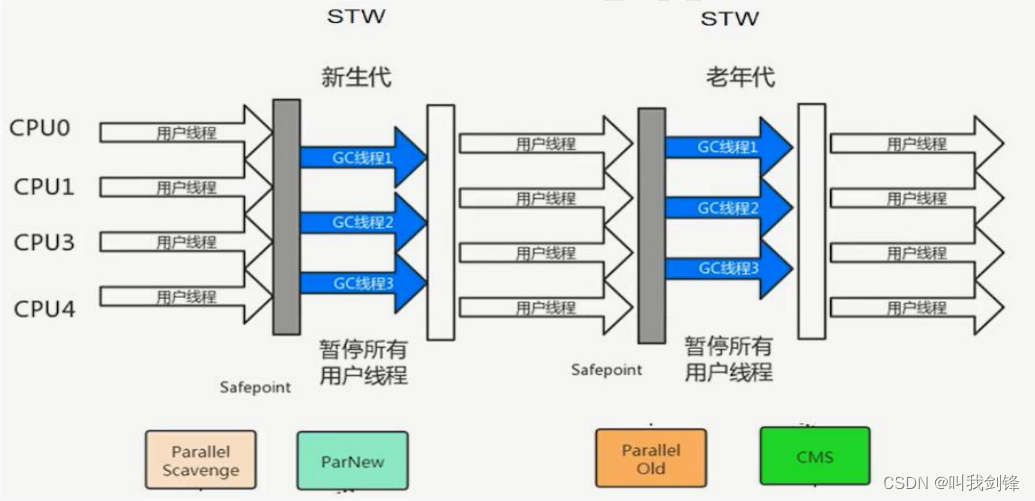

吞吐量:运行用户代码的时间占总运行时间的比例(总运行时间:程序的运行时间+ 内存回收的时间)
暂停时间:执行垃圾收集时,程序的工作线程被暂停的时间。
内存占用:Java 堆区所占的内存大小。
快速:一个对象从诞生到被回收所经历的时间。
图中展示了 7 种作用于不同分代的收集器,如果两个收集器之间存在连线,则说明它们可以搭配使用。虚拟机所处的区域则表示它是属于新生代还是老年代收集器。
CMS概述
CMS(Concurrent Mark Sweep,并发标记清除)收集器是以获取最短回收停顿时间为目标的收集器(追求低停顿),它在垃圾收集时使得用户线程和 GC 线程并发执行,因此在垃圾收集过程中用户也不会感到明显的卡顿。
垃圾回收过程
并发标记与并发清除过程耗时最长,且可以与用户线程一起工作,因此,总体上 说,CMS 收集器的内存回收过程是与用户线程一起并发执行的。
CMS的优点:
CMS 的弊端:
三色标记算法
为了提高 JVM 垃圾回收的性能,从 CMS 垃圾收集器开始,引入了并发标记的概念。引入并发标记的过程就会带来一个问题,在业务执行的过程中,会对现有的引用关系链出现改变。
三色标记法将对象的颜色分为了黑、灰、白,三种颜色。
三色标记的过程:
为了解决并发的问题,引入中间状态(灰色),当一个对象被标记的时候,会有下面几个过程:
这个过程正确执行的前提是没有其他线程改变对象间的引用关系,然而,并发标记的过程中,用户线程仍在运行,因此就会产生漏标和错标的情况。
漏标
假设 GC 已经在遍历对象 B 了,而此时用户线程执行了 A.B=null 的操作,切断了 A 到 B 的引用
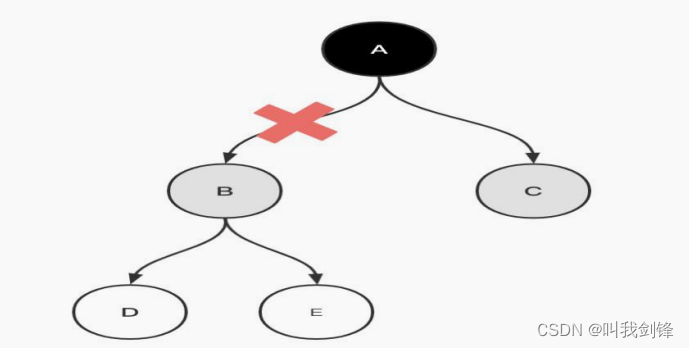
本来执行了 A.B=null 之后,B、D、E 都可以被回收了,但是由于 B 已经变为灰色,它仍会被当做存活对象,继续遍历下去。最终的结果就是本轮 GC 不会回收 B、D、E,留到下次 GC 时回收,也算是浮动垃圾的一部分。
错标
假设 GC 线程已经遍历到 B 了,此时用户线程执行了以下操作:
B.D=null;//B 到 D 的引用被切断
A.xx=D;//A 到 D 的引用被建立
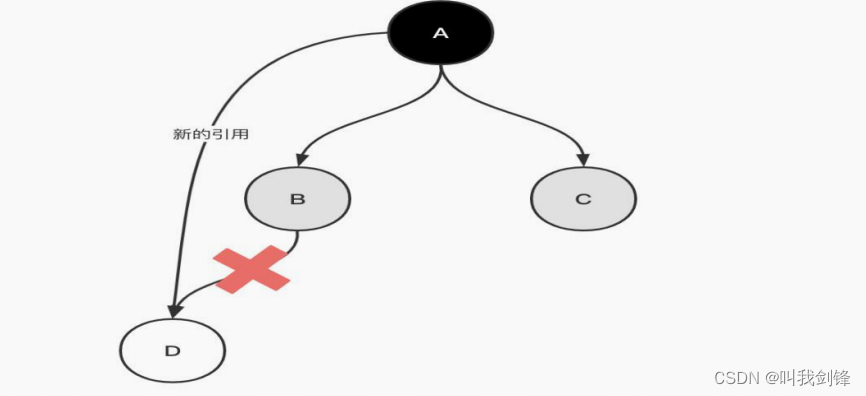
B 到 D 的引用被切断,且 A 到 D 的引用被建立。
此时 GC 线程继续工作,由于 B 不再引用 D 了,尽管 A 又引用了 D,但是因为 A 已经标记为黑色,GC 不会再遍历 A 了,所以 D 会被标记为白色,最后被当做垃圾回收。
可以看到错标的结果比漏表严重的多,浮动垃圾可以下次 GC 清理,而把不该回收的对象回收掉,将会造成程序运行错误。
解决错标的问题
错标只有在满足下面两种情况下才会发生:
只要打破任一条件,就可以解决错标的问题。
原始快照和增量更新
原始快照打破的是第一个条件:当灰色对象指向白色对象的引用被断开时,就将这条引用关系记录下来。当扫描结束后,再以这些灰色对象为根,重新扫描一次。
增量更新打破的是第二个条件:当黑色指向白色的引用被建立时,就将这个新的引用关系记录下来,等扫描结束后,再以这些记录中的黑色对象为根,重新扫描一次。相当于黑色对象一旦建立了指向白色对象的引用,就会变为灰色对象。
总结
CMS 为了让 GC 线程和用户线程一起工作,回收的算法和过程比以前旧的收集器要复杂很多。究其原因,就是因为 GC 标记对象的同时,用户线程还在修改对象的引用关系。因此 CMS 引入了三色算法,将对象标记为黑、灰、白三种颜色的对象,将用户线程修改的引用关系记录下来,以便在「重新标记」阶段可以修正对象的引用。
虽然 CMS 从来没有被 JDK 当做默认的垃圾收集器,存在很多的缺点,但是它开启了「GC 并发收集」的先河,为后面的收集器提供了思路。
既然我们已经有了前面几个强大的 GC,为什么还要发布 Garbage First(G1)GC?
原因就在于应用程序所应对的业务越来越庞大、复杂,用户越来越多,没有GC 就不能保证应用程序正常进行,而经常造成 STW 的 GC 又跟不上实际的需求,所以才会不断地尝试对 GC 进行优化。G1(Garbage-First)垃圾回收器是在 Java7 update 4 之后引入的一个新的垃圾回收器,是当今收集器技术发展的最前沿成果之一.
与此同时,为了适应现在不断扩大的内存和不断增加的处理器数量,进一步降低暂停时间(pause time),同时兼顾良好的吞吐量。
官方给 G1 设定的目标是在延迟可控的情况下获得尽可能高的吞吐量,所以才担当起“全功能收集器”的重任与期望。
G1 是一款面向服务端应用的垃圾收集器。
为什么名字叫做 Garbage First(G1)呢?
因为 G1 是一个并行回收器,它把堆内存分割为很多不相关的区域(Region)(物理上不连续的逻辑上连续的)。使用不同的 Region 来表示 Eden、幸存者0 区,幸存者 1 区,老年代等。
G1 GC 有计划地避免在整个 Java 堆中进行全区域的垃圾收集。G1 跟踪各个 Region 里面的垃圾堆积的价值大小(回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region.
由于这种方式的侧重点在于回收垃圾最大量的区间(Region),所以我们给 G1 一个名字:垃圾优先(Garbage First)。
G1(Garbage-First)是一款面向服务端应用的垃圾收集器,主要针对配备多核 CPU 及大容量内存的机器,以极高概率满足 GC 停顿时间的同时,还兼具高吞吐量的性能特征。
如下图所示,G1 收集器收集器收集过程有初始标记、并发标记、最终标记、筛选回收,和 CMS 收集器前几步的收集过程很相似:
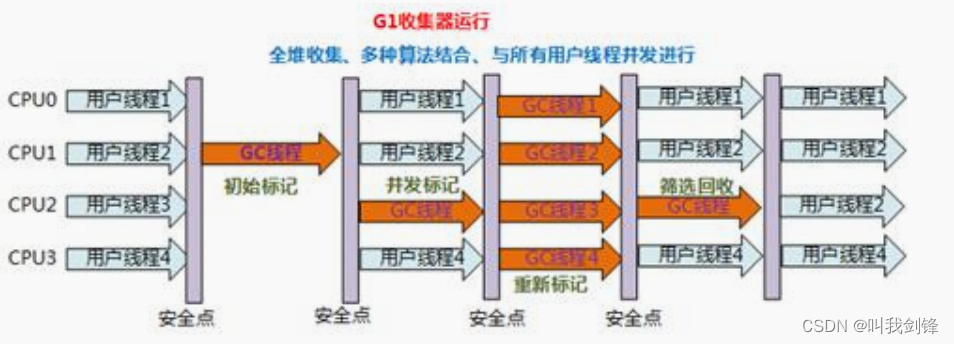
适用场景:要求尽可能可控 GC 停顿时间;内存占用较大的应用。
打印默认垃圾回收器
-XX:+PrintCommandLineFlags -versionJDK 8 默认的垃圾回收器
年轻代使用 Parallel Scavenge GC
老年代使用 Parallel Old GC
打印垃圾回收详细信息
-XX:+PrintGCDetails -version设置默认垃圾回收器
# 年轻代使用 Serial GC,老年代使用 Serial Old GC-XX:+UseSerialGC # 年轻代使用 ParNew GC,不影响老年代。-XX:+UseParNewGC # 老年代使用 CMS GC。-XX:+UseConcMarkSweepGC # 手动指定使用 G1 收集器执行内存回收任务。-XX:+UseG1GC # 设置每个 Region 的大小。-XX:G1HeapRegionSize 因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-netdocker pull docker.elastic.co/elasticsearch/elasticsearch:8.9.0docker run -d \--name es \-e "http.host=0.0.0.0" \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "discovery.type=single-node" \ -v /home/docker_data/elasticsearch/data:/usr/share/elasticsearch/data \ -v /home/docker_data/elasticsearch/logs:/usr/share/elasticsearch/logs \ -v /home/docker_data/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network es-net \ -p 9200:9200 \ -p 9300:9300 \docker.elastic.co/elasticsearch/elasticsearch:8.9.0命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net :加入一个名为es-net的网络中-p 9200:9200:端口映射配置进入容器
docker exec -it 容器id /bin/bash修改elasticsearch配置文件,首先进入config目录,目录中有个名为elasticsearch.yml的配置文件,在配置文件中加上一行xpack.security.enabled: true,代表启用xpack进行账号密码验证,命令如下:
cd configvi elasticsearch.yml在elasticsearch,yml加上xpack.security.enabled: true,然后:wq保存退出,重启elasticsearch
在容器中显示 bash: vim: command not found,需要执行以下命令:
apt-get updateapt-get install -y vim若显示权限不足:E: List directory /var/lib/apt/lists/partial is missing. - Acquire (13: Permission denied),则用 docker exec -u 0 -it id /bin/bash 代替 docker exec -it id /bin/bash 进入容器
再次进入容器中,在进入bin目录,执行以下命令
docker exec -it db-容器名 /bin/bashcd bin./elasticsearch -d稍等一会执行./elasticsearch-setup-passwords interactive,这时候就需要为一些默认账户设置密码,这里会设置六个账号的密码:elastic,apm_system,kibana,logstash_system,beats_system,remote_monitoring_user,需要根据提示逐一设置密码。设置好之后妥善保存,设置完成之后重启elasticsearch,然后打开浏览器访问服务器9200端口,弹出账号密码输入框代表配置成功
docker pull docker.elastic.co/kibana/kibana:8.9.0docker run -d \--name kibana \-v /home/docker_data/kibana/config:/usr/share/kibana/config \-v /home/docker_data/kibana/data:/usr/share/kibana/data \-e ELASTICSEARCH_HOSTS=http://es:9200 \--network=es-net \-p 5601:5601 \docker.elastic.co/kibana/kibana:8.9.0--network es-net :加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana查看运行日志
做的卷的挂载-v /home/docker_data/kibana/config:/usr/share/kibana/config \,如果没有,可以直接命令:docker exec -it kibana bash,elasticsearch同样可以做挂载-v es-data:/usr/share/elasticsearch/config
添加以下内容:
elasticsearch.username: "elastic"elasticsearch.password: "es中设置的密码"保存配置文件后,退出容器,重启kibana容器: docker restart
输入kibana的访问地址:http://ip:5601
# 拉取minio最新版docker pull minio/minio# 运行minio,密码设置有一定要求docker run -d -p 9000:9000 -p 9001:9001 --name minio -v /data/minio-data:/data -e "MINIO_ROOT_USER=admin" -e "MINIO_ROOT_PASSWORD=141421Hss" minio/minio server /data --console-address ":9001"# 查看日志docker logs minio# 开启服务器安全组规则中的9000和9001端口# 访问minio控制台 http://ip:9001
在服务器中会生成一个和桶名称相同的文件夹
设置桶规则;修改权限public,设置规则为readwrite
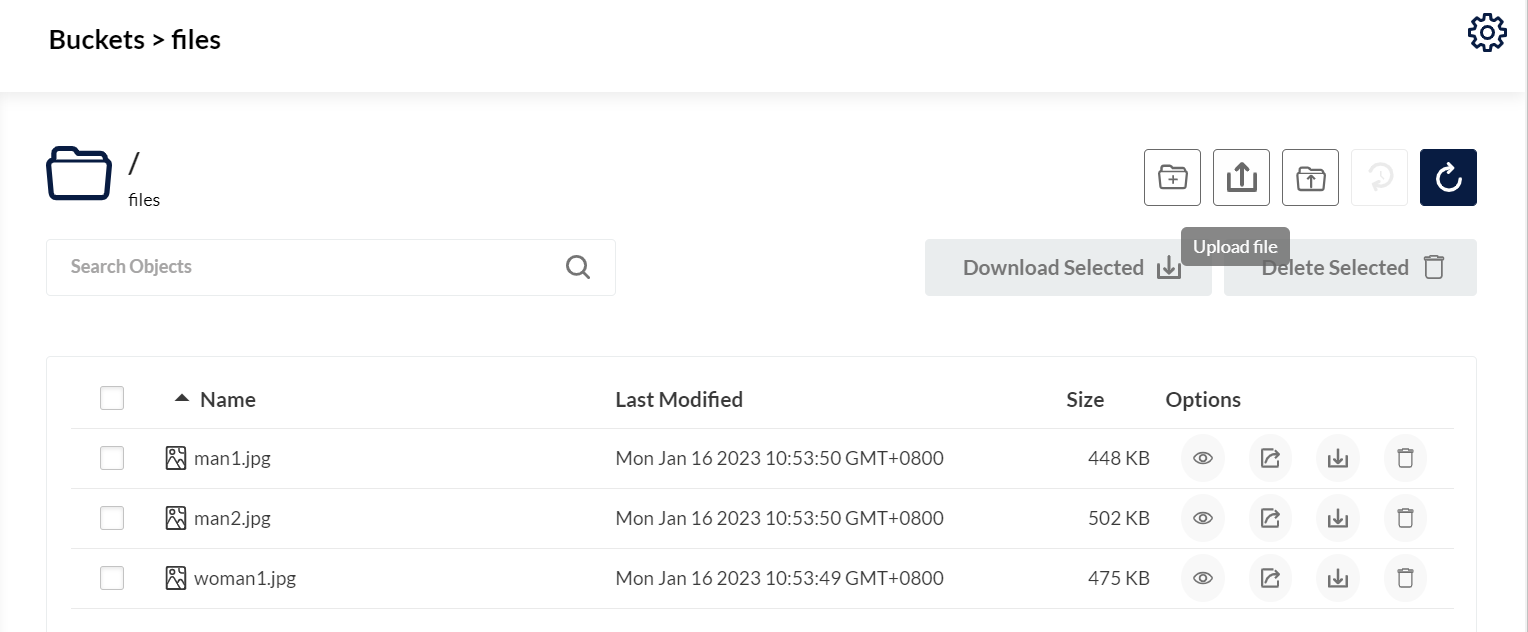
上传完文件之后,在服务器的桶中会生成一个文件
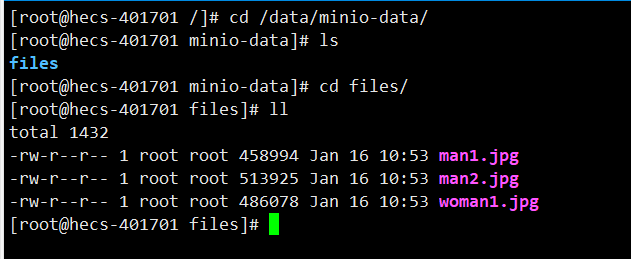
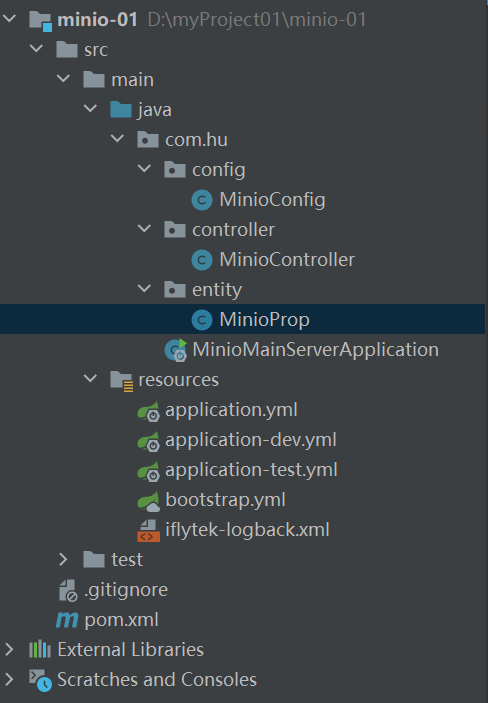
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.2.13.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>org.hu</groupId> <artifactId>minio-01</artifactId> <version>1.0-SNAPSHOT</version> <packaging>jar</packaging> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <java.version>1.8</java.version> <lomback.version>1.8.4</lomback.version> <spring-cloud.version>Hoxton.SR9</spring-cloud.version> <spring-cloud-alibaba.version>2.2.5.RELEASE</spring-cloud-alibaba.version> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <!--引入springcloud的版本--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>io.minio</groupId> <artifactId>minio</artifactId> <version>8.4.6</version> </dependency> <dependency> <groupId>com.squareup.okhttp3</groupId> <artifactId>okhttp</artifactId> <version>4.9.1</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.4</version> </dependency> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.5</version> </dependency> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.2</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.8</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpmime</artifactId> </dependency> <dependency> <groupId>com.auth0</groupId> <artifactId>java-jwt</artifactId> <version>3.3.0</version> </dependency> <!--nacos配置中心--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> <version>2.2.5.RELEASE</version> </dependency> <!--加入nocas-client 服务发现--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> <version>2.2.5.RELEASE</version> </dependency> </dependencies> <repositories> <repository> <id>mvn-releases</id> <name>Public Repositories</name> <url>https://artifacts.iflytek.com/artifactory/mvn-repo/</url> </repository> <repository> <id>aliyun-repos</id> <name>Aliyun Repository</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </repository> </repositories> <profiles> <profile> <id>dev</id> <activation> <activeByDefault>true</activeByDefault> </activation> <properties> <profile.active>dev</profile.active> <profile.namespace>74d06a53-0810-44fe-ab92-27603c1eecd3</profile.namespace> </properties> </profile> <profile> <id>test</id> <properties> <profile.active>test</profile.active> <profile.namespace>74d06a53-0810-44fe-ab92-27603c1eecd3</profile.namespace> </properties> </profile> </profiles></project>package com.hu.entity;import lombok.Data;import org.springframework.beans.factory.annotation.Value;import org.springframework.boot.context.properties.ConfigurationProperties;import org.springframework.context.annotation.Configuration;import org.springframework.stereotype.Component;/** * @Author : sshu10 * @create 2023/1/16 14:04 */@Data@Configurationpublic class MinioProp { /** * 连接url */ @Value("${minio.endpoint}") private String endpoint; /** * 用户名 */ @Value("${minio.accesskey}") private String accesskey; /** * 密码 */ @Value("${minio.secretKey}") private String secretKey; /** * 桶名称 */ @Value("${minio.bucketName}") private String bucketName;}package com.hu.controller;import cn.hutool.core.lang.UUID;import com.alibaba.fastjson.JSONObject;import com.hu.entity.MinioProp;import io.minio.*;import lombok.SneakyThrows;import lombok.extern.slf4j.Slf4j;import org.apache.commons.lang3.StringUtils;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.validation.annotation.Validated;import org.springframework.web.bind.annotation.*;import org.springframework.web.multipart.MultipartFile;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;import java.io.InputStream;import java.io.OutputStream;import java.net.URLEncoder;/** * @Author : sshu10 * @create 2023/1/16 14:30 */@RestController@RequestMapping("/minio")@Validated@Slf4jpublic class MinioController { @Autowired private MinioClient minioClient; @Autowired private MinioProp minioProp; /** * 判断桶存在不存在,不存在创建桶 * @Author sshu * @Description * @param bucketName * @return void **/ @SneakyThrows public void createBucket(String bucketName) { if (minioClient.bucketExists(BucketExistsArgs.builder().bucket(bucketName).build())) { return; } minioClient.makeBucket(MakeBucketArgs.builder().bucket(bucketName).build()); } @SneakyThrows public InputStream getObjectInputStream(String objectName, String bucketName){ GetObjectArgs getObjectArgs = GetObjectArgs.builder() .bucket(bucketName) .object(objectName) .build(); return minioClient.getObject(getObjectArgs); } /** * 上传 * @param file * @return * @throws Exception */ @PostMapping("/post/uploadFile") public JSONObject uploadFile(@RequestBody MultipartFile file, String fileName) throws Exception { JSONObject res = new JSONObject(); res.put("code", 0); // 判断上传文件是否为空 if (null == file || 0 == file.getSize()) { res.put("msg", "上传文件不能为空"); return res; } InputStream is=null; try { // 判断存储桶是否存在 createBucket(minioProp.getBucketName()); // 文件名 String originalFilename = file.getOriginalFilename(); // 新的文件名 = 存储桶名称_时间戳.后缀名 if(StringUtils.isEmpty(fileName)){ fileName = minioProp.getBucketName() + "_" + UUID.fastUUID().toString().replaceAll("-", "") + originalFilename.substring(originalFilename.lastIndexOf(".")); } // 开始上传 is=file.getInputStream(); PutObjectArgs putObjectArgs = PutObjectArgs.builder() .bucket(minioProp.getBucketName()) .object(fileName) .contentType(file.getContentType()) .stream(is, is.available(), -1) .build(); minioClient.putObject(putObjectArgs); res.put("code", 1); res.put("msg", minioProp.getBucketName() + "/" + fileName); res.put("bucket", minioProp.getBucketName()); res.put("fileName", fileName); return res; } catch (Exception e) { e.printStackTrace(); log.error("上传文件失败:{}", e.getMessage()); }finally { is.close(); } res.put("msg", "上传失败"); return res; } /** * 下载 * @param fileName * @param realFileName * @param response * @param request */ @GetMapping("/get/downloadFile") public void downloadFile(String fileName, String realFileName, HttpServletResponse response, HttpServletRequest request) { InputStream is=null; OutputStream os =null; try { is = getObjectInputStream(fileName, minioProp.getBucketName()); if(is!=null){ byte buf[] = new byte[1024]; int length = 0; String codedfilename = ""; String agent = request.getHeader("USER-AGENT"); System.out.println("agent:" + agent); if ((null != agent && -1 != agent.indexOf("MSIE")) || (null != agent && -1 != agent.indexOf("Trident"))) { String name = URLEncoder.encode(realFileName, "UTF8"); codedfilename = name; } else if (null != agent && -1 != agent.indexOf("Mozilla")) { codedfilename = new String(realFileName.getBytes("UTF-8"), "iso-8859-1"); } else { codedfilename = new String(realFileName.getBytes("UTF-8"), "iso-8859-1"); } response.reset(); response.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(realFileName.substring(realFileName.lastIndexOf("/") + 1), "UTF-8")); response.setContentType("application/octet-stream"); response.setCharacterEncoding("UTF-8"); os = response.getOutputStream(); // 输出文件 while ((length = is.read(buf)) > 0) { os.write(buf, 0, length); } // 关闭输出流 os.close(); }else{ log.error("下载失败"); } }catch (Exception e){ e.printStackTrace(); log.error("错误:"+e.getMessage()); }finally { if(is!=null){ try { is.close(); } catch (IOException e) { e.printStackTrace(); } } if(os!=null){ try { os.close(); } catch (IOException e) { e.printStackTrace(); } } } } /** * 删除 * @param objectName */ @PostMapping("/post/deleteFile") public void deleteFile(String objectName) { try { RemoveObjectArgs removeObjectArgs = RemoveObjectArgs.builder() .bucket(minioProp.getBucketName()) .object(objectName) .build(); minioClient.removeObject(removeObjectArgs); }catch (Exception e){ log.error("错误:"+e.getMessage()); } }}package com.hu.config;/** * @Author : sshu10 * @create 2023/1/16 14:07 */import com.hu.entity.MinioProp;import io.minio.MinioClient;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configurationpublic class MinioConfig { @Autowired private MinioProp minioProp; @Bean public MinioClient minioClient(){ MinioClient minioClient = MinioClient.builder().endpoint(minioProp.getEndpoint()). credentials(minioProp.getAccesskey(), minioProp.getSecretKey()).region("china").build(); return minioClient; }}server: port: 9999 servlet: context-path: /minio encoding: enabled: true force: true charset: UTF-8spring: profiles: active: @profile.active@ application: name: minio#配置中心nacos: config: # 命名空间ID namespace: 74d06a53-0810-44fe-ab92-27603c1eecd3 # nacos 服务器地址 server-addr: localhost:8848 # nacos 配置的 data-id data-ids: minio # 配置文件 Group group: dev # nacos 配置文件类型 type: yaml # 是否启用动态刷新配置 auto-refresh: true bootstrap: # 这个需要为 true, 否则启动项目时不设置 value默认值会报错,也不会自动更新,请查看 NacosConfigApplicationContextInitializer 文件 enable: true#服务发现中心spring: cloud: nacos: discovery: server-addr: localhost:8848 namespace: 74d06a53-0810-44fe-ab92-27603c1eecd3 group: devspring: application: name: minio cloud: nacos: config: server-addr: ${system.active.nacos.dev.server-addr} namespace: 74d06a53-0810-44fe-ab92-27603c1eecd3 file-extension: yml refresh-enabled: true group: dev encode: UTF-8 discovery: server-addr: ${system.active.nacos.dev.server-addr} namespace: ${system.active.nacos.dev.namespace} group: devsystem.active.nacos: dev: server-addr: localhost:8848 namespace: 74d06a53-0810-44fe-ab92-27603c1eecd3 test: server-addr: localhost:8848 namespace: 74d06a53-0810-44fe-ab92-27603c1eecd3#日志log: path: ${system.logging.dev.path}system.logging: dev: path: /data/sshu/minio-01/logs test: path: logs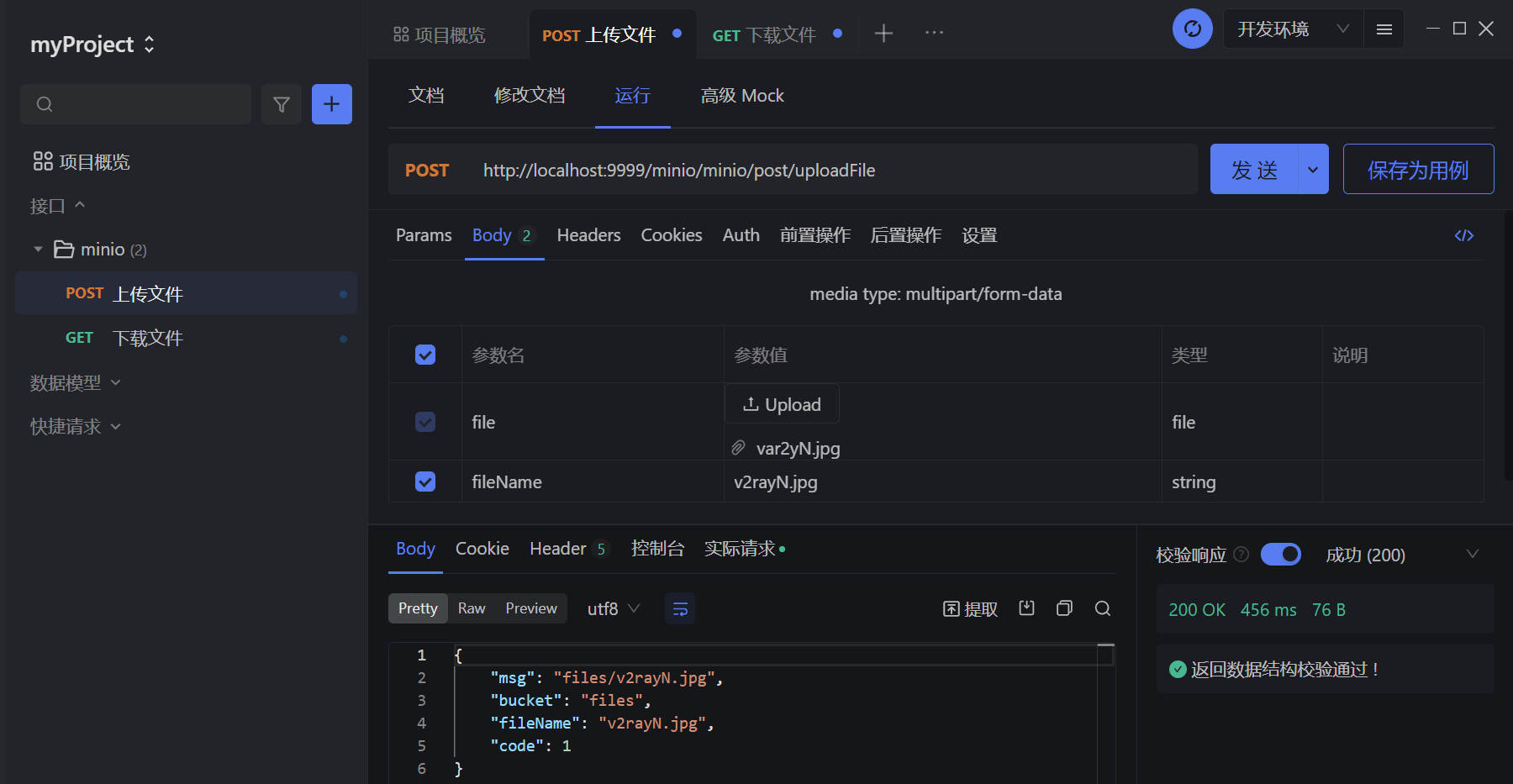
设置镜像加速器
sudo mkdir -p /etc/dockersudo tee /etc/docker/daemon.json <<-'EOF'{ "registry-mirrors": ["https://e45d12yg.mirror.aliyuncs.com"]}EOF# 重新加载配置文件sudo systemctl daemon-reload# 重启dockersudo systemctl restart dockerERROR Unable to initialize backend: format.json file: expected format-type: fs, found: xl-single
删除调挂载目录下的.minio.sys文件即可,因为之前挂载过
cd /data/minio-datals -a .minio.sysrm -rf .minio.sys两台服务器10.10.36.30和10.10.36.31
同一网段的虚拟IP:10.10.36.29
安装编译环境
yum -y install gcc pcre pcre-devel zlib zlib-devel openssl openssl-devel下载安装包并解压
wget https://nginx.org/download/nginx-1.16.1.tar.gztar -zxvf nginx-1.16.1.tar.gz配置编译和安装
./configure --prefix=/usr/local/nginxmake && make install配置为系统服务
vim /lib/systemd/system/nginx.service# nginx.service内容如下[Unit]Description=nginx serviceAfter=network.target [Service]Type=forkingExecStart=/usr/local/nginx/sbin/nginxExecReload=/usr/local/nginx/sbin/nginx -s reloadExecStop=/usr/local/nginx/sbin/nginx -s stopPrivateTmp=true[Install]WantedBy=multi-user.target# 编辑保存后需重新加载系统服务systemctl daemon-reload设置开机启动
# 设置开机启动systemctl enable nginx.service服务的常用命令
#启动nginx服务systemctl start nginx.service #停止服务systemctl stop nginx.service #重新启动服务systemctl restart nginx.service #查看服务当前状态systemctl status nginx.service #设置开机自启动systemctl enable nginx.service # 停止开机自启动systemctl disable nginx.service用yum命令进行安装
yum install keepalived#查看是否已经安装上rpm -q -a keepalived 修改配置文件
# /etc/keepalived目录里面有配置文件keepalived.confvim /etc/keepalived/keepalived.conf# 赋权chmod 644 /etc/keepalived/keepalived.conf# keepalived.conf的内容如下global_defs {router_id keep_30# 唯一标识}# 执行nginx是否启动的脚本,未启动则启动nginx,启动失败则杀死keepalived进程vrrp_script chk_http_port {script "/usr/local/src/nginx_check.sh"interval 5 # 检测脚本执行的间隔:5sweight 5 # 权重,如果这个脚本检测为真,服务器权重+5}vrrp_instance VI_1 {state MASTER # 主服务器为MASTER,备份服务器为BACKUPinterface ens33 # 网卡名称virtual_router_id 51 # 主、备机的virtual_router_id必须相同priority 100 # 主、备机取不同的优先级,主机值较大,备份机值较小advert_int 1 # 每隔1s发送一次心跳authentication {# 校验方式,类型是密码,密码1111 auth type PASS auth pass 1111 }virtual_ipaddress { # 虛拟ip10.10.36.29 # 需要与当前服务器属于同一网段}}创建nginx检测脚本
vim /usr/local/src/nginx_check.shchmod 755 /usr/local/src/nginx_check.shnginx_check.sh内容如下
#!bin/bashA=`ps -C nginx --no-header |wc -l`if [ $A -eq 0 ];then #如果nginx没在运行 systemctl start nginx.service #启动nginx sleep 2 if [ `ps -C nginx --no-header |wc -l` -eq 0 ];then #如果无法启动killall keepalived #杀死keepalived进程 fifi设置开机启动
systemctl enable keepalived.service常用命令
#启动nginx服务systemctl start keepalived.service #停止服务systemctl stop keepalived.service #重新启动服务systemctl restart keepalived.service #查看服务当前状态systemctl status keepalived.service #设置开机自启动systemctl enable keepalived.service # 停止开机自启动systemctl disable keepalived.service添加系统定时任务
crontab -e#每天0时1分进行日志分割01 00 * * * /usr/share/nginx/logs/cut_nginx_log.sh新建cut_nginx_log.sh脚本
vim /usr/share/nginx/logs/cut_nginx_log.shchmod 755 /usr/share/nginx/logs/cut_nginx_log.shcut_nginx_log.sh内容如下
#!/bin/bash#每天00:00执行此脚本 将前一天的access.log重命名为access-xxxx-xx-xx.log格式,并重新打开日志文件#Nginx日志文件所在目录LOG_PATH=/usr/local/nginx/logs/#获取昨天的日期YESTERDAY=$(date -d "yesterday" +%Y-%m-%d)#删除文件的日期SEVENDAY=$(date --date="30 days ago" +%Y-%m-%d)#获取pid文件路径PID=/usr/local/nginx/logs/nginx.pid#分割日志mv ${LOG_PATH}access.log ${LOG_PATH}access-${YESTERDAY}.logmv ${LOG_PATH}error.log ${LOG_PATH}error-${YESTERDAY}.logrm ${LOG_PATH}access-${SEVENDAY}.logrm ${LOG_PATH}error-${SEVENDAY}.log#向Nginx主进程发送USR1信号,重新打开日志文件kill -USR1 `cat ${PID}`启动两台服务器上的nginx和keepalived
systemctl start nginx.servicesystemctl start keepalived.service在浏览器地址栏输入虚拟ip地址10.10.36.29
把主服务器(10.10.36.30) nginx和keealived停止,再输入虚拟ip地址10.10.36.29
systemctl stop keepalived.servicesystemctl stop nginx.service以上访问都成功则配置成功
1、可以购买阿里云或腾讯云上的服务器,然后通过添加安全组规则,允许或禁止安全组内的ECS实例对公网或私网的访问。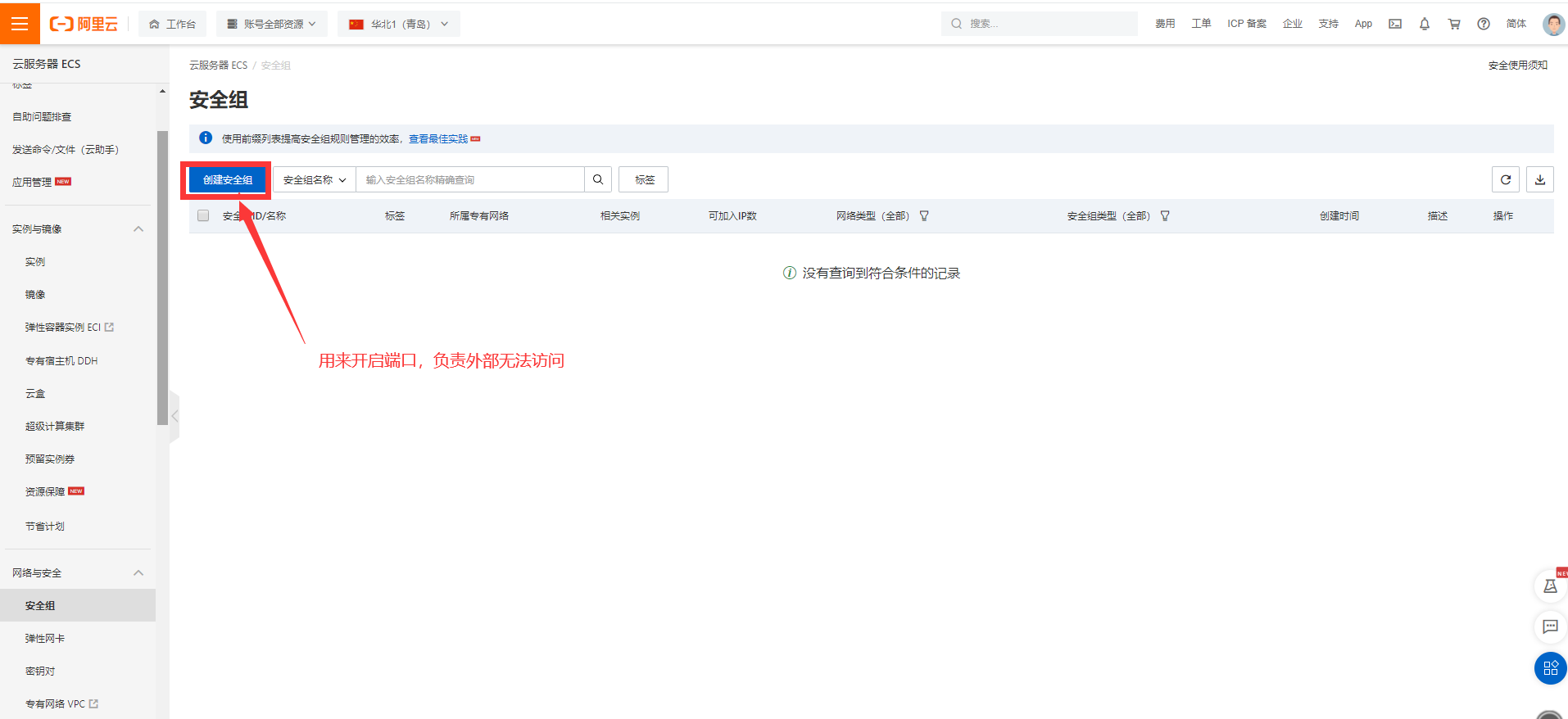
2、获取服务器的公网ip地址,修改实例名称和密码,修改后重启,使用xshell远程连接
yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh下载完毕后,得到宝塔管理面板的地址和账号密码
Halo后台是基于java11开发且运行的最低依赖要求为 JRE 11
sudo yum install java-11-openjdk -y这里用的是mysql5.7,直接在宝塔软件商店安装
然后在宝塔数据库添加数据库,在安全页面放行数据库的端口(默认3306),同时在阿里云或腾讯云安全组规则中放行3306端口
1、创建用户
useradd -m halousermod -aG wheel halopasswd halosu - halo2、下载Halo项目运行包
mkdir /app && cd /appwget https://dl.halo.run/release/halo-1.4.17.jar -O halo.jarmkdir ~/.halo && cd ~/.halowget https://dl.halo.run/config/application-template.yaml -O ./application.yaml3、修改配置文件
修改刚才下载的application.yaml文件
修改其中的数据库信息
4、使用Supervisor托管Halo进程
在宝塔软件商店安装Supervisor,点击设置,添加守护进程”,其中启动命令是 java -server -Xms256m -Xmx256m -jar halo.jar
5、开放Halo程序的默认端口号(8090)
与mysql一样
创建网站站点。在宝塔中选择网站模块,添加站点。进入设置页面点击反向代理,点击添加反向代理,返回网站站点页面,将站点配置为默认站点
浏览器中输入服务器的IP地址,进入Halo向导页面,根据自己的需求,填写相关的信息。安装后,进入网站的后台管理页面,即可以设置自己的网站外观,发布和管理自己的博客了。网站后台管理地址——IP地址/admin
]]>